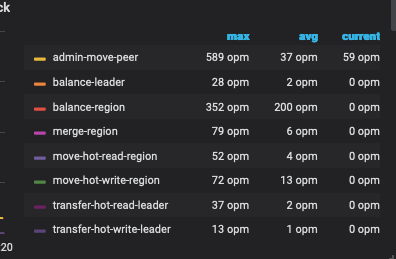
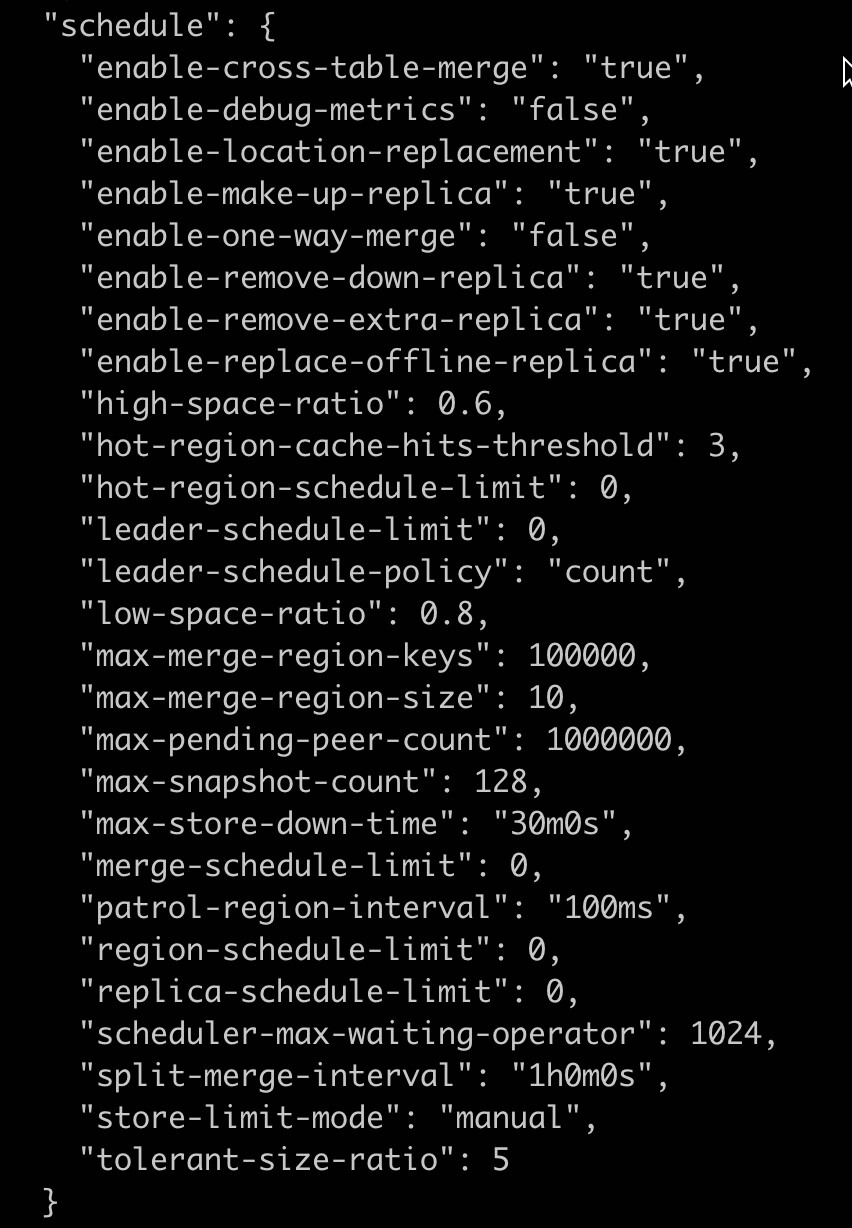
config set leader-schedule-limit xxx
config set region-schedule-limit xxx
config set replica-schedule-limit xxx
config set max-snapshot-count xxx
config set max-pending-peer-count xxx
store limit xx xxx add-peer
生产环境建议慢慢跑就是了,测试环境可以根据需要调整下
此外,还可以通过调整 TiKV 集群的 raftstore.store-pool-size 参数,以增加 store 线程池的大小,从而提高 store 的并发度。同时,还可以通过调整 TiKV 集群的 raftstore.store-pool-queue-capacity 参数,以增加 store 线程池的队列容量,从而减少 store 线程池的阻塞等待时间。