课程名称:TiDB 快速起步
1. 数据库、大数据与 TiDB 的发展简史
1.1. 数据库、大数据发展历史与趋势
-
数据库发展历程:

-
数据库技术发展内在驱动:
-
业务发展:数据容量持续爆发增长——数据存储量、吞吐量、读写QPS等
-
场景创新:数据的交互效率与数据模型多样性——查询语言、计算模型、数据模型、读写延时等
-
硬件与云计算的发展:数据架构的变迁——读写分离、一体机、云原生等
- 数据容量催生数据架构演进:
单节点本地磁盘
纵向扩展Scale up,网络存储ShareDisk
横向扩展Scale out,分布式Share Nothing
-
数据模型与交互效率演进:
| 数据库类型 | 产生原因 |
| --------------- | ---------------------------------- |
| RDBMS 单机数据库 | 支持事务并绝大部分采用结构化的方式存储 |
| NoSQL | Key-value、文本、图、时序数据、地理信息等非结构化数据的需求 |
| OLTP | 大部分NoSQL数据库对于事务无法支持 |
| NewSQL | 同时支持OLTP和兼容多种数据模式 | - 应对不同业务场景,基于这些相对固定数据基础技术,进行数据架构Trade OFF(选择与平衡)。
数据模型、数据结构、存储算法、复制协议、算子、计算模型、硬件
1.2. 分布式关系数据库的发展
- 分布式产生的内因:
1965年,高登.摩尔(Gordon Moore),提出摩尔定律。
核心观点: 集成电路上可以容纳的晶体管数目在大约每经过18个月便会增加一倍。换言之, 处理器的性能每隔两年翻一倍。
隐含意思: 如果你的系统需承载的计算量的增长速度,大于摩尔定律的预测,集中式系统将无法承载你所 需的计算量。
- 分布式定义
分布式,本质上是进行数据存储与与计算的分治。
由于机器可能出现故障,分布式会提高故障率,因此需要多副本来解决高可用问题。
- 分布式历史
2006年,谷歌三架马车:
| GFS(Google File System) | 解决分布式文件系统问题 |
| Google Bigtable | 解决分布式KV存储问题 |
| Google MapReduce | 解决分布式文件系统和分布式KV存储上面如何做分布式计算和分析的问题 |
- 分布式技术的主要挑战:
-
如何最大程度的实现分治
-
如何实现全局一致性,包括序列化与全局时钟
-
如何进行故障与部分失效的容错
-
如何应对不可靠的网络与网络分区
- CAP
| 一致性consistency | 所有节点在同一时间的数据完全一致 |
| 可用性Avaliability | 服务在正常响应时间内一直可用 |
| 分区容错性Partition tolerance | 分布式系统在遇到某节点或网络分区故障时,仍然能够对外提供满足一致性或可用性的服务。 |
- ACID
**事务的本质:**并发控制单元,是用户定义的一个操作序列。要么都做,要么都不做,不可分 割的工作单元。
| 原子性Atomicity | 事务包含的全部操作是一个不可分割的整体,要么全部执行,要么全部不执行。 |
| 一致性Consistency | 事务前后,所有的数据都保持一致的状态,不能违反数据的一致性检查。 |
| 隔离性Isolation | 各个事务之间相互影响的程度,主要用于规定多个事务访问同一数据资源,各个事务对该数据资源访问的行为。不同的隔离性是为了应对不同的现象,比如脏读、可重复读、幻读等。 |
| 持久性Durability | 事务一旦完成,要将数据所做的变更记录下来。 |
CAP和ACID都有一致性,但 CAP (副本一致性) 与 ACID (事务一致性) 里的两个一致性描述的场景却不同。
- NewSQL
NewSQL = 分布式系统 + SQL + 事务
即原生分布式关系型数据库。
1.3. TiDB 产品与开源社区演进
分布式两个重要基础:Google spanner、Raft
开源特点:开放源码、开放态度、开源社区治理
TiDB是一个计算与存储分离的架构,存储引擎叫TiKV。
2015年5月,在Github创建项目。
2. TiDB 整体概述
2.1. 我们到底需要一个什么样的数据库
- 重新设计一个数据库,必须有的功能:
(1) 扩展性
-
弹性角度,颗粒度越小越好。
-
数据库写入资源昂贵,需要面向写入能力的线性扩展机制。
(2) 强一致性与高可用性
-
强一致性指CAP的一致性。常见强制写入两节点副本。
-
RPO(Recovery Point Objective)即数据恢复点目标。
-
RTO(Recovery Time Objective)即恢复时间目标。
-
强一致等价:RPO=0 ,RTO足够小,通常若干秒级。
(3) 标准SQL与事务(ACID)的支持
-
SQL易用性
-
OLTP完整事务性
(4) 云原生数据库
(5) HTAP
-
支持海量数据
-
行列混合,彻底资源隔离
-
开放,兼容数据库与大数据生态
-
统一数据查询服务
(6) 兼容主流生态与协议
- 降低使用门槛和成本
- 基础数据技术元素
| 序号 | 元素 | 说明 |
|---|---|---|
| 1 | 数据模型 | 关系模型、文档模型、key-value模型等 |
| 2 | 数据存储与检索结构 | 数据结构、索引结构,常见B-tree、LSM-tree等 |
| 3 | 数据格式 | 关系型和非关系型 |
| 4 | 存储引擎 | 负责数据的存取和持久化存储,比如Innodb\Rockdb等。 |
| 5 | 复制协议 | 保证数据可用性,复制协议与算法,常见Raft、Paxos等 |
| 6 | 分布式事务模式 | 事务处理时的并发控制方法,以保证可串行化。常用模型SZ\TCC\Percolator等。 |
| 7 | 数据架构 | 一般指多个计算引擎共享一份数据,或者每个计算引擎都有一份数据。常见Share-Nothing\Share-Disk等。 |
| 8 | 优化器算法 | 根据数据分布、数据量和统计信息,生成成本最低的执行计划。 |
| 9 | 执行引擎 | 比如火山模型、向量化、大规模并行计算等。 |
| 10 | 计算引擎 | 负责SQL语句接口,解析生成执行计划并发送给存储引擎来执行,同时大部分计算引擎具有缓存数据的功能。 |
- 计算与存储分离
存储与计算耦合方式弊端:
(1) 计算与存储强绑定,意味着总有一种资源的浪费。
(2) 在服务器选型时,会纠结计算型、存储型,增加了复杂度,降低了通用性。
(3) 在云计算的场景下,弹性的颗粒度是机器,不能真正做到资源的弹性。
在云时代,基于高性能的网络块存储(EBS),存储与计算耦合的方式更不合理。
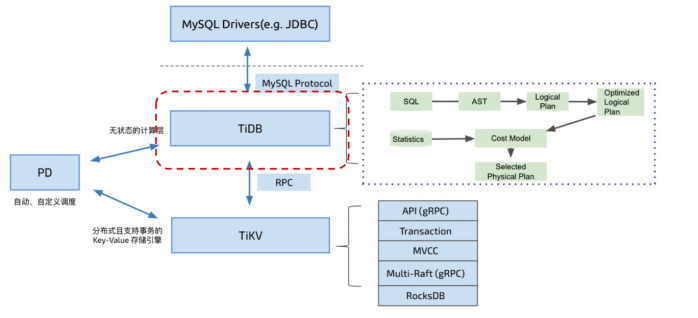
- TiDB高度分层架构
(1) 支持标准SQL的计算,引擎TiDB-Server
(2) 分布式存储引擎TiKV
(3) 负责元信息管理与调度的,调度引擎Placement Driver
2.2. 如何构建一个分布式存储系统

- 我们需要一个什么样的存储引擎:
(1) 更细粒度的弹性扩容、缩容
(2) 高并发读写
(3) 数据不丢不错
(4) 多副本保障一致性及高可用
(5) 支持分布式事务
- 如何构建一个完整的分布式存储系统
(1) 选择数据结构
-
Key-value数据模型
-
索引结构LSM-tree.(对写入采取了顺序写的方式,写入到一定阈值后,持久化成一个静态文件,随着写入的越来越大,生产的静态文件会被推到下一层进行再合并。本质上是用空间置换写入延迟,用顺序写入替换随机写入。)
(2) 选择数据副本——Raft
(3) 如何实现扩展
-
分片采用:rang算法
-
Region:key-value空间的分段。当前默认96MB。
(4) 如何进行分离与扩展
-
通过region的大小来分裂与合并。——当region超过一定限制(默认144MB),TiKV会将它分裂为两个或多个,当region因大量删 除过小,TiKV会合并相邻region。
-
有一个组件记录Region在各节点分布情况。
-
Raft对三副本复制
(5) 灵活调度机制
- 列表条目
PD组件负责region均匀分散,实现存储容量水平扩展、负载均衡。
(6) 多版本控制MVCC
(7) 分布式事务模型
-
采用Google的Percolator事务模型,并优化及该井。克服了采用“两阶段”提交方式事务管理器性能瓶颈:
-
采用“去中心化”的两阶段提交算法。列簇、全局受时TSO;
-
默认隔离级别Snapshot Isolation,SI和RR(可重复度)隔离级别接近,天然没有幻读现象。同时也支持RC(提交读)隔离级别;
-
支持乐观锁、悲观锁;
-
支持第二阶段异步提交。
(8) 协作处理器
- 协调计算器Coprocessor。
(9) TiKV整体架构
TiKV参考Google Spanner设计了multi raft-group的副本机制,首先将数据按照key的范围划分成大致相等的切片(region),每个切片会有多个副本(通常3个),其中一个副本是leader,提供读写服务。TiKV通过PD对这些region以及副本进行调度,并决策哪个副本成为leader,以保证数据和读写负载都均匀的分散在各个TiKV上,这样的设计保证了整个集群资源的充分利用并且可以随着机器数量的增加水平扩展。
2.3. 如何构建一个分布式 SQL 引擎

