【 TiDB 使用环境】生产环境
【 TiDB 版本】 4.0.10
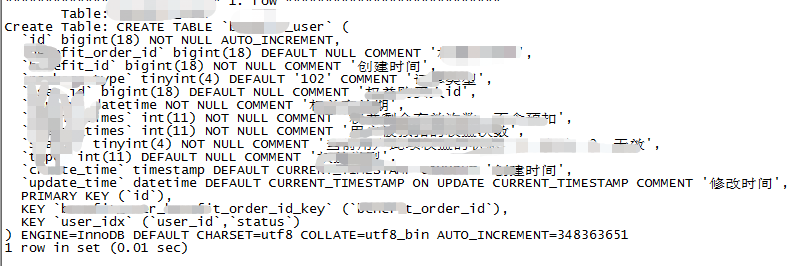
业务在对某张大表做数据迁移的时候,做的操作如下:
1. 查询A表某个时间段内的数据,limit 500,写到其他数据库中去。
2. 删除TiDB中刚才的500行记录。
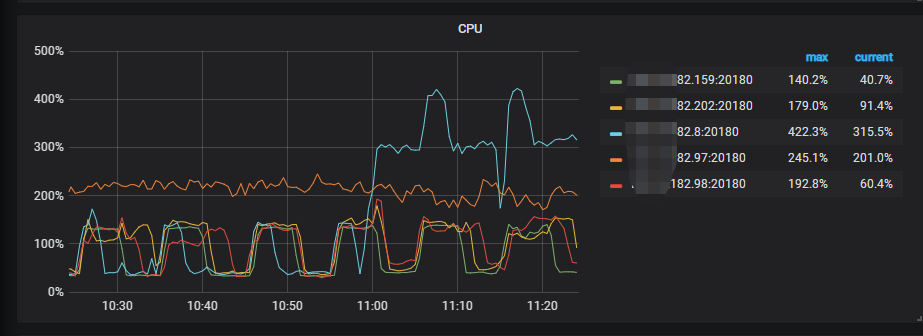
每次执行时间+停顿时间大约2秒左右,该表会产生大量的读热点,从监控上看,5个tikv节点中的某一个节点cpu会持续升高,其他4个节点并无明显变化,持续迁移几千万数据都这个样子。按理说某个表的数据leader不可能全部落在一个节点上吧。
【 TiDB 使用环境】生产环境
【 TiDB 版本】 4.0.10
业务在对某张大表做数据迁移的时候,做的操作如下:
1. 查询A表某个时间段内的数据,limit 500,写到其他数据库中去。
2. 删除TiDB中刚才的500行记录。
每次执行时间+停顿时间大约2秒左右,该表会产生大量的读热点,从监控上看,5个tikv节点中的某一个节点cpu会持续升高,其他4个节点并无明显变化,持续迁移几千万数据都这个样子。按理说某个表的数据leader不可能全部落在一个节点上吧。
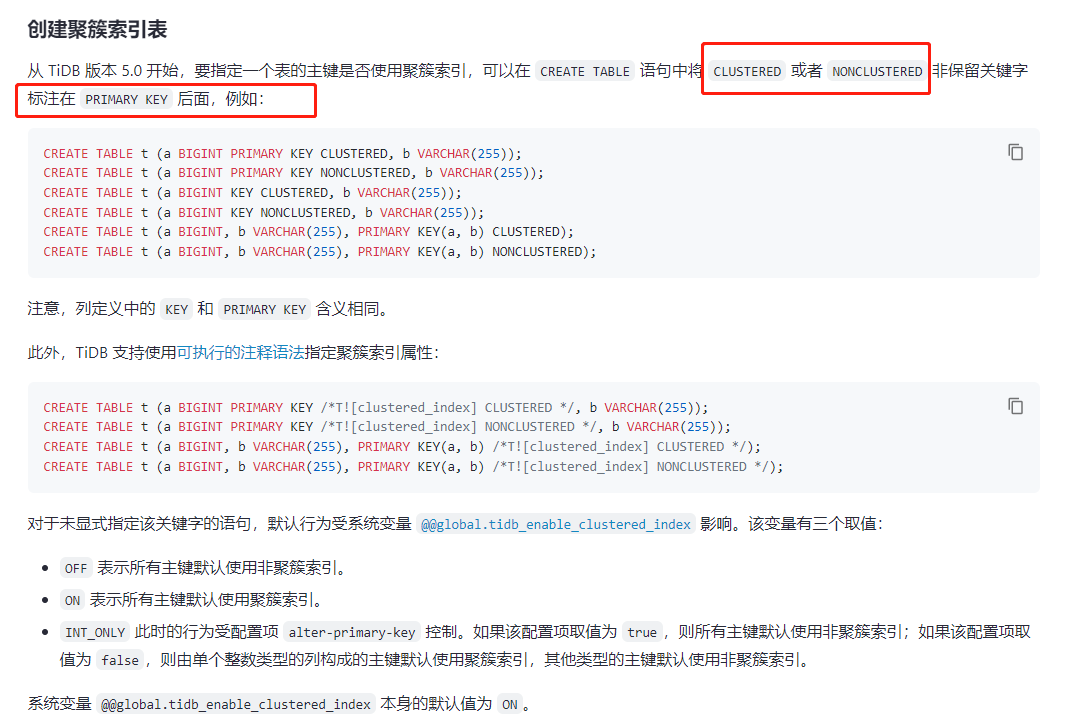
和region 的设定有关系,这个设定又和表结构有关,建议你去看下聚簇索引和非聚簇索引
https://docs.pingcap.com/zh/tidb/stable/dm-best-practices#是否使用聚簇索引
适应什么样的场景,都需要提前规划好
可以查询表对应的region是什么。你去看看。
https://docs.pingcap.com/zh/tidb/stable/sql-statement-show-table-regions#show-table-regions
SELECT b.DB_NAME,b.TABLE_NAME,b.INDEX_NAME,c.STORE_ID,a.ADDRESS,COUNT(b.REGION_ID) FROM INFORMATION_SCHEMA.TIKV_STORE_STATUS a ,INFORMATION_SCHEMA.TIKV_REGION_STATUS b,INFORMATION_SCHEMA.TIKV_REGION_PEERS c
WHERE a.STORE_ID=c.STORE_ID
AND b.REGION_ID=c.REGION_ID
AND c.IS_LEADER=‘1’
AND b.DB_NAME=‘sbtest’
AND b.TABLE_NAME=‘sbtest2’
GROUP BY b.DB_NAME,b.TABLE_NAME,b.INDEX_NAME,c.STORE_ID,a.ADDRESS
ORDER BY 1,2,3,4;
用这个sql查一下也行。
要解决问题的话,可以看看这个表相关的sql的执行计划,看看是不是有调优空间。
怎么个删除法?WHERE有索引没?
非常感谢
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。