【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.0
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
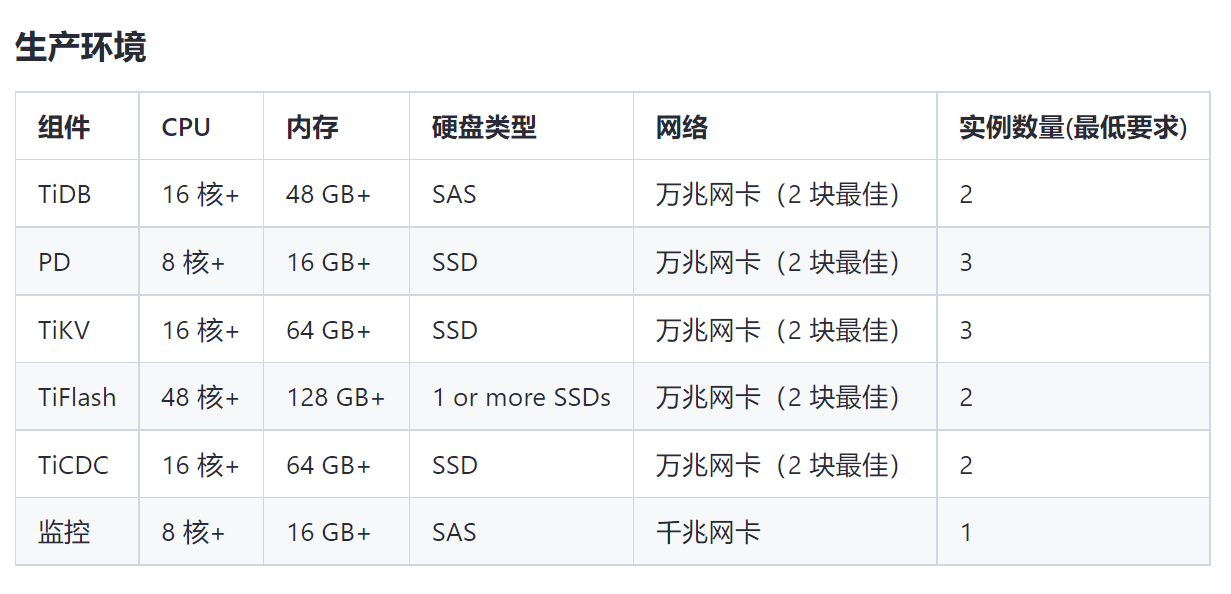
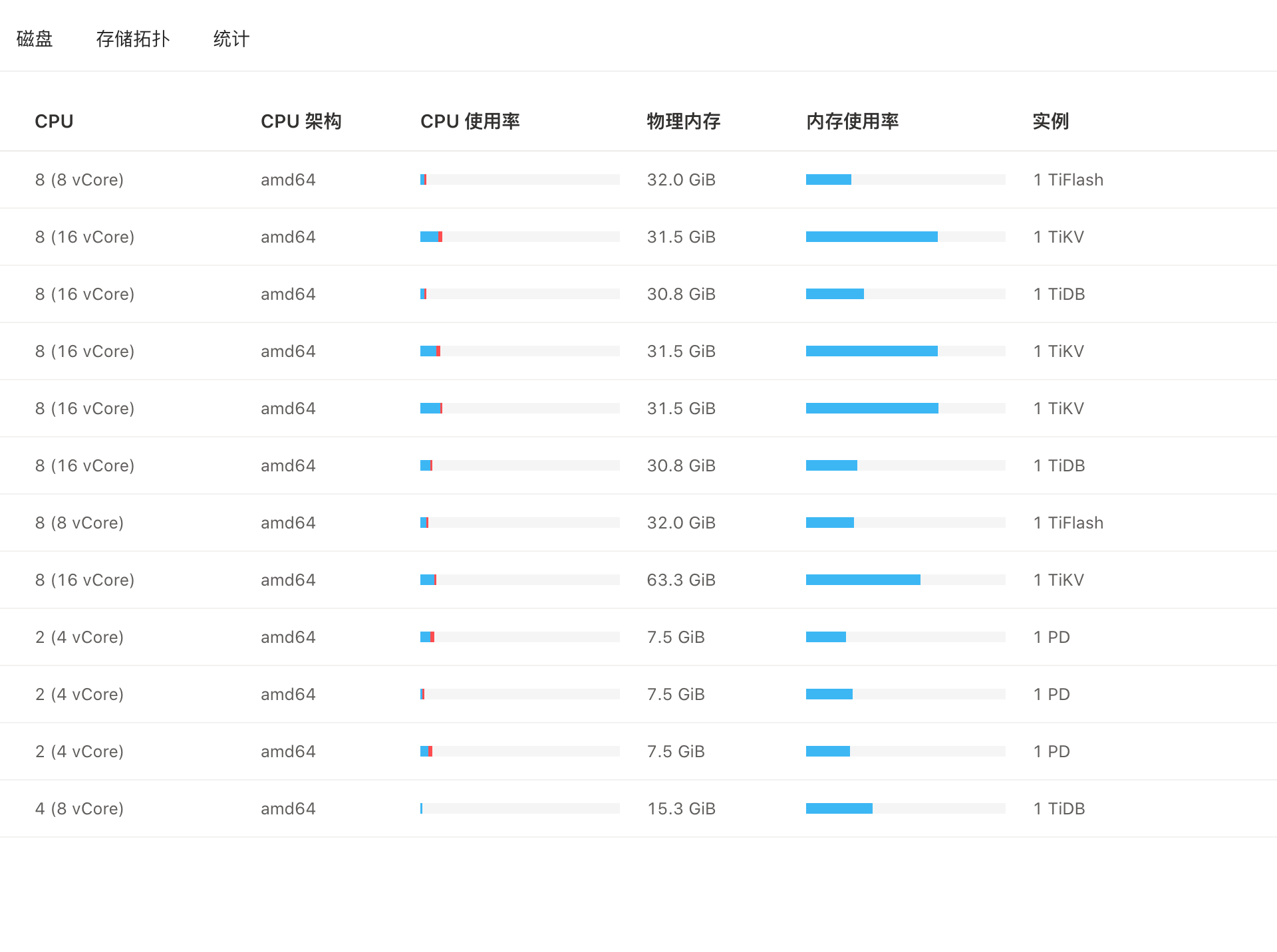
【资源配置】