-
实现逻辑表:通过全局有序的分布式key-value引擎。
-
基于kv的二级索引设计,同样是一个全局有序kv map。Key是索引列,values是原表的primary key。
-
SQL 引擎过程
-
SQL语法解析、语意解析、协议解析
-
AST抽象语法树。将SAL从文本解析成结构化数据。
-
SQL逻辑优化。各种SQL等价改写与优化,比如子查询改成表关联,列裁剪、分区裁剪等。
-
优化器基于统计信息与成本模型的生产执行计划。最关键。“最佳出行计划”。
-
执行器执行
- 基于成本优化器
优化器怎么才能找到最佳执行计划?
-
知道各算子的优势及适用场景。
-
CPU、内存、网络等资源合理利用,基于成本模型。
- 分布式SQL引擎主要优化策略
-
执行器构建:最大程度下推计算。
-
关键算子分布式化
- 如何构建一个Online DDL算法
-
无分表概念,Schema(表结构)只存储一份,加字段只需要操作Schema,无需更新数据。
-
DDL过程状态化(Public/Delete-only/Write-only),每状态在多节点之间同步和一致。
- 如何链接到TiDB-Server
Mysql客户端、SDK链接
- 从进程的角度看TiDB-Server
一个后台进程。
**过程:**启动、监听4000端口、与Client通讯、解析网络请求、SQL解析、PD集群获取TSO、region路由、TiKV读写数据。
- 前台功能
(1) 管理链接和账号权限管理
(2) MySQL协议编码解码
(3) 独立的SQL执行
(4) 库表元信息,以及系统变量
- 后台功能
(1) 垃圾回收
(2) 执行DDL
(3) 统计信息管理
(4) SQL优化器与执行器
3. 新一代 HTAP 数据库选型
3.1. 基于分布式架构的 HTAP 数据库
-
2005年,Gartner提出HTAP(在线事务处理/在线分析处理数据库)。省去ETL。
-
OLTP:追求高并发、低延迟;OLAP:追求吞吐量
-
HTAP下一步探索
-
数据服务统一
-
产品内嵌功能的迭代,由一些具体产品来完成HTAP
-
整合多个技术栈与产品,并进行数据的连同,形成服务的HTAP
- 数据仓库经历的阶段
-
批处理(ETL)离线数仓
-
批流结合lambda架构
-
流计算为主Kappa架构

3.2. TiDB 关键技术创新
- Trade OFF后的三个分布式系统:
-
分布式的KV存储系统
-
分布式SQL计算系统
-
分布式的HTAP架构系统
-
自动分片技术是更细维度弹性的基础
-
弹性的分片构建了动态的系统
-
Multi-Raft将复制组更离散
-
基于Multi-Raft实现写入的线性扩张
-
基于Multi-Raft实现跨IDC单表多节点写入
-
去中心化的分布式事务
-
Local Read and Geo-partition 本地读和多地多活跨地域数据分布
-
大数据容量下的HTAP
3.3. TiDB 典型应用场景及用户案例
- TiDB设计目标:
-
横向扩展能力(Scale out)
-
兼容MYSQL
-
完整事务(ACID)+关系型模型
-
HTAP
- 数据架构选型
保稳定、提效率、降成本、保安全。


4. TiDB 初体验
4.1. TiDB 初体验
使用 TiUP搭建本地测试集群,并自动安装 TiDB Dashboard 和 Grafana,支持 MacOS。参考网址: