【 TiDB 使用环境】生产环境
【 TiDB 版本】v5.4.0
【复现路径】暂无
【遇到的问题:问题现象及影响】
问题:
1.Tikv持续收到相关,无法消除【TiKV scheduler latch wait duration seconds more than 1s】、
【TiKV scheduler context total】
2. TIDB GC进程无法正常进行
3. client日志报 Tikv server is busy
个人排查结果:
当前集群昨天Juicefs 元数据集群,客户端只有Juicefs client,这些问题是在使用一段时间后出现的
我这边找官方相关告警处理,并没有找下符合我这边遇到的问题
【资源配置】
3台物理机,每个物理机2个NVME磁盘,每个机器部署了2个TIKV实例
【附件:截图/日志/监控】
===============================监控相关截图====================
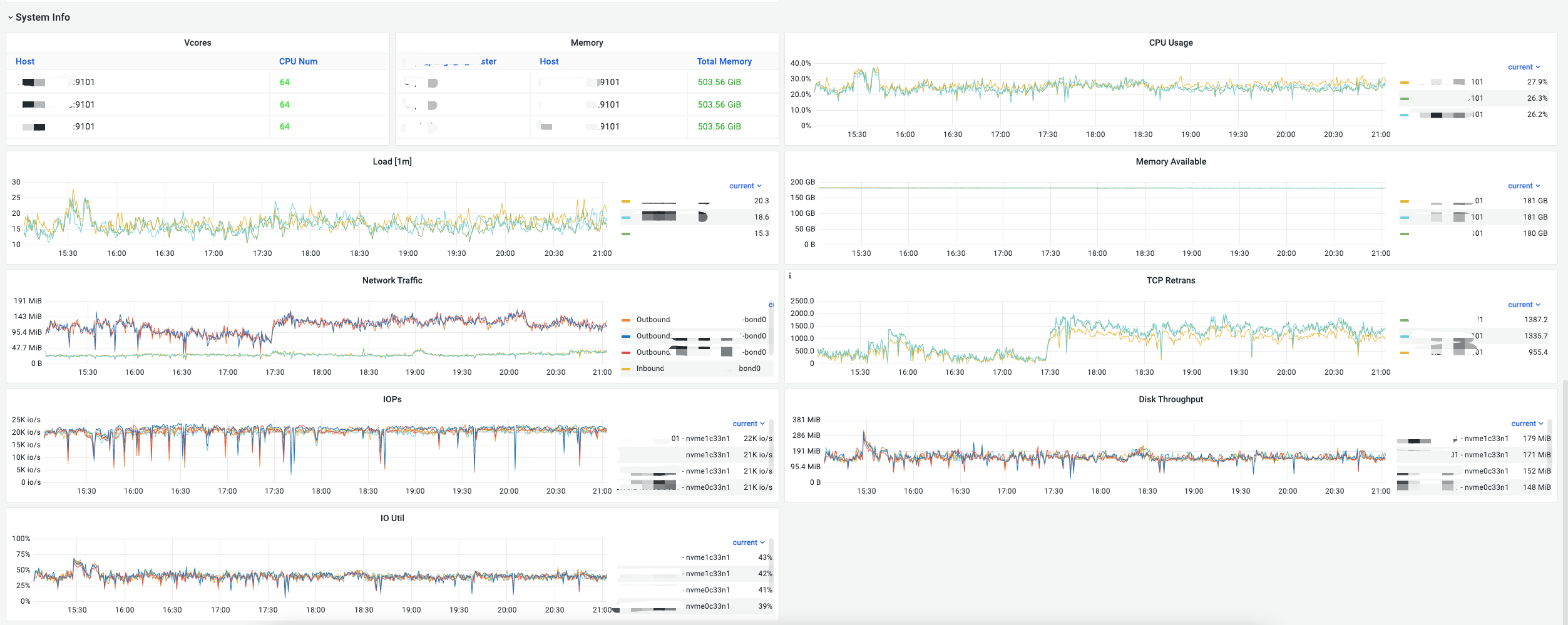
1.机器性能监控如下:
整体机器资源使用率并不高
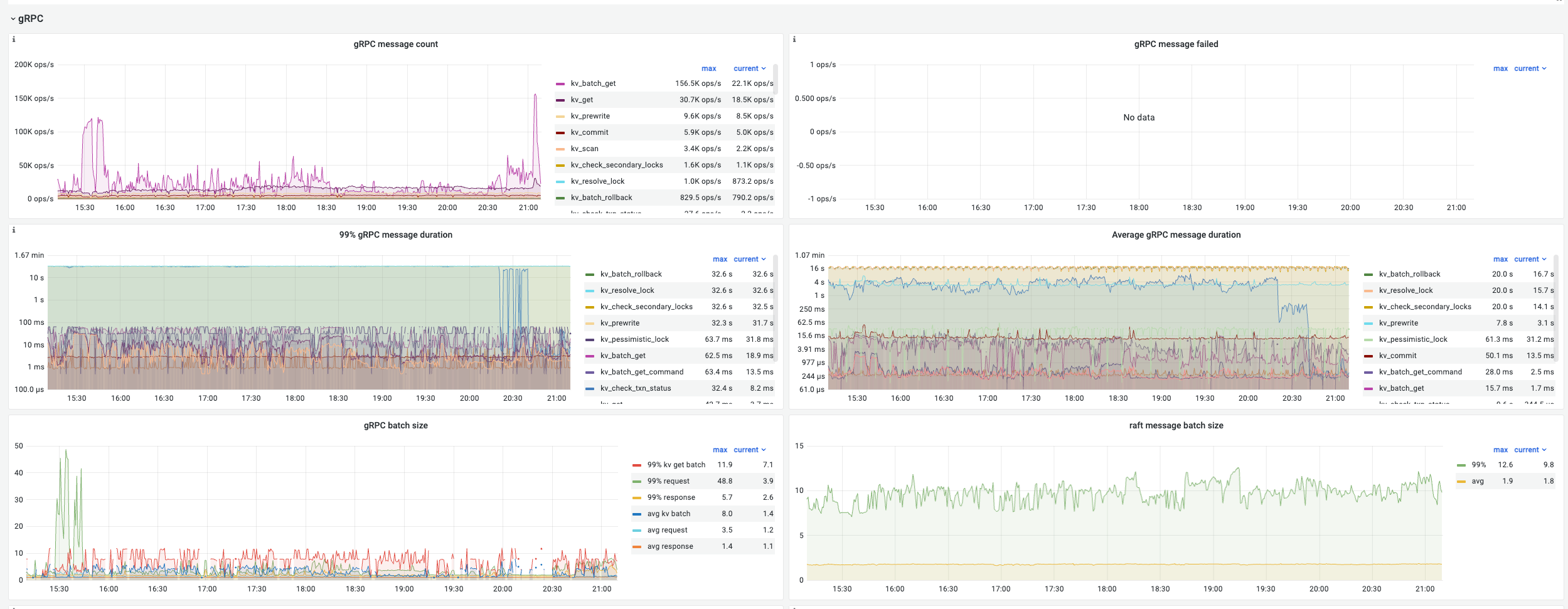
2.gRPC相关监控
各种锁持续的时间非常长
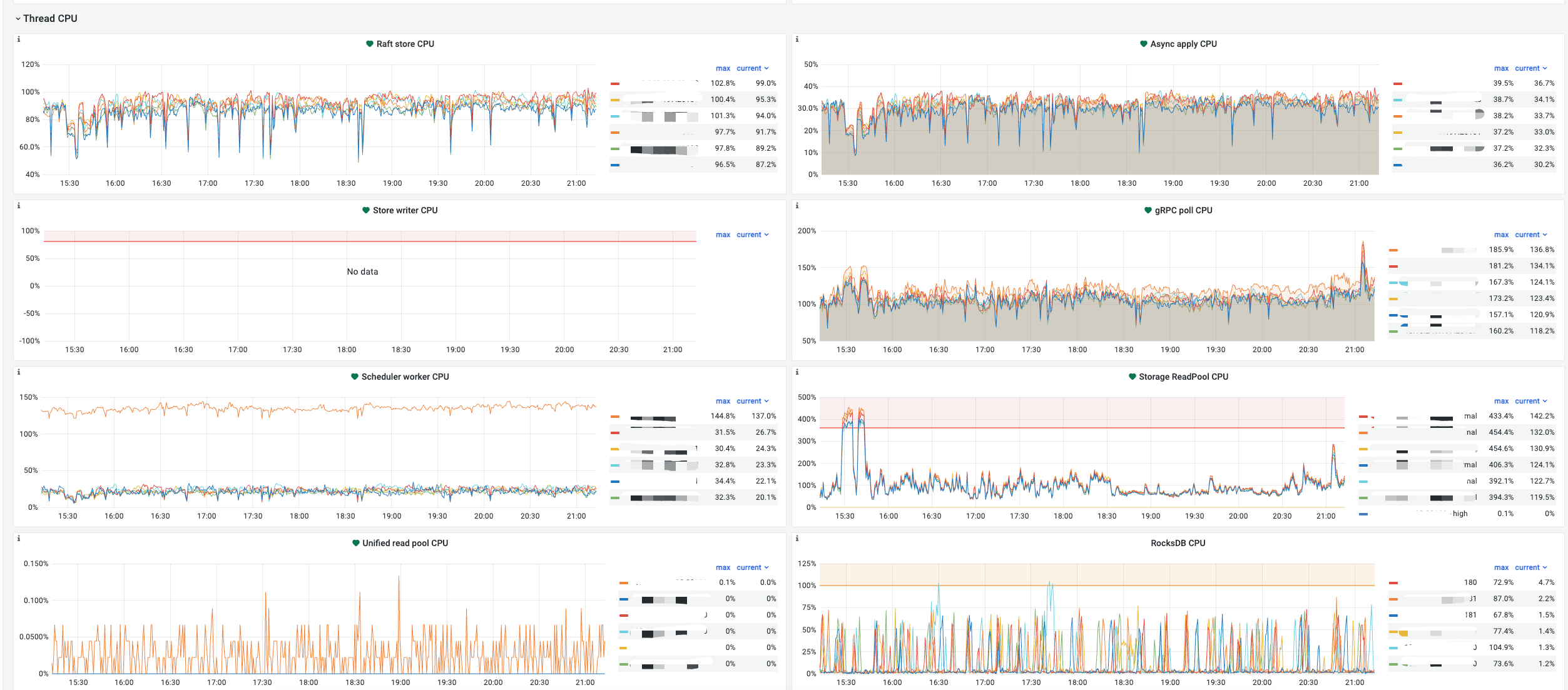
3.各组件CPU监控:
其中一个tikv scheduler cpu一直高于其他5各tikv
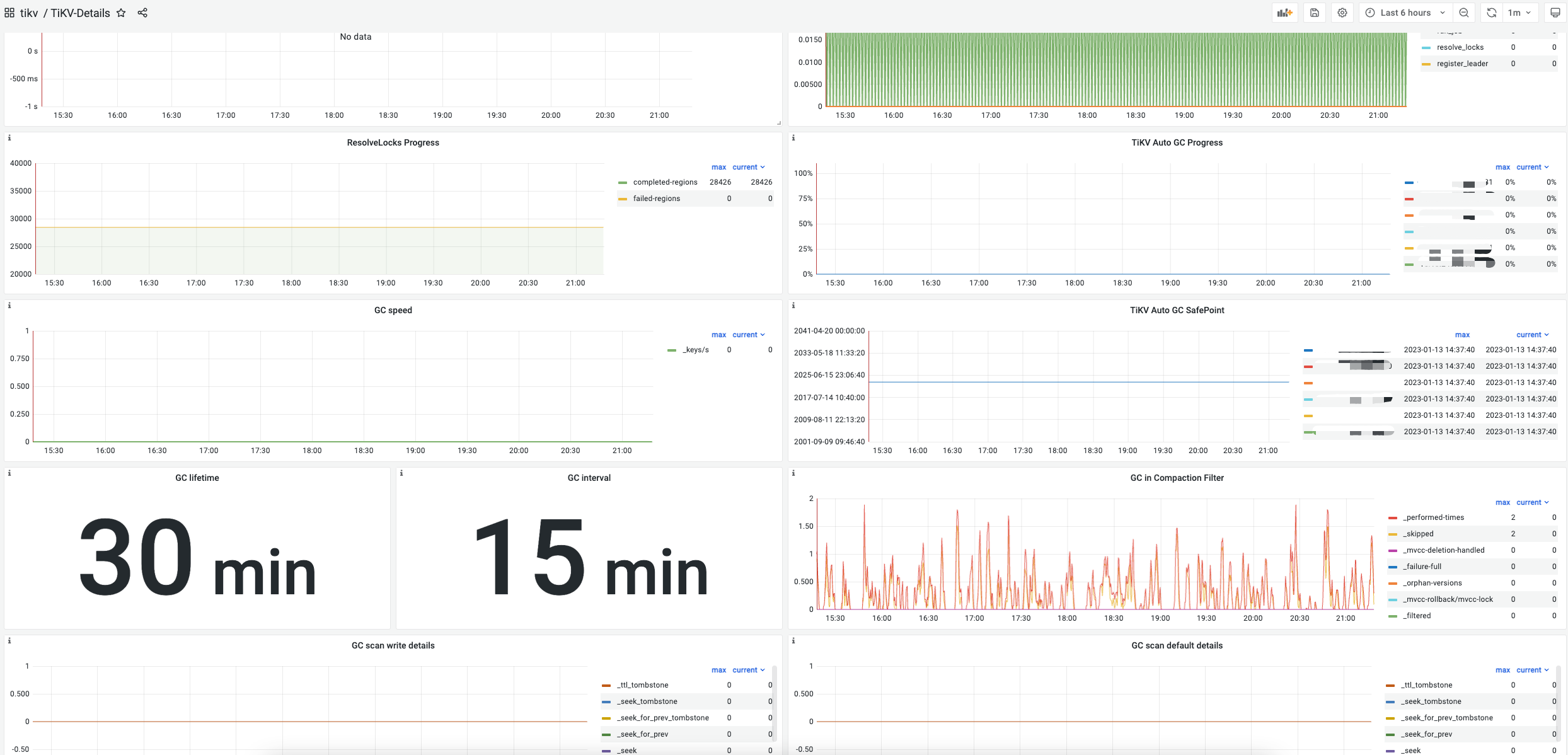
4.GC相关面板:
gc savepoint停留在很久以前
==============================日志相关截图=================
tidb日志:
报server is busy都是同一个region id
gc相关日志:

tikv scheduler cpu异常 日志
大量如下告警日志

日志涉及的region信息: