【 TiDB 版本】6.5
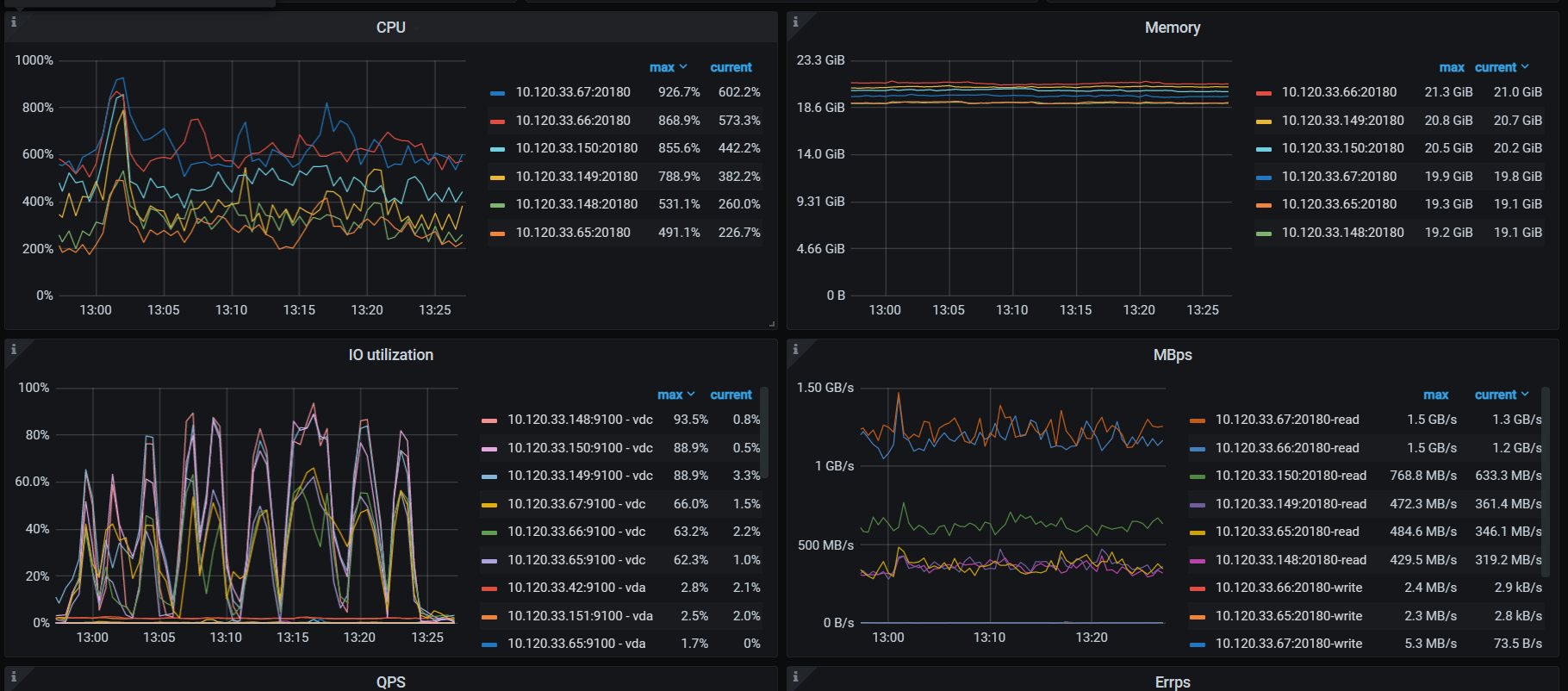
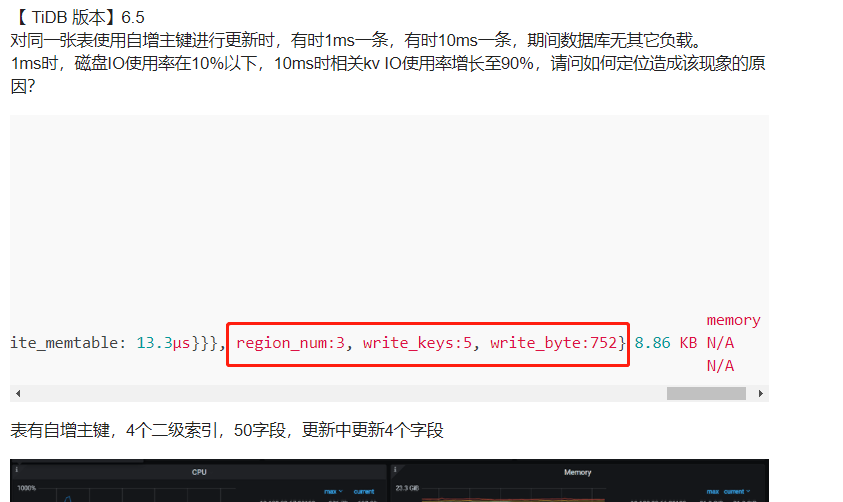
对同一张表使用自增主键进行更新时,有时1ms一条,有时10ms一条,期间数据库无其它负载。
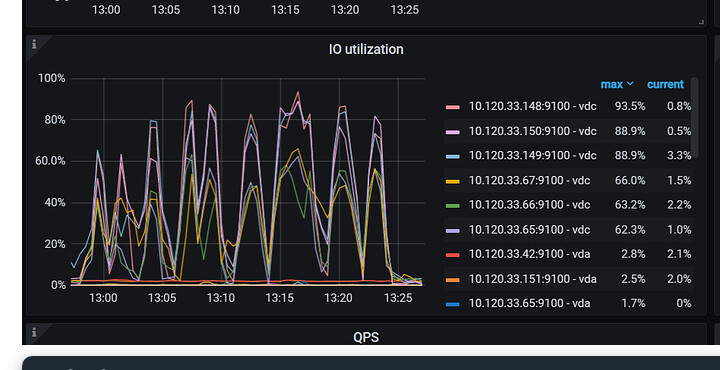
