【 TiDB 使用环境】测试
【 TiDB 版本】4.0.4
【复现路径】做过哪些操作出现的问题
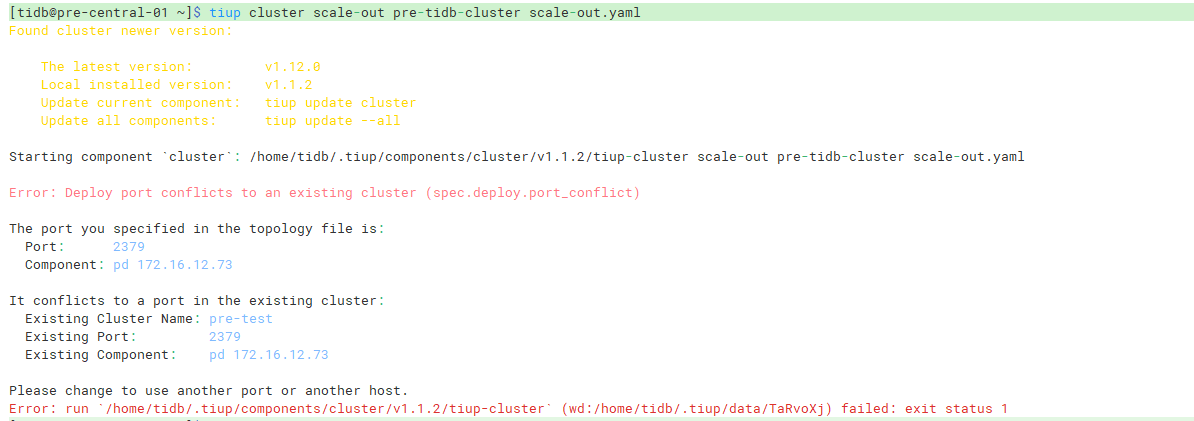
tiup cluster scale-out 命令提示完全不相关的端口冲突
【遇到的问题:问题现象及影响】
目前drainer遇到内存瓶颈,打算迁移机器,就先使用了tiup cluster stop pre-tidb-cluster -N 停止了当前集群的现有的唯一一个drainer,打算scale-out扩容一个然后再用scale-in删掉这个性能不足的drainer
然后编写了scale-out.yaml
drainer_servers:
- host: 172.16.12.165
# user: "tidb"
port: 8249
ssh_port: 40022
deploy_dir: "/alidata/tidb/deploy"
data_dir: "data"
config:
syncer.db-type: "kafka"
syncer.to.kafka-addrs: "***:9092,****:9092,****:9092"
