【 TiDB 使用环境】测试/ Poc
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】
【附件:截图/日志/监控】
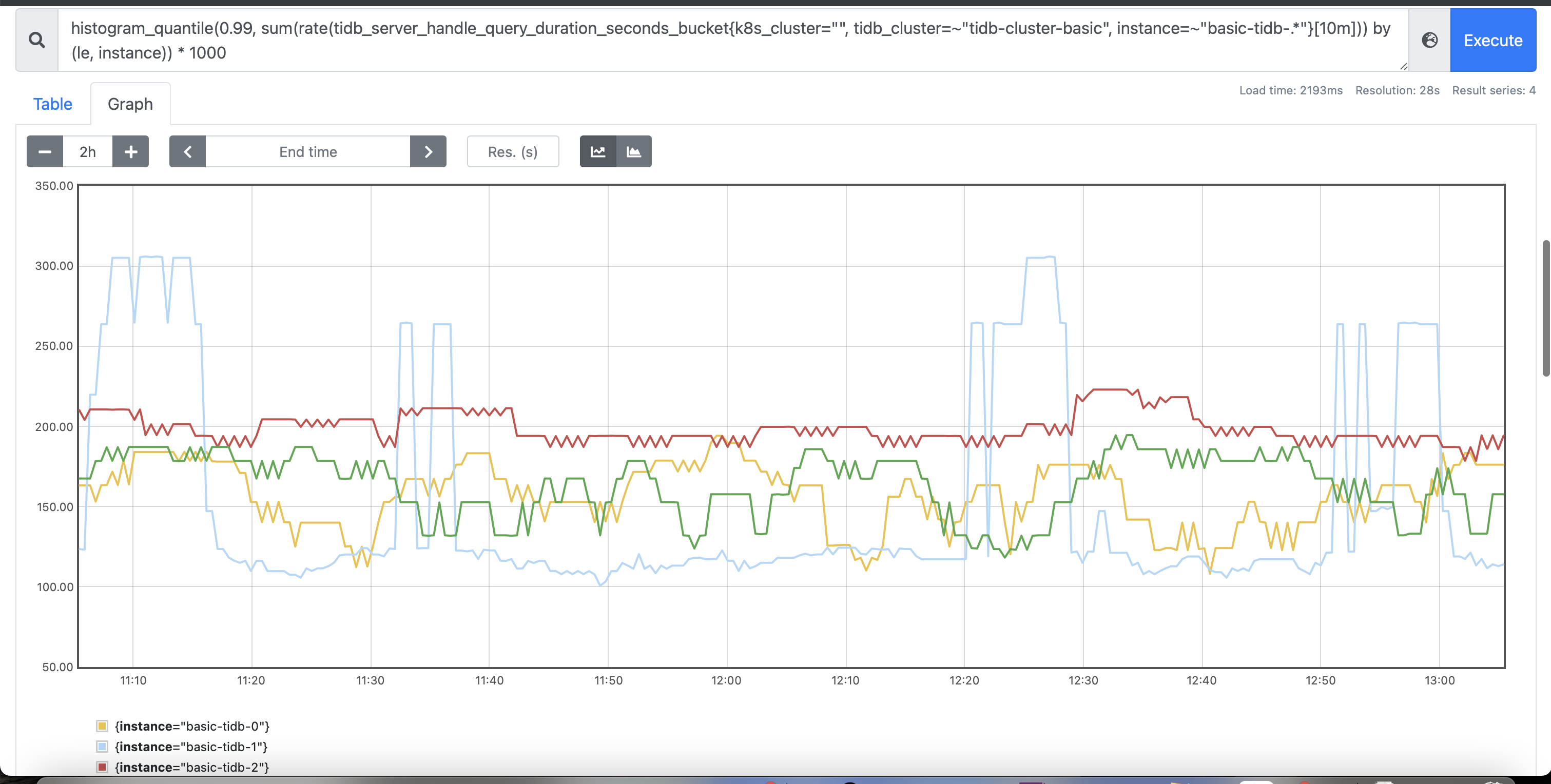
P1: Prometheus 查询 tidb pod的p99延时图:
疑问,目前是空负载,为什么延时还能飙到200ms左右啊? 理论上不应该是0ms嘛?
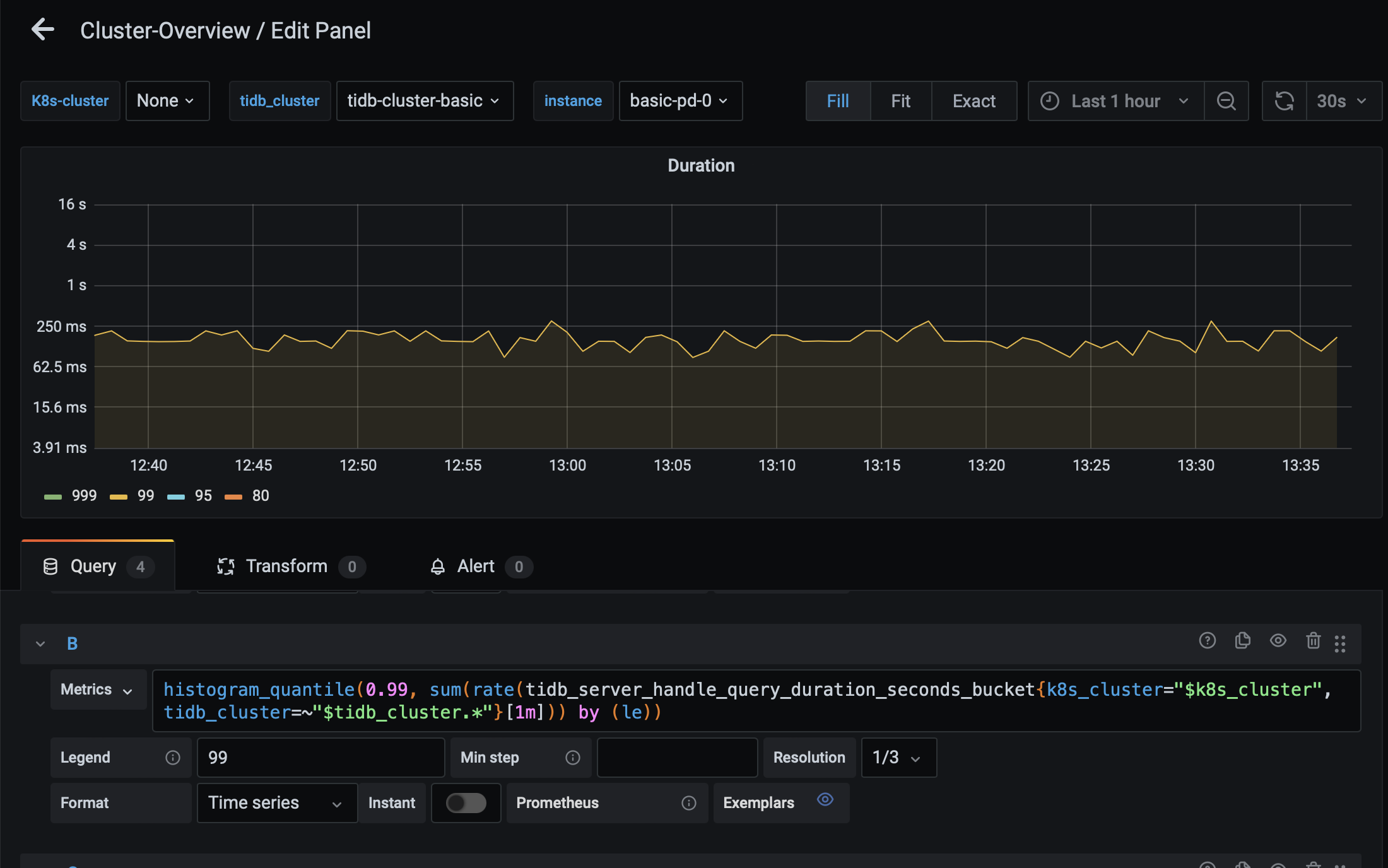
P2: Granafa的Cluster-Overview下的 tidb pod的p99延时图
这个看起来把多个pod的p99延时曲线合成一条了,疑问,目前是空负载,但延时也是在200多ms? 理论上不也应该是0ms嘛?
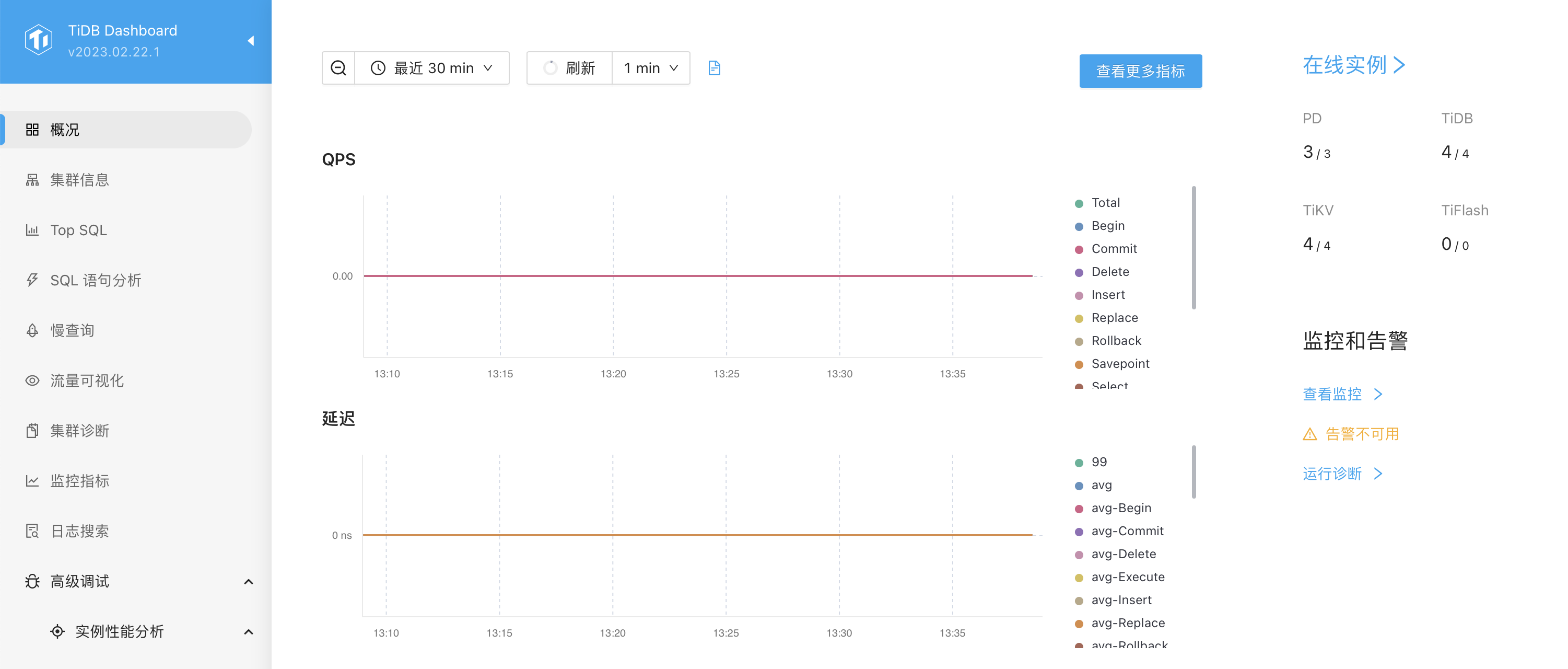
P3: Dashboard 控制面板的p99延时图
这个看起来很正常,目前是空负载,他的延时曲线也是0ms,是符合理论情况的。
有没有大神能解释一下这三个之间的区别阿?
我想通过写代码的方式拿到 P3 的延时数据请问该怎么写啊?
WalterWj
(王军 - PingCAP)
2
集群有内部 SQL,看看能不能过滤掉。估计是受到这个影响
那请问可以直接通过代码从dashboard拿到数据吗?
你空集群再进入dashboard查询时也用了tidb 而且dashboard上页面上的sql的基本就是慢sql
那dashboard的延时确实有负载的时候才会出现,我觉得很难过滤掉集群内部sql来拿到真实的业务sql延时吧?
从dashboard拿数据就是直接从prometheus拿数据,通过promql访问prometheus的API就可以了
至于说如何过滤掉集群内部SQL的延迟来获取真实业务延迟,这个需求在真实业务场景里必要性不高,而集群内部的SQL通常占比较少,当业务繁忙时P99/P999就能很好地展示当前的延时状况了
我目前要做的课题,受尾延时影响很大。所以这个数据噪声必须要清理掉。我的P1就是通过promql访问prometheus的API。要是写进代码也是写那条promql查询语句。请问大佬有没有更好的方法拿到dashboard那样的数据?又或者说大佬知不知道dashboard从prometheus拿数据的promql是什么?
可以在详细一点嘛  ,目前实在太小白了,初学TiDB。我目前是要基于TiDB做一个智能弹性伸缩系统,尾延时这项指标很重要。
,目前实在太小白了,初学TiDB。我目前是要基于TiDB做一个智能弹性伸缩系统,尾延时这项指标很重要。
histogram_quantile(0.99, sum(rate(tidb_server_handle_query_duration_seconds_bucket{k8s_cluster=“”, tidb_cluster=~“tidb-cluster-basic”, instance=~“basic-tidb-.*”,sql_type !=“internal”}[10m])) by (le, instance)) * 1000
请问是这样写嘛,看起来貌似可行?
system
(system)
关闭
13
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。