1ms时,磁盘IO使用率在10%以下,10ms时相关kv IO使用率增长至90%,请问如何定位造成该现象的原因?
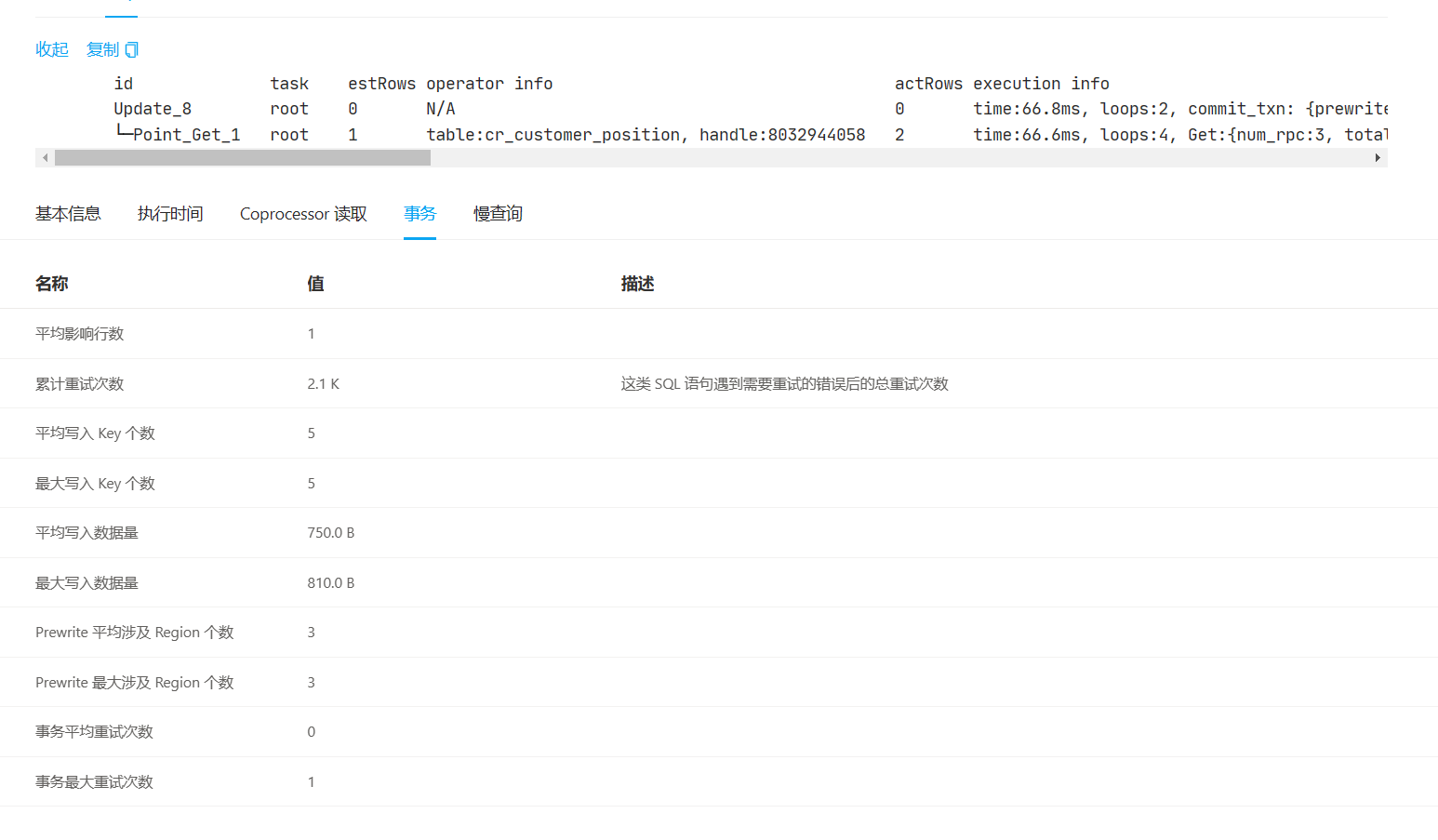
两者的执行计划里面,1ms的那个的point get有一个lock标记10ms的没有
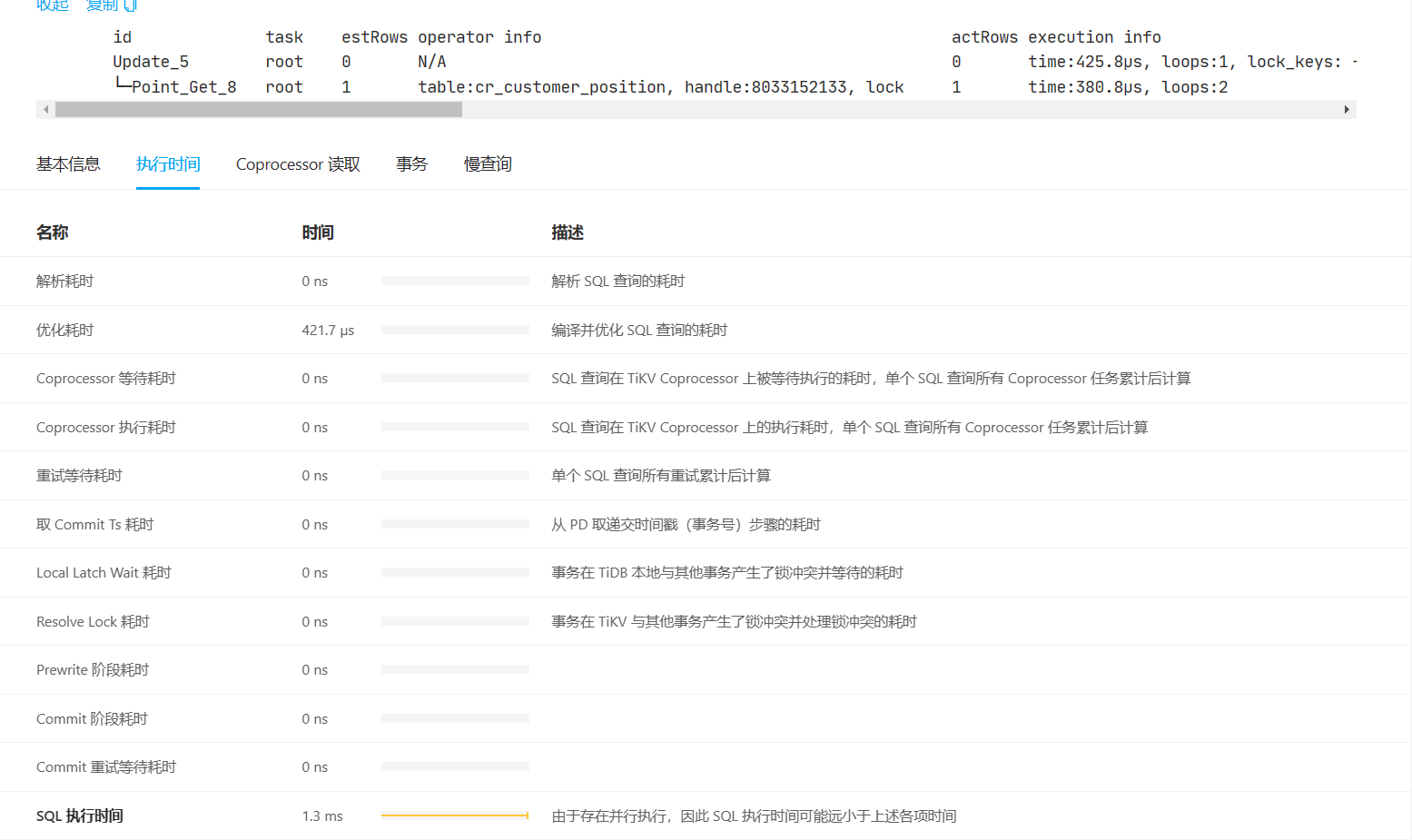
# 1ms
id task estRows operator info actRows execution info memory disk