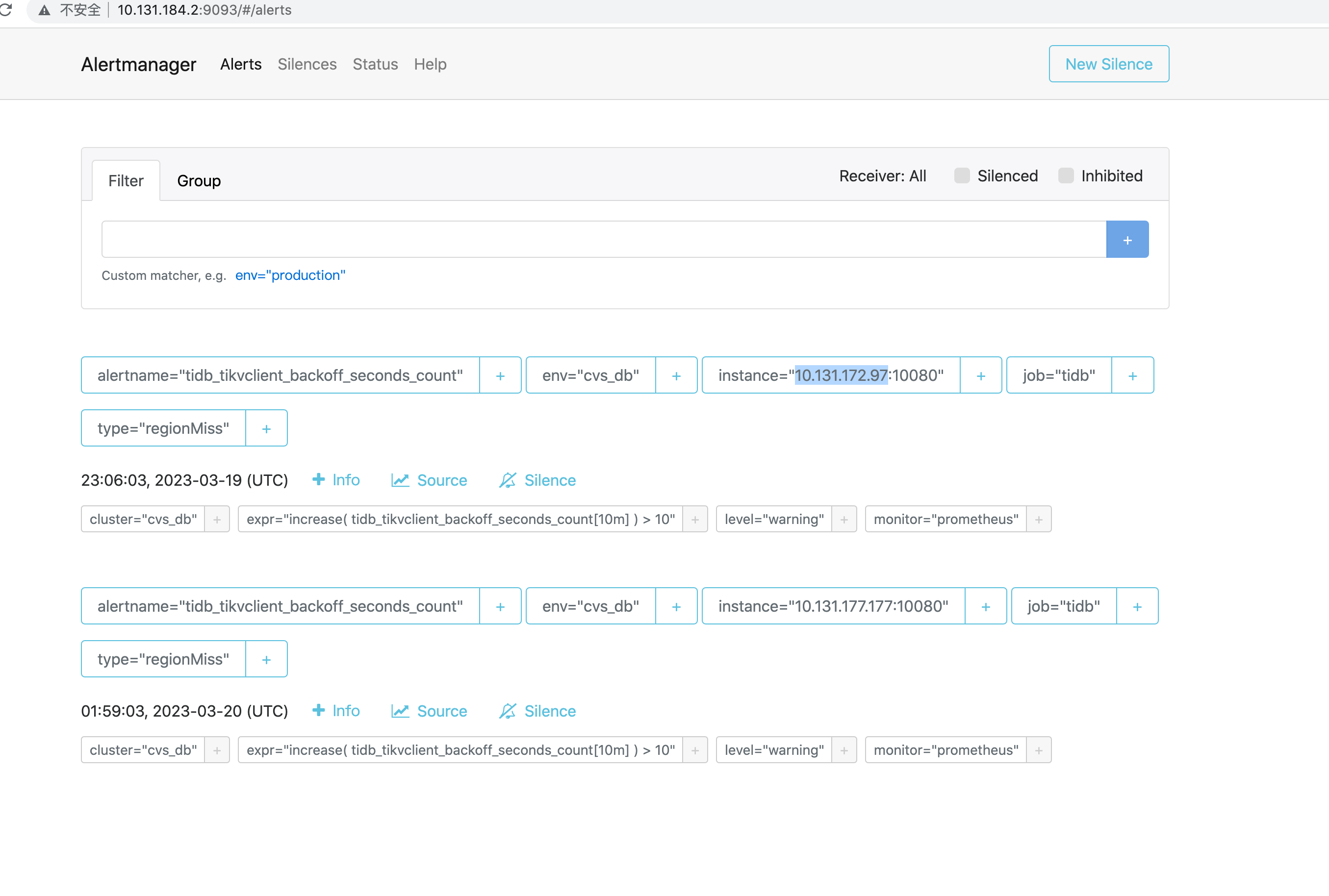
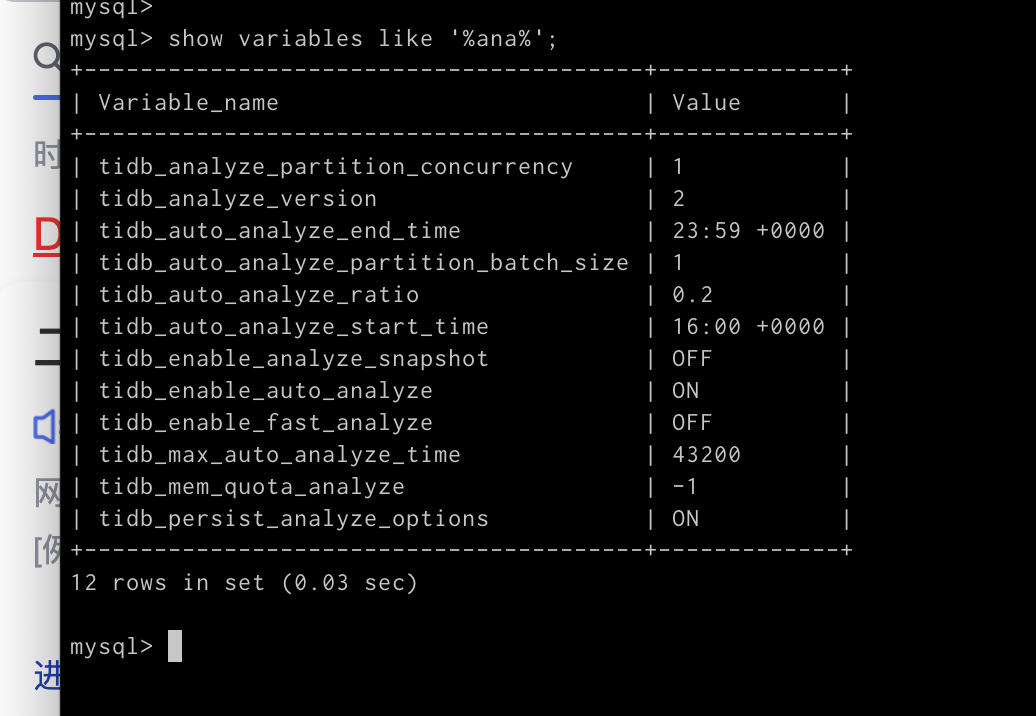
【附件:截图/日志/监控】

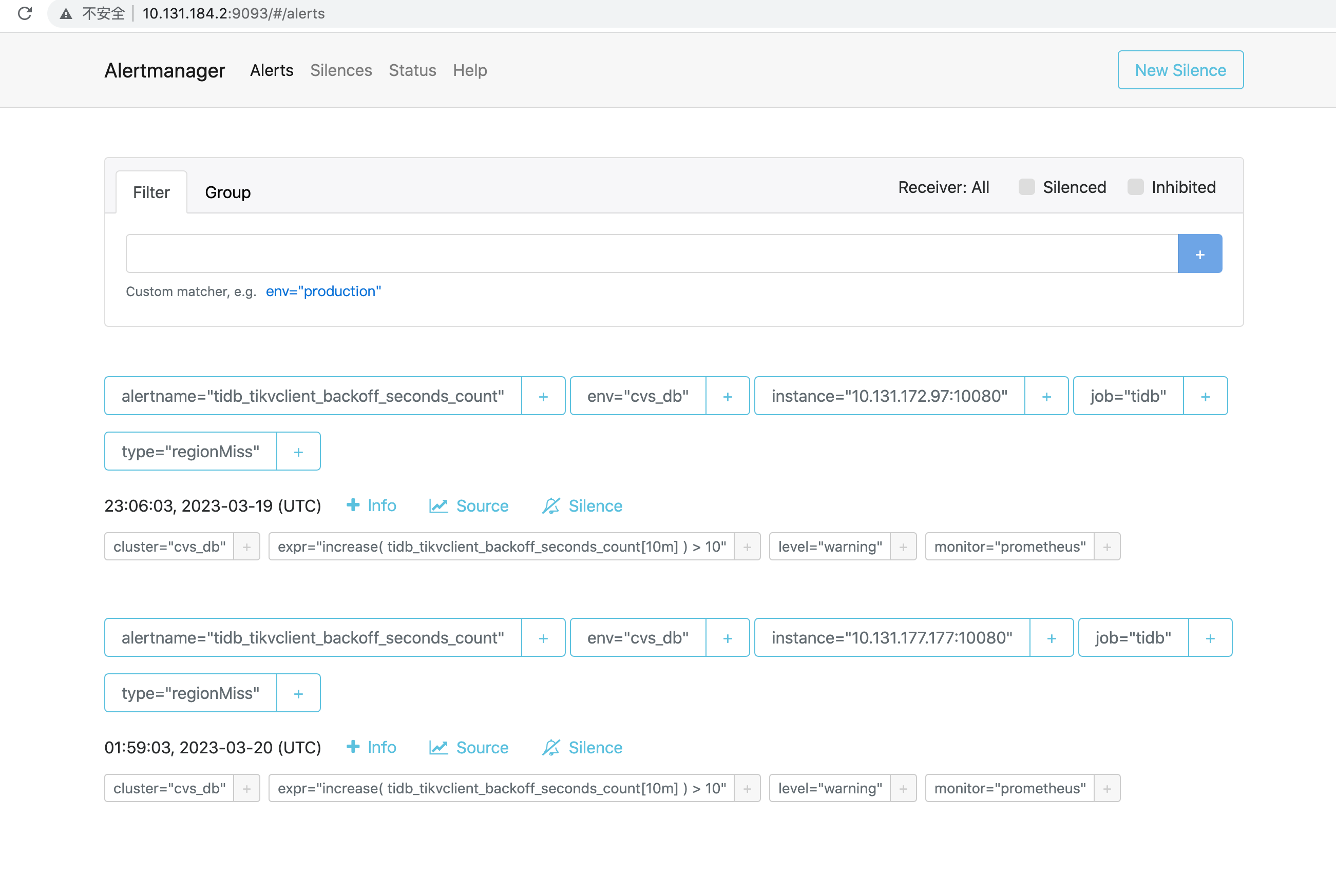
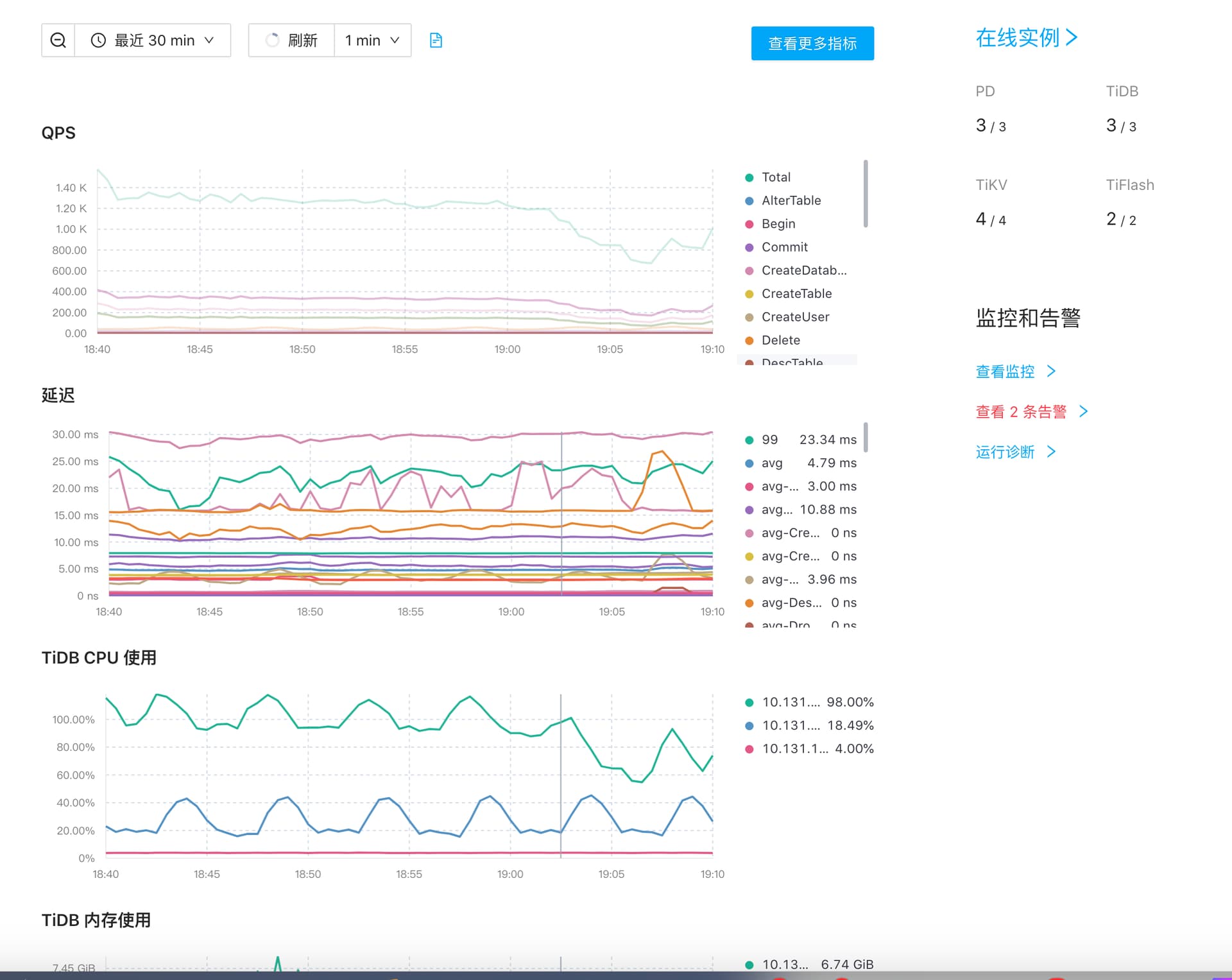
节点warn日志:
tikv:
[2023/03/20 19:30:25.553 +08:00] [WARN] [subscription_track.rs:143] [“trying to deregister region not registered”] [region_id=1391586]
[2023/03/20 19:32:01.364 +08:00] [WARN] [endpoint.rs:780] [error-response] [err=“Region error (will back off and retry) message: "region 1298525 is missing" region_not_found { region_id: 1298525 }”]
[2023/03/20 19:32:46.285 +08:00] [WARN] [endpoint.rs:780] [error-response] [err=“Region error (will back off and retry) message: "peer is not leader for region 1300428, leader may Some(id: 1393359 store_id: 101059)" not_leader { region_id: 1300428 leader { id: 1393359 store_id: 101059 } }”]