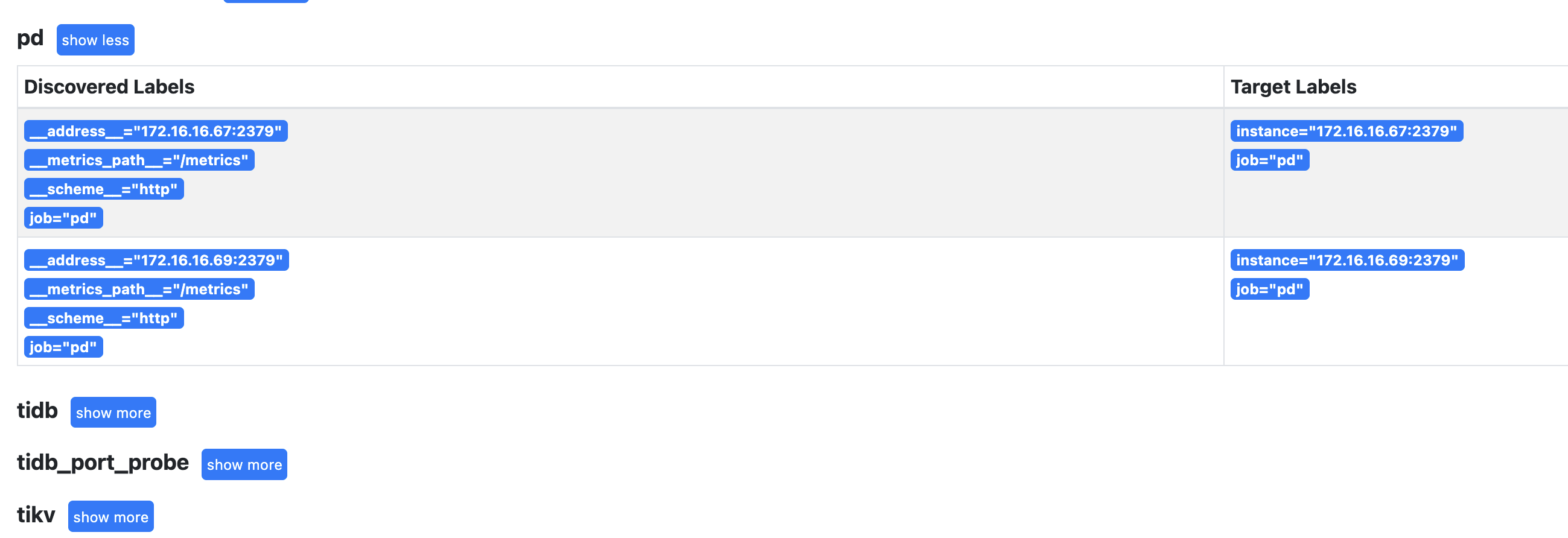
这个69 是我不要的。现在已经缩容清掉了,现在一共有9个警告。
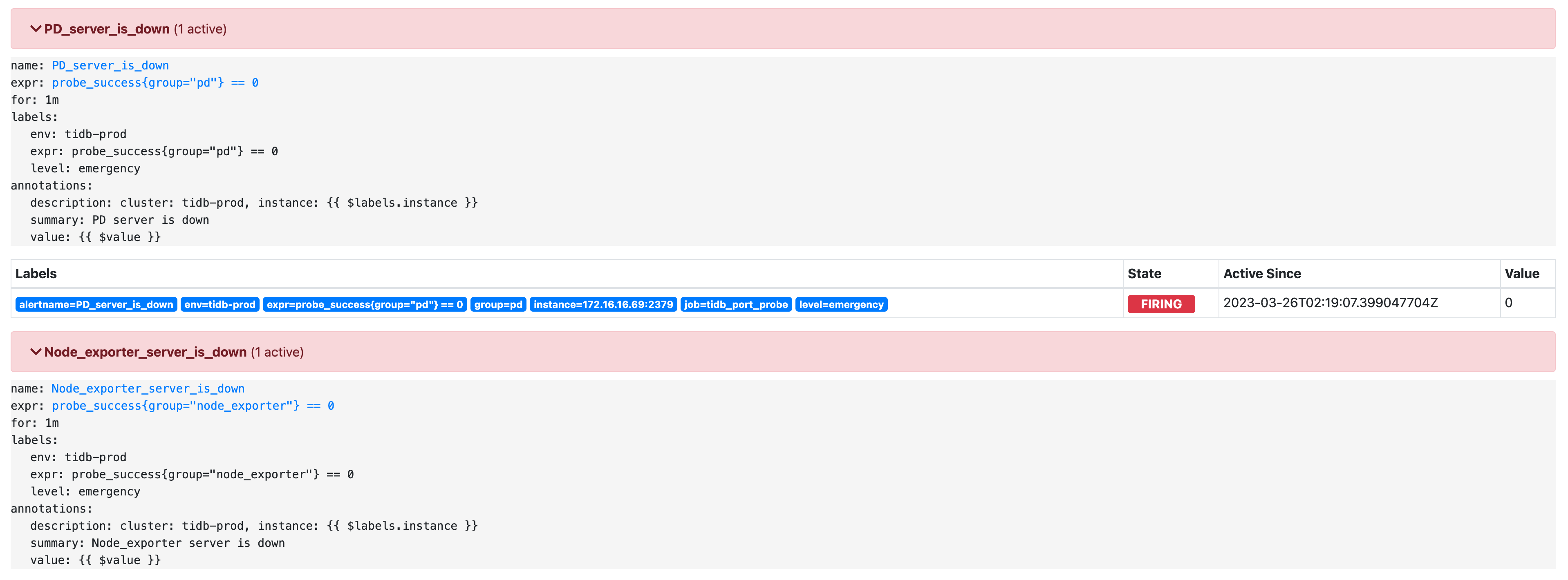
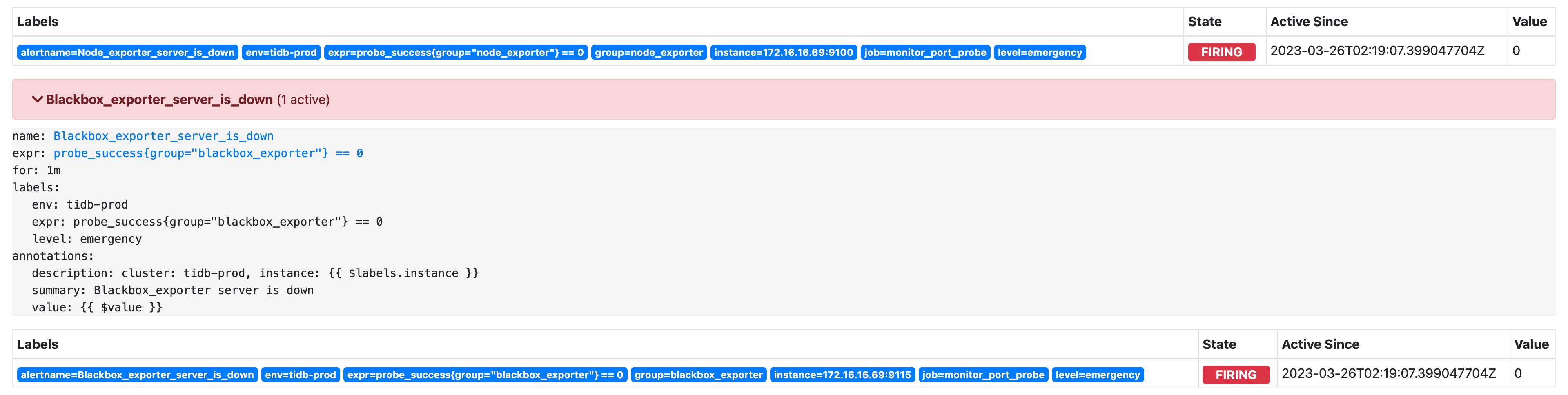
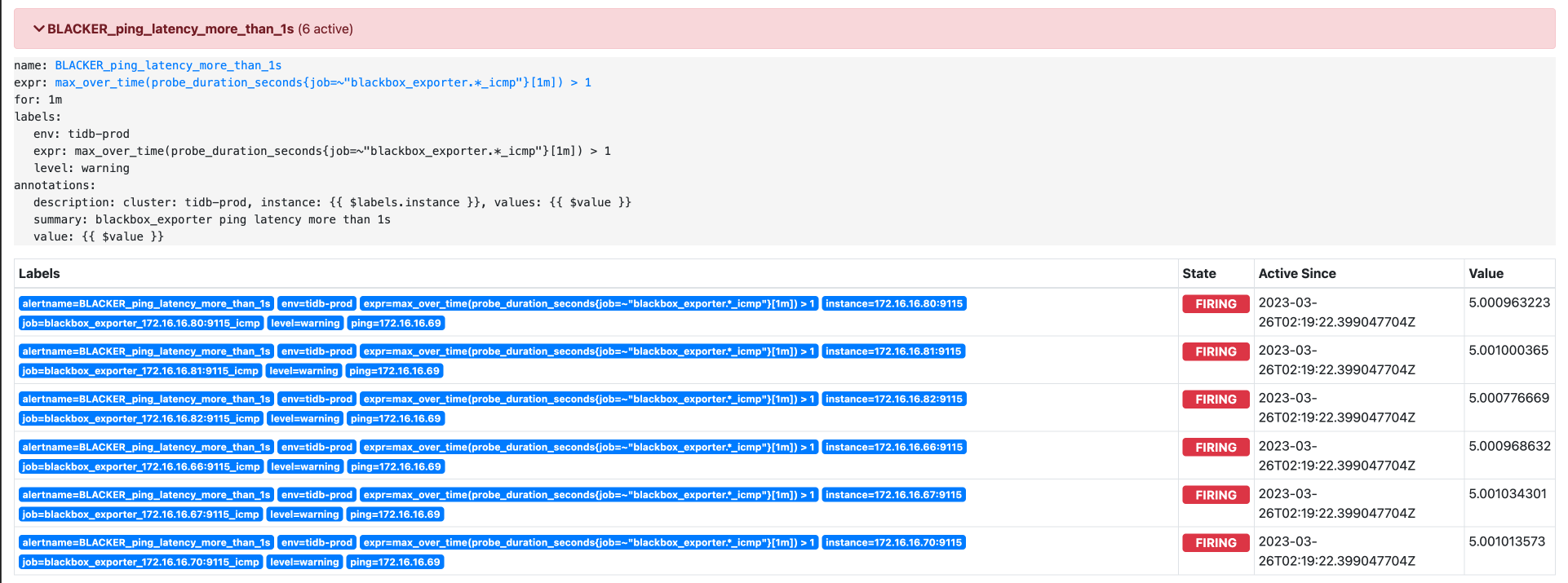
有没有兄弟对这个Prometheus了解的,因为我没有迁移pd的learder 直接做了缩容,所以监控上出了异常,集群上正常的。目前查出来的问题上Prometheus上的监控信息没有正常清理掉相关配置,所以导致集群警告报错。
我想进入Prometheus修改配置文件的lable,等信息,然后重启Prometheus,应该就正常了。
这个69 是我不要的。现在已经缩容清掉了,现在一共有9个警告。
有没有兄弟对这个Prometheus了解的,因为我没有迁移pd的learder 直接做了缩容,所以监控上出了异常,集群上正常的。目前查出来的问题上Prometheus上的监控信息没有正常清理掉相关配置,所以导致集群警告报错。
我想进入Prometheus修改配置文件的lable,等信息,然后重启Prometheus,应该就正常了。
reload promethues
可以讲的更详细些吗?我的技术功底比较弱,怎么操作,用什么命令,在哪个目录等。
tidb operator 管理的还是 tiup 管理 的?
tiup 管理等集群
tiup cluster reload -N 你的Prometheus IP:9090 (如果没有改过啥从话)
[tidb@tiup-new ~]$ tiup cluster reload -N 172.16.16.66:9090
