【 TiDB 使用环境】生产环境
【 TiDB 版本】v5.4.2
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
- 问题:1台物理机故障,机器频繁重启,我手动将这台物理机上面的leader驱除,然后stop这些store,目前副本也在重建中,怎么手动剔除这些down的节点
【资源配置】
【附件:截图/日志/监控】
【 TiDB 使用环境】生产环境
【 TiDB 版本】v5.4.2
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】
【附件:截图/日志/监控】
现在节点的状态是什么?
down,我现在需要把这些移除集群,需要设置手动设置为tombstone?
store的状态是在 pd 中是down,时间上已经超过了max-store-down-time 默认的30min,从监控看,集群已经开始在存活的store上补足各个region的副本
这些down节点上肯定有非leader region,怎么能把store从集群中剔除掉
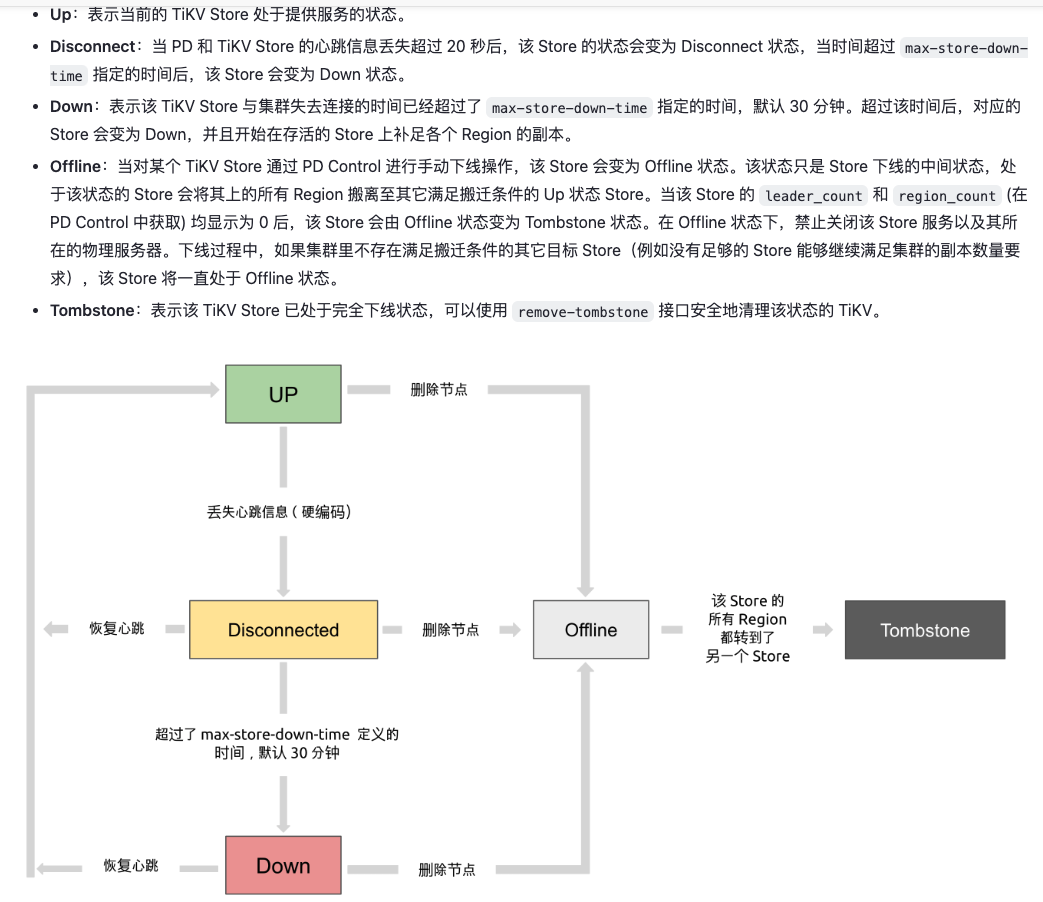
具体store的状态你可以参考这个
!!!!
你的length<3,别忘了还tiflash的副本
还是先pd ctl查看下要下线的节点,有没有region,在执行下线节点操作
单机多实例部署,按照官方,配置了labels
config:
server.labels:
host: host1
另外,down掉的store上,我并没有找到所有down副本数量大于正常副本数量的所有 region,以下结果为空
region --jq=".regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length as $total | map(if .==(4,5,918726) then . else empty end) | length>=$total-length) }"
至于4,5,918726这些宕掉的stone上,查到有副本的所有region
region --jq=".regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(any(.==(4,5,918726)))}"
以上:意思是需要将down掉store所有有副本的region,手动operator add remove-peer吗?
store信息
{
"store": {
"id": 4,
"address": "xxxxxx:port",
"labels": [
{
"key": "host",
"value": "host1"
}
],
"version": "5.4.2",
"status_address": "xxxxxx:port",
"git_hash": "0d22a1b74abbf54ae259b498f6584dd26365fed2",
"start_timestamp": 1680501021,
"deploy_path": "/home/tidb/tidb50/tidb-deploy/tikv2/bin",
"last_heartbeat": 1680500631931783705,
"state_name": "Down"
},
"status": {
"capacity": "1.431TiB",
"available": "358.4GiB",
"used_size": "982.8GiB",
"leader_count": 0,
"leader_weight": 1,
"leader_score": 0,
"leader_size": 0,
"region_count": 33682,
"region_weight": 1,
"region_score": 4512805.377294815,
"region_size": 2802845,
"slow_score": 1,
"start_ts": "2023-04-03T13:50:21+08:00",
"last_heartbeat_ts": "2023-04-03T13:43:51.931783705+08:00"
}
}
问题是这台物理机已经宕机,起不来了,在扩容新机器后补完region,在scale-in有用吗?
如大佬所言,按照正常的扩缩容方式解决问题👍
解决了就好 ![]()
![]()
![]()