syncer.to.kafka-version: "1.0.2"
syncer.to.kafka-max-messages: 1536
syncer.to.kafka-max-message-size: 1610612736
syncer.to.topic-name: "tidb-binlog-pre"
使用命令tiup cluster scale-out pre-tidb-cluster scale-out.yaml,然后报错端口冲突,但是报错的IP和端口跟我要扩容的drainer完全不相关,并且集群名也不同,新drainer主机上也没有任何端口在监听
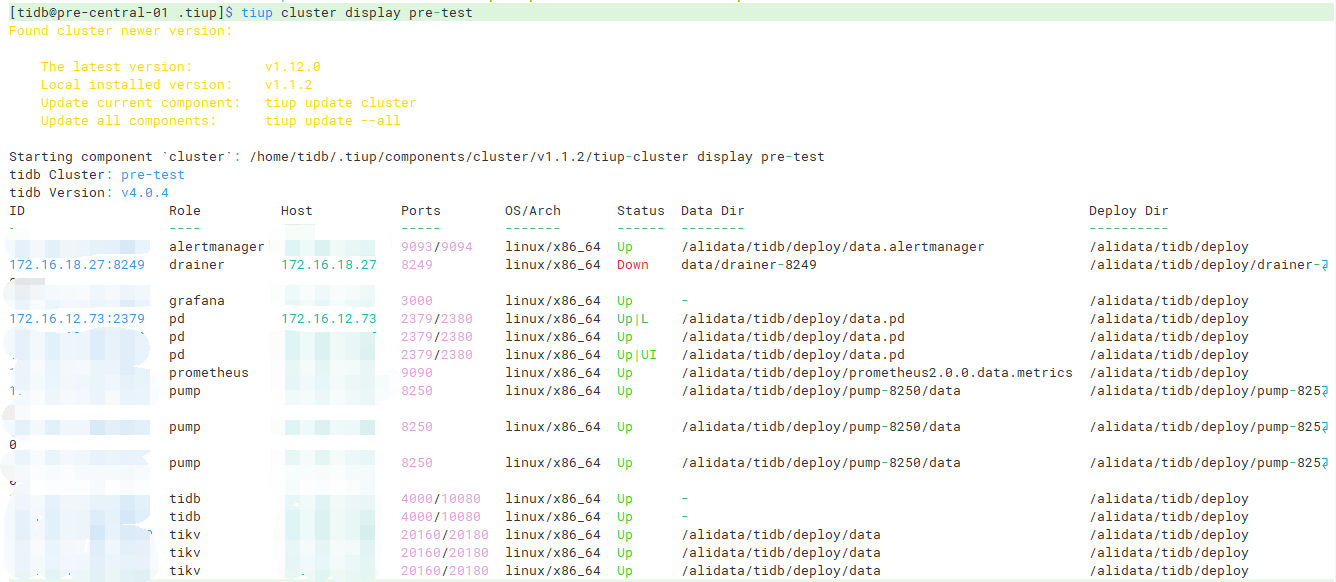
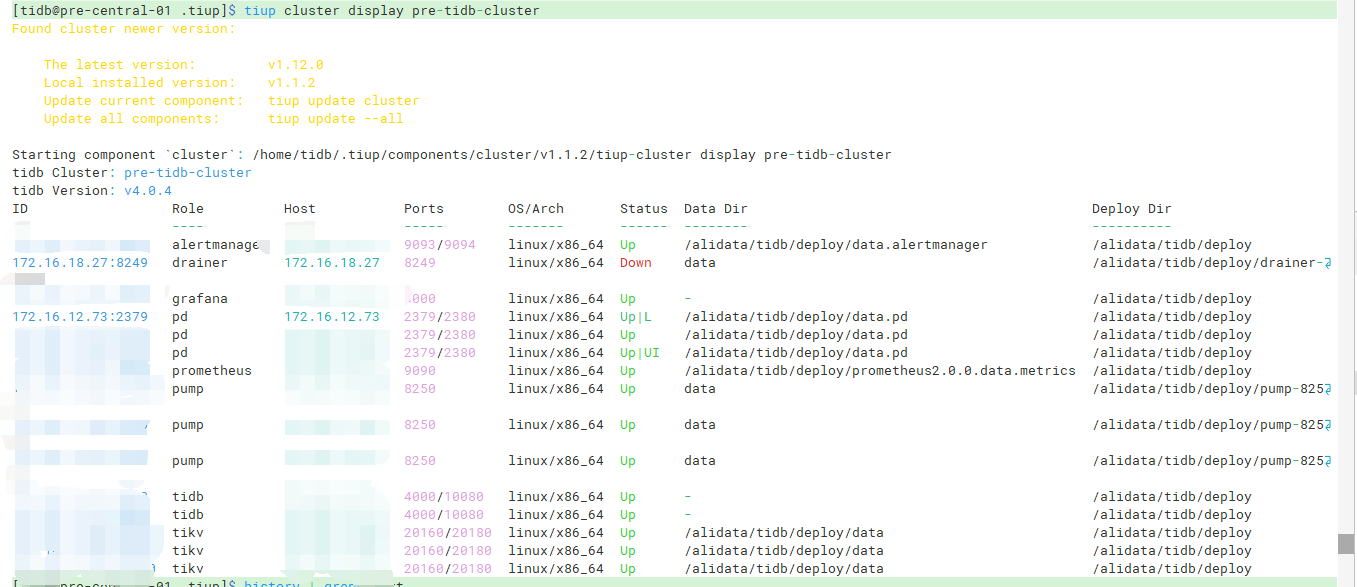
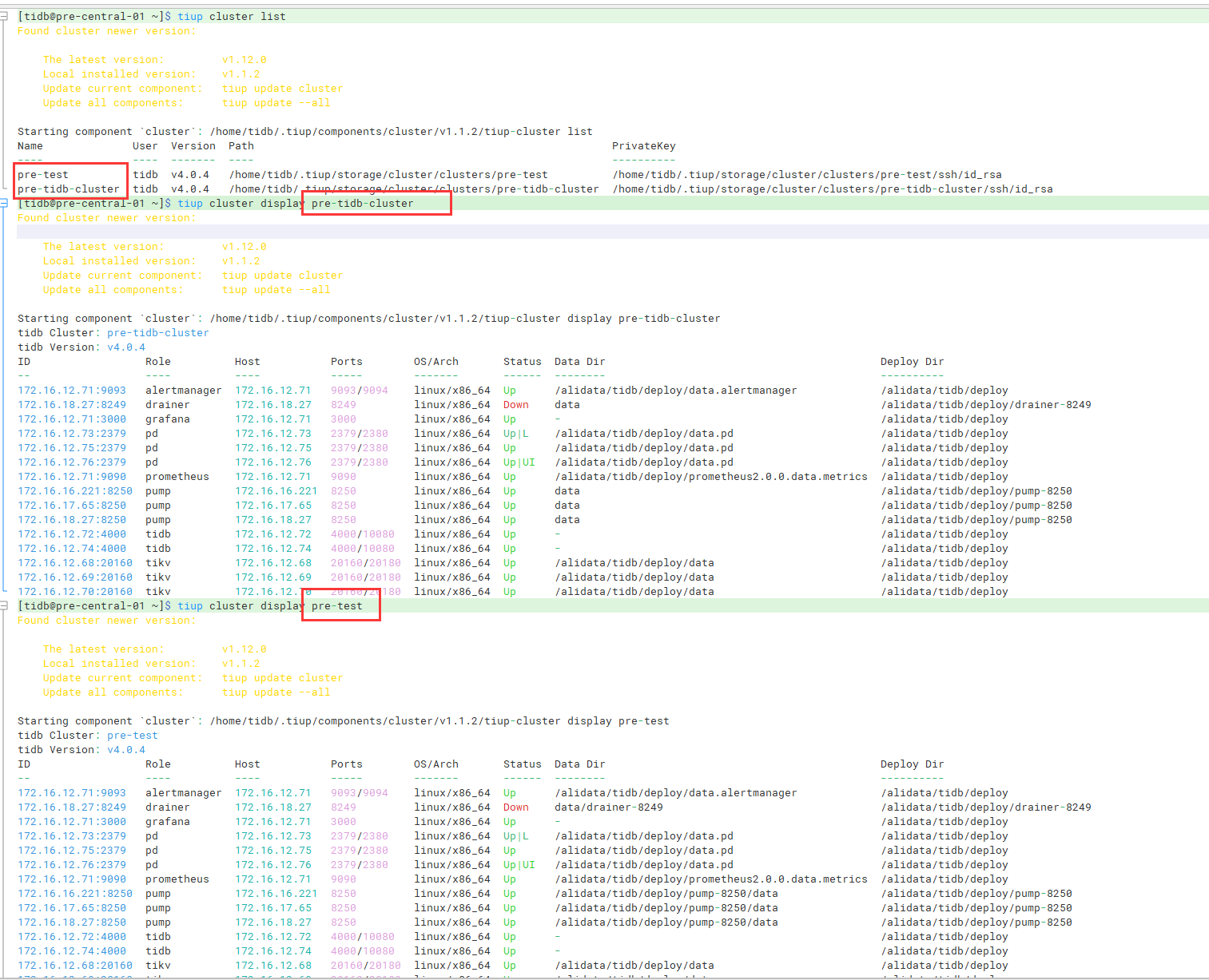
这个集群并不是我创建的,通过cluster list看到有两个集群
查看两个集群,发现一模一样,有点头晕
pre-test:
pre-tidb-cluster:
现在不知道该咋办了,生怕覆盖了什么东西,也不知道这俩集群名为什么查出来的东西一样