tiup is checking updates for component cluster …
Starting component cluster: /home/tidb/.tiup/components/cluster/v1.11.3/tiup-cluster reload -N 172.16.16.66:9090
Reload a TiDB cluster’s config and restart if needed
Usage:
tiup cluster reload [flags]
Flags:
–force Force reload without transferring PD leader and ignore remote error
-h, --help help for reload
–ignore-config-check Ignore the config check result
-N, --node strings Only reload specified nodes
-R, --role strings Only reload specified roles
–skip-restart Only refresh configuration to remote and do not restart services
–transfer-timeout uint Timeout in seconds when transferring PD and TiKV store leaders, also for TiCDC drain one capture (default 600)
Global Flags:
-c, --concurrency int max number of parallel tasks allowed (default 5)
–format string (EXPERIMENTAL) The format of output, available values are [default, json] (default “default”)
–ssh string (EXPERIMENTAL) The executor type: ‘builtin’, ‘system’, ‘none’.
–ssh-timeout uint Timeout in seconds to connect host via SSH, ignored for operations that don’t need an SSH connection. (default 5)
–wait-timeout uint Timeout in seconds to wait for an operation to complete, ignored for operations that don’t fit. (default 120)
-y, --yes Skip all confirmations and assumes ‘yes’
[tidb@tiup-new ~]$
是不是还需要加参数?
缺少您tidb的名字
完整命令是
tiup cluster reload 你tidb集群的名字 -N 172.16.16.66:9090
已经修复好了,万分感谢。
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。