【 TiDB 使用环境】测试
【 TiDB 版本】6.5
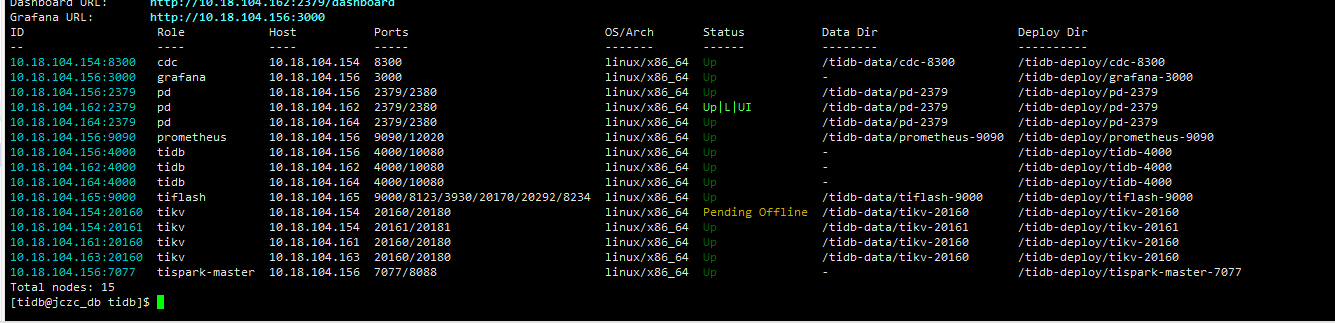
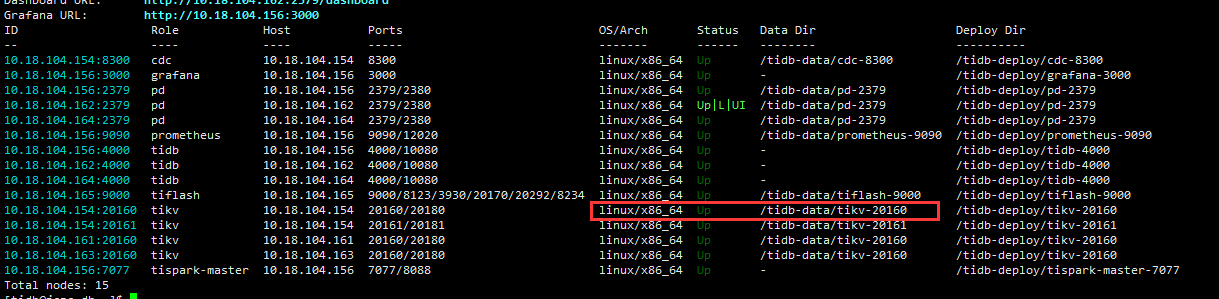
【复现路径】因磁盘损坏,本来三节点的tikv变成了两节点。后通过tiup cluster scale-in zdww-tidb --node 10.18.10.100:20160 --force 强制将tikv 进行移除。然后进行了缩容和扩容操作。为了降低异常,扩容节点配置,我使用了原有端口。后,我进行了 tiup cluster prune zdww-tidb 清理操作。
扩容后新的tikv节点一直处于 Offline状态。在进行启动时报以下异常
Error: failed to start tikv: failed to start: 10.18.10.100 tikv-20160.service, please check the instance’s log(/tidb-deploy/tikv-20160/log) for more detail.: timed out waiting for port 20160 to be started after 2m0s。
我查询tikv节点日志报:
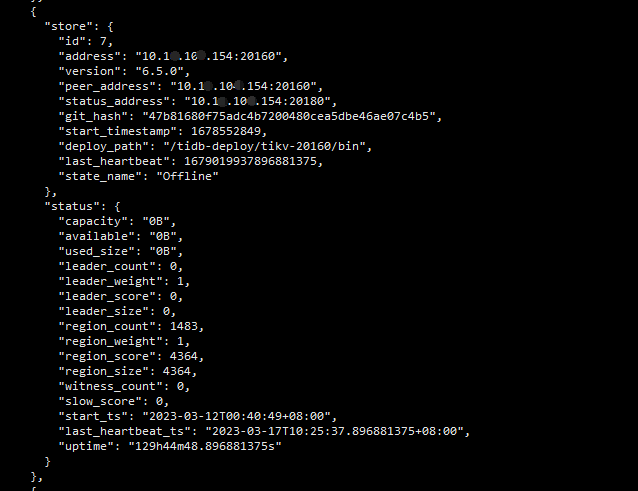
[2023/03/30 19:15:58.377 +08:00] [FATAL] [server.rs:1099] [“failed to start node: Other("[components/pd_client/src/util.rs:878]: duplicated store address: id:31001 address:\"10.18.10.100:20160\" version:\"6.5.0\" peer_address:\"10.18.10.100\" status_address:\"10.18.10.100:20180\" git_hash:\"47b81680f75adc4b7200480cea5dbe46ae07c4b5\" start_timestamp:1680174958 deploy_path:\"/tidb-deploy/tikv-20160/bin\" , already registered by id:7 address:\"10.18.10.100:20160\" state:Offline version:\"6.5.0\" peer_address:\"10.18.10.100:20160\" status_address:\"10.18.10.100:20180\" git_hash:\"47b81680f75adc4b7200480cea5dbe46ae07c4b5\" start_timestamp:1678552849 deploy_path:\"/tidb-deploy/tikv-20160/bin\" last_heartbeat:1679019937896881375 node_state:Removing ")”]
查看了许多帖子说是要对pd的缓存进行清理。
tiup ctl:v6.5.0 pd -u http://10.18.100.162:2379 store
tiup ctl:v6.5.0 pd -u 10.18.100.164:2379 -i
store delete 7
尝试了很多次都不成功,执行store delete 7无法删除,或者说已经更新成最新的了, 故向各位求教下怎么处理。
【遇到的问题:问题现象及影响】
tikv 一直处于 Offline 状态。
tikv 启动时报有 duplicated store address 异常。
另外求教三个问题:
1、如果pd存在缓存配置,我该怎么清理。
2、tikv不是三副本吗,如果一个节点被重新加入数据会自动从其他节点同步过来吗?
3、我想请教下tikv是组成集群被pd调用 ,还是pd对三个tikv分别进行调用。网上信息比较杂,能提供个易懂点的帖子吗。
主控节点状态
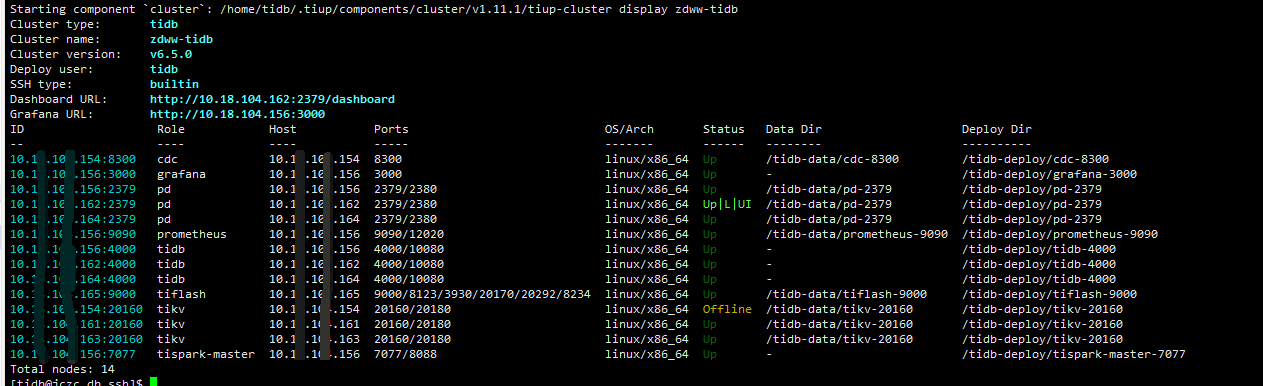
tikv报错
tiup ctl:v6.5.0 pd -u http://10.10.100.162:2379 store