【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.0
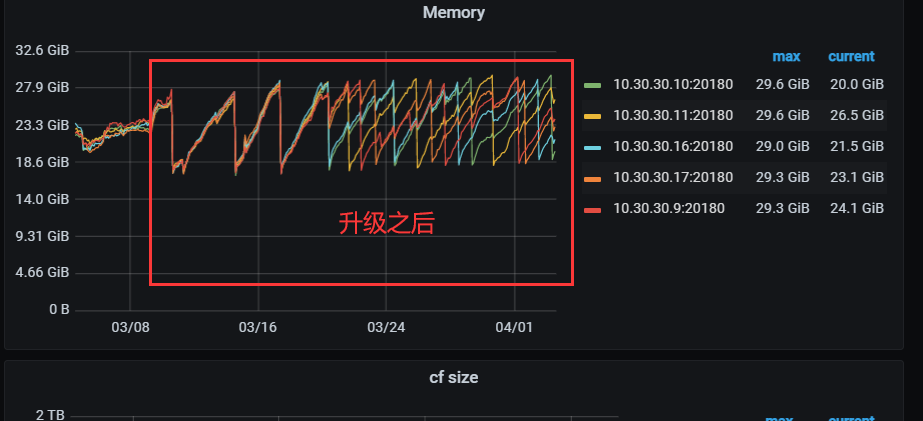
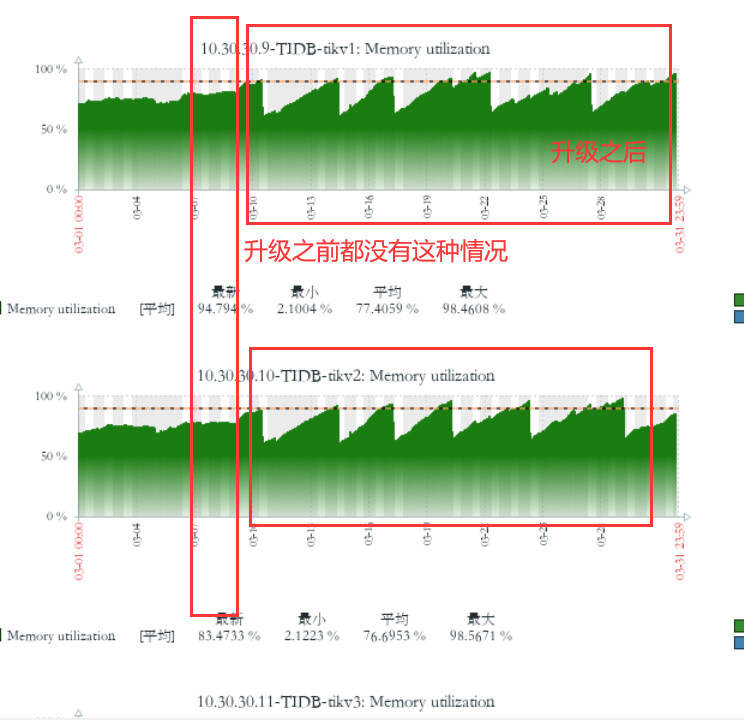
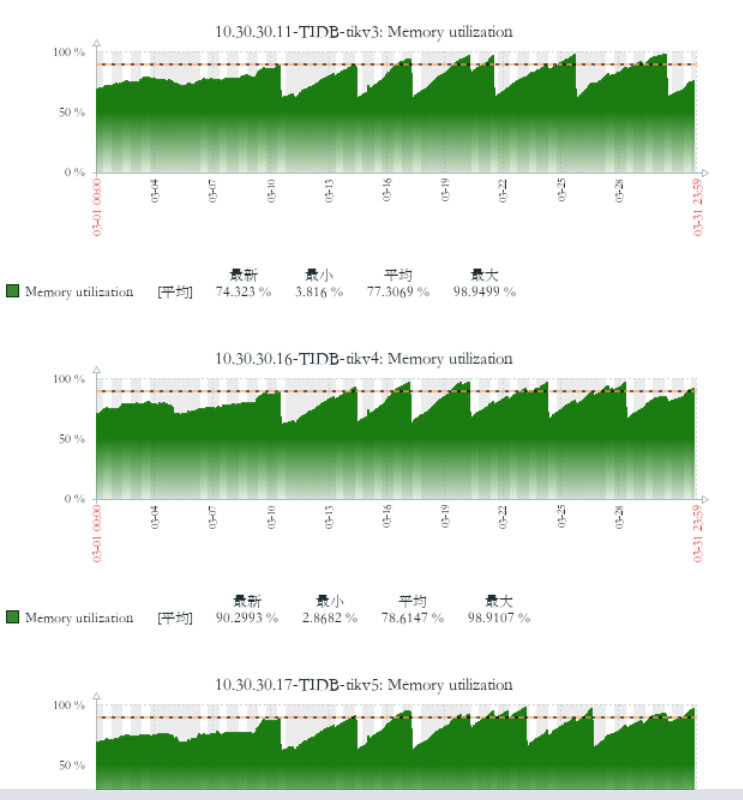
【复现路径】之前是v5.2.1 版本 升级到v6.5.0 之后tikv 节点内存不停的增长,直到oom 被系统kill,又重复上面的过程
【遇到的问题:问题现象及影响】
之前是v5.2.1 版本 升级到v6.5.0 之后tikv 节点内存不停的增长,直到oom 被系统kill,又重复上面的过程
【资源配置】
【附件:截图/日志/监控】
tidb-dashboard
zabbix 监控
默认关闭了THP
调整gc_life_time 从24h 到2h 没用
都是默认参数,只有tidb 节点设置了些内存控制相关的参数
tikv 内存参数优化也看了,
shared=true 默认
rockdb storage.block-cache.capacity 默认
tidb 自己计算的 总内存32G 算出来14.4G 应该是32*45%
write_buffer_size 128M 默认值
db_user
(Db User)
2
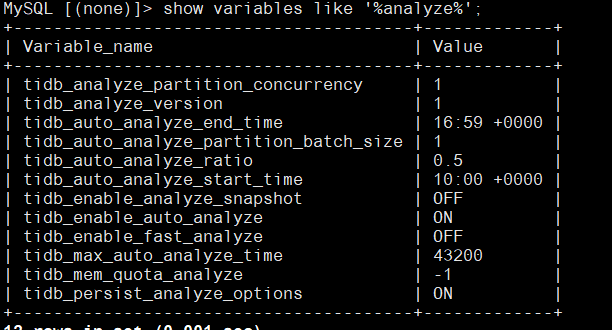
看下analyze相关配置,看下analyze的执行状态
show variables like ‘%analyze%’;
show analyze status;
dashboard看下这段时间是否有大量慢查询
db_user
(Db User)
4
看起来analyze没什么问题,可以看下慢日志,可能因为升级导致某些语句的执行计划不对了,可以看看,内存飙升是什么语句导致的,可以从这些慢sql来测试,不同版本的优化器逻辑可能不一致,有些sql可能执行10几秒,但是对大表错误的用了hash join等也可能造成很大的内存消耗,可以看下内存飙升时间段的慢sql,逐条排查下
这个tidb 集群有很多插入数据任务(从tdengine 拉数据插入) 还有一些OLAP的任务 大部分慢sql 都是10s 以下 偶尔会有超过10s 的
tiup cluster display 都是正常的
mysql -uroot -p 连接 show processlist 都看过了 查询 insert update 一直都在执行 集群正常的,
关键是升级之前没问题的, 升级之后出问题了。
tikv节点内存OOM,一般只有两个情况会出现:
- tikv block cache设置太大
- coprocessor 从tikv获取的数据缓存在tikv 内存中比较快,grpc 将读取到的数据发往tidb-server 的速度比较慢,从而导致数据堆积出现OOM
针对上面两个情况,可以检查下 tikv block cache参数是否合理。
如果上述参数合理,那就排查下此时集群的访问SQL,可以通过dashboard查看,或者登录机器在tidb-server中找到慢查询日志、以及在tidb.log 里grep 出 expensive query,大部分情况下都会找到对应的SQL
然后看看对应的SQL的执行计划,分析看是什么问题再找对应的处理策略
这个具体要怎么操作? 我也想看看具体是什么比较多 除了block-cache write-buffer 执行计划cached 等等 这个库replace 的更新比较多
Tidb 节点没有OOM tikv 节点不停的oom
curl http://127.0.0.1:10080/debug/zip --output tidb_debug.zip 这个是不是分析的是tidb 节点的?
