【 TiDB 使用环境】生产环境
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】
pd和tidb,dm的worker还有cdc都部署在一起,dm有一个任务的source在这个ip上
【附件:截图/日志/监控】
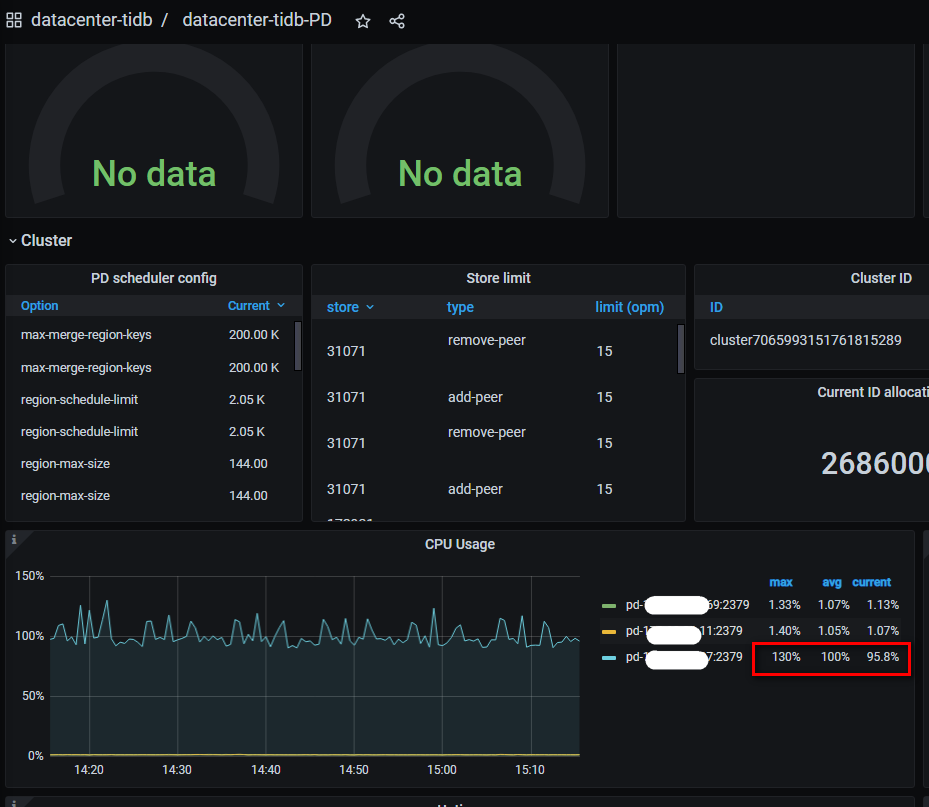
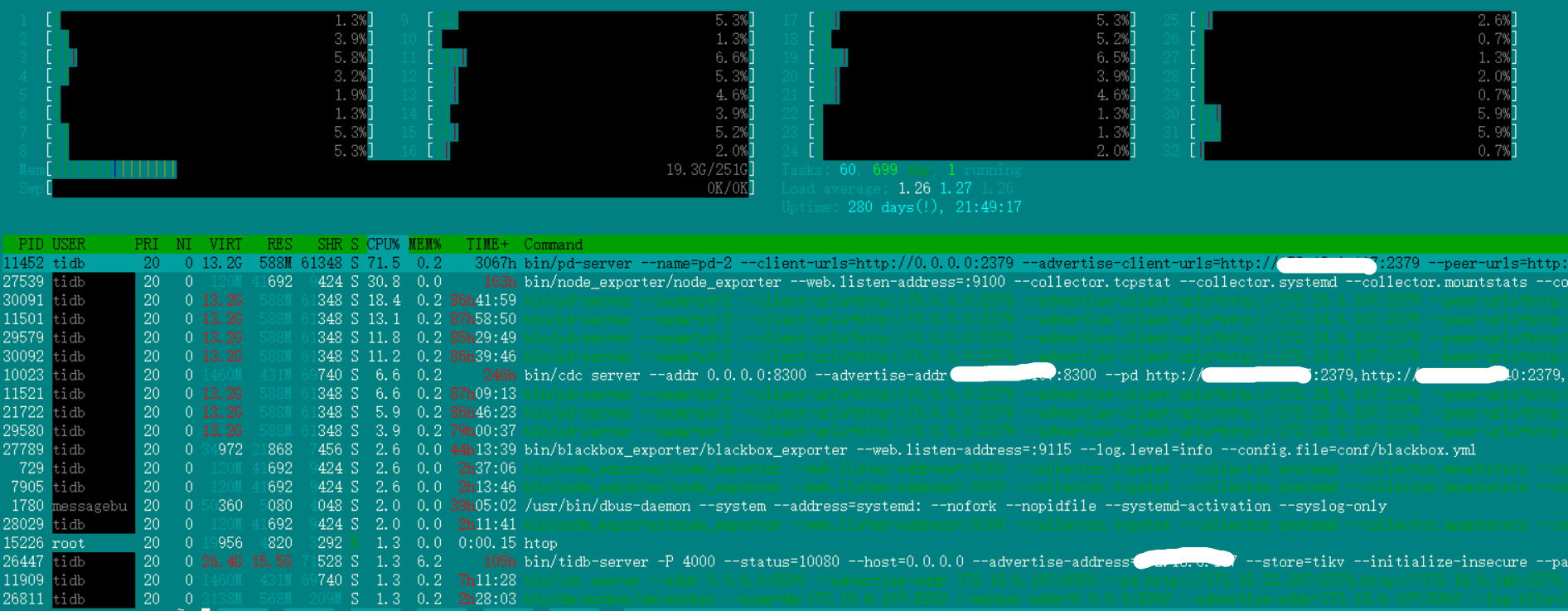
集群中会有:
[2023/04/11 08:43:52.845 +08:00] [WARN] [pd.go:99] [“get timestamp too slow”] [“cost time”=163.587758ms]
[2023/04/11 15:49:35.916 +08:00] [WARN] [pd.go:99] [“get timestamp too slow”] [“cost time”=175.792499ms]
[2023/04/11 16:22:15.079 +08:00] [WARN] [pd.go:99] [“get timestamp too slow”] [“cost time”=167.28991ms]
[2023/04/11 16:31:47.103 +08:00] [WARN] [pd.go:234] [“get timestamp too slow”] [“cost time”=142.124023ms]
[2023/04/11 17:02:24.281 +08:00] [WARN] [pd.go:99] [“get timestamp too slow”] [“cost time”=171.315344ms]
[2023/04/11 18:10:14.655 +08:00] [WARN] [pd.go:99] [“get timestamp too slow”] [“cost time”=222.338775ms]
怀疑是这个pd导致的