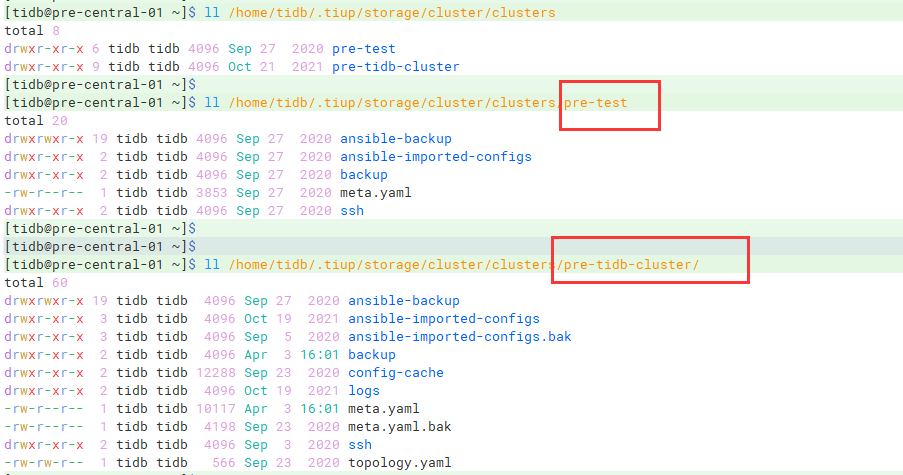
/home/tidb/.tiup/storage/cluster/clusters这个目录下有两个文件夹,然后除了名字不一样,其他都一样?
是的,我要操作的是pre-tidb-cluster集群
俩集群display出来的信息一模一样,地址端口状态,都是一样的
我感觉可以删掉一个,保留一个即可,不过要确认,这俩是一模一样的
现在就是疑惑为什么会报错提示的端口主机和我要扩容的新机器完全不相关,
是否可以通过修改什么配置来忽略掉这个报错
12.73 2379/2380是Pd 的,两个集群都有3个pd节点,你把测试集群扩容一个pd节点后把12.73这个节点缩容掉吧。18.27节点是 TiDB 的 Binlog工具Drainer ,数据目录不一样,现在是down状态,根据业务情况考虑删除还是重建吧。
抱歉我可能没说清楚。这俩集群所拥有的所有tidb组件都是一模一样的,也就是说12.73 2379/2380这个pd同时被两个集群录入了
如果我缩容掉pre-test集群的这个pd,那这个pd就会被实体删掉, pre-tidb-cluster集群也势必会失去这个节点啊
我感觉就算迁走了这个pd,他也会继续报错其他组件的端口被占用的,会不会是什么地方导致tiup cluster误判了
是指当初建立集群用的文件吗?由于集群不是我建立的,我已经找不到了,请问有什么办法可以找到并修改吗
建议将我所说的两个文件夹,确定是一样的之后,移走一个,然后通过剩下那个集群名称,指定扩缩容,看一下还是否有问题
感谢,我这边mv掉一个集群的文件夹就可以了,但是比较奇怪的是,现在俩drainer都不往kafka写数据,日志中也没什么报错,只有一行行的write save point
偶尔会打印一行
[INFO] [client.go:716] [“[sarama] Client background metadata update:kafka: no specific topics to update metadata”]
小王同学Plus
(小王同学 Plus)
18
这通常是 Kafka 集群在正常运行时的正常日志记录之一,不需要特别处理。这个错误信息表明 Kafka 集群没有收到需要更新元数据的请求,因此没有执行任何操作。
check 的时候不仅仅会对比新机器的冲突,也会对现有集群进行 check,这个情况我怀疑是你们以前做了下 meta.yaml 的备份导致的