db_user
(Db User)
16
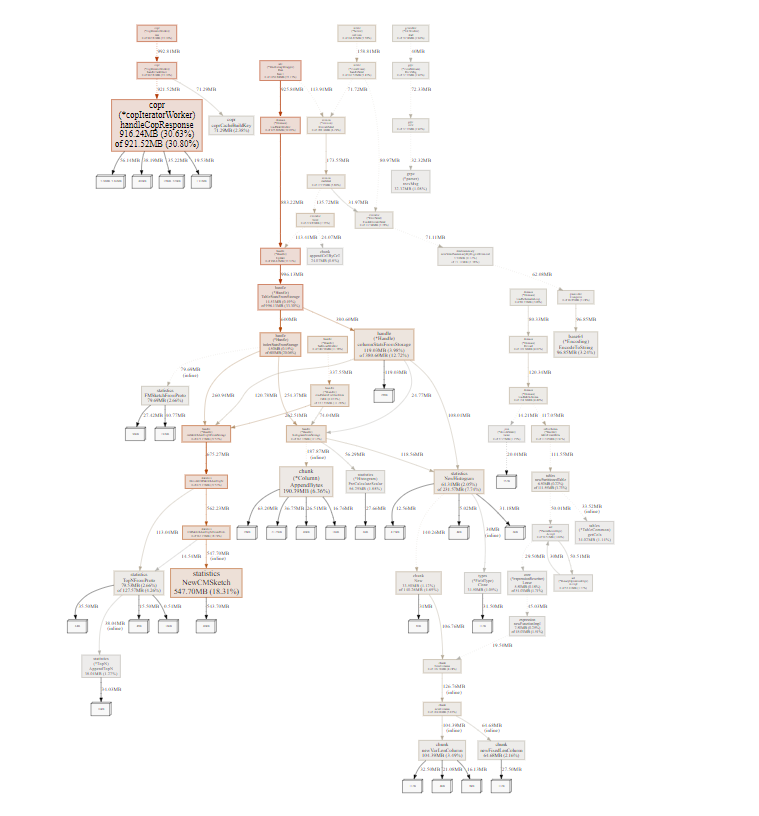
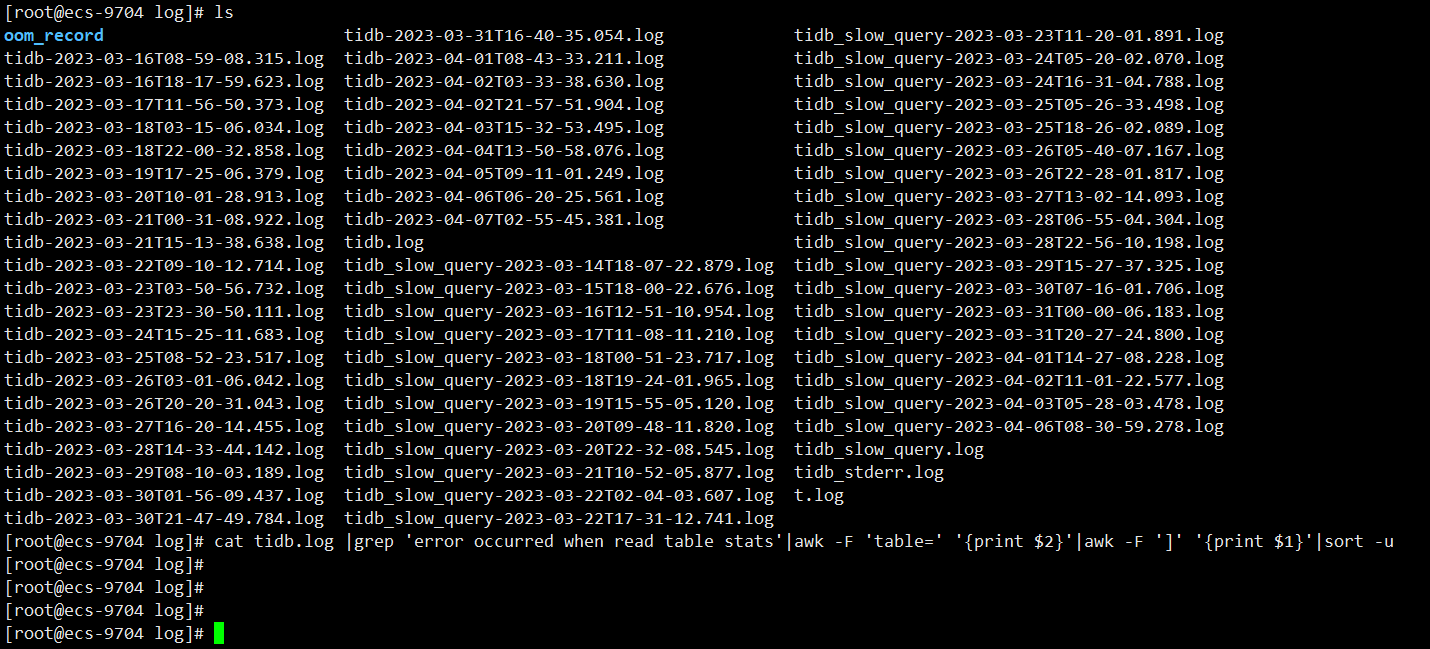
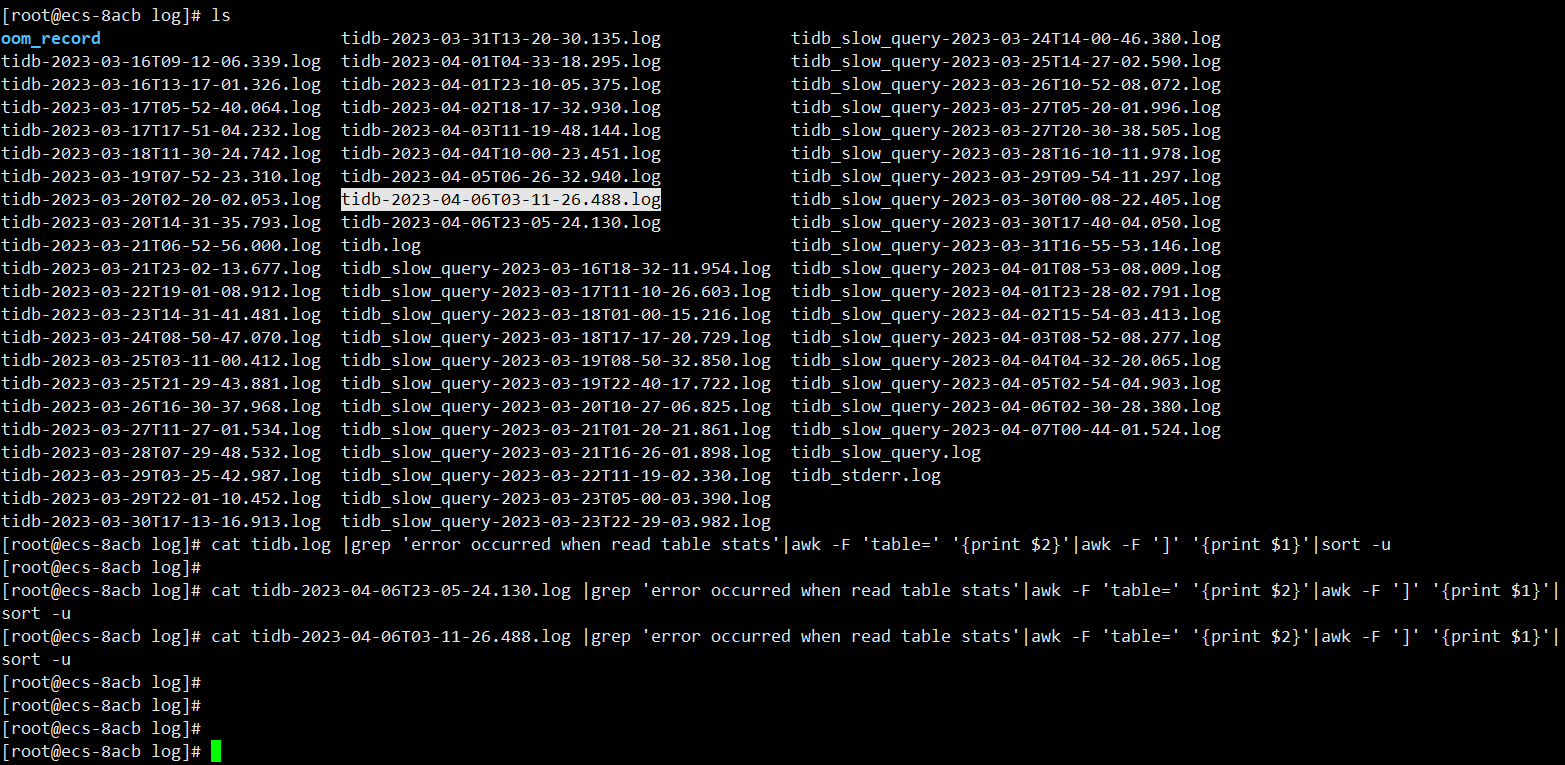
貌似知道什么情况了,在几台tidb上执行下面的操作,看下日志
cat tidb.log |grep ‘error occurred when read table stats’|awk -F ‘table=’ ‘{print $2}’|awk -F ‘]’ ‘{print $1}’|sort -u
如果不出意外的话会有一些表,这些表是因为data too long的bug导致统计信息无法统计,如果是这个问题的话按照下面的操作来解决
analyze bug.
第一个节点tidb.log 没有
第而个节点tidb.log 没有
tidb.log 里面的ERROR 日志 也不是很多
下面这种WARN 倒是比较多 云上SLB 后面的一堆机器连接被重置 架构SLB 后面连接的tidb 节点 他这个SLB 后面一堆机器(对用户是透明的 用户无法看到这些机器 无法连接这些机器) 再连接tidb 的
db_user
(Db User)
18
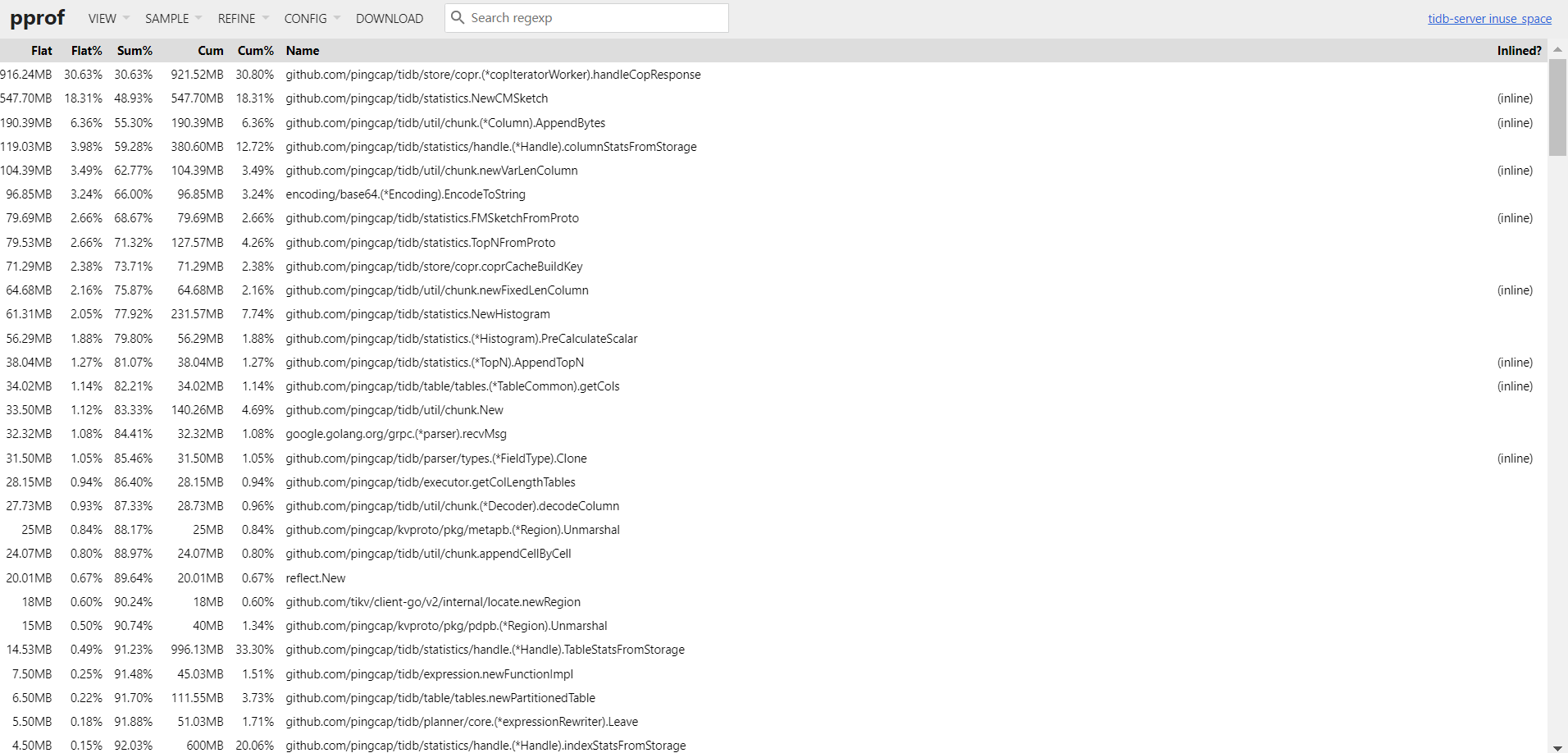
那可能不是这个,不过看你的诊断数据显示也是stats阶段占用多,像是analyze的影响,挺奇怪的
就是有几个大表 500G 一个 300G一个 100G 你说的stats 占用多可能和这个有关系 ,后面看看关闭收集统计信息 内存能不能回收回来