Update_6 root 0 N/A 0 time:504µs, loops:1, lock_keys: {time:384.3µs, region:1, keys:1, slowest_rpc: {total: 0.000s, region_id: 2110830, store: 10.120.33.66:20160, tikv_wall_time: 129.2µs, scan_detail: {get_snapshot_time: 8.78µs, rocksdb: {block: {cache_hit_count: 9}}}, }, lock_rpc:364.748µs, rpc_count:1} 8.85 KB N/A
└─Point_Get_10 root 1 table:cr_customer_position, handle:8033706093, lock 1 time:405.5µs, loops:2 N/A N/A
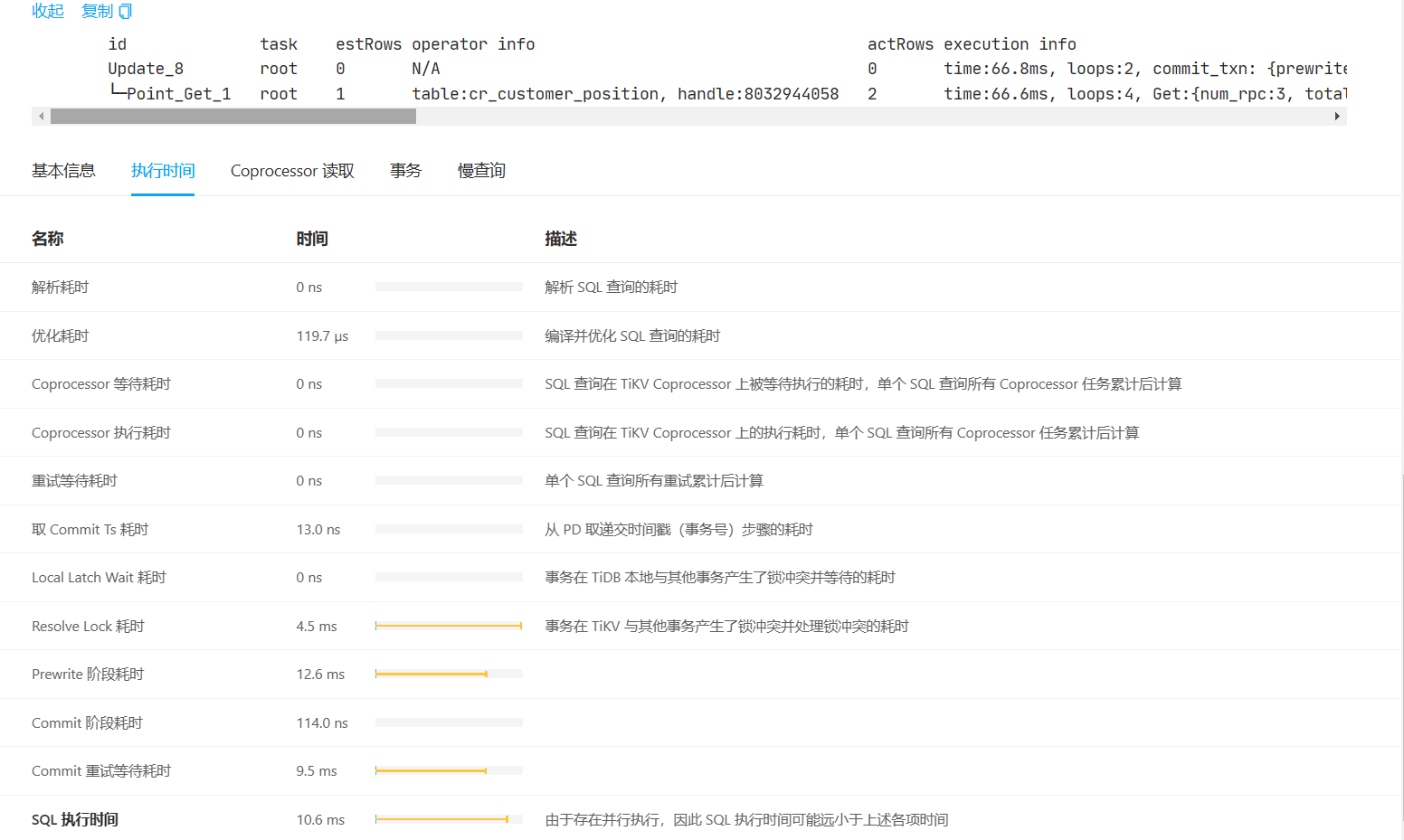
# 10ms
id task estRows operator info actRows execution info memory disk
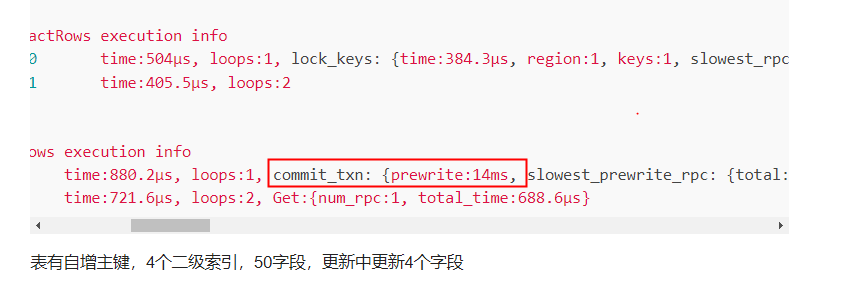
Update_4 root 0 N/A 0 time:880.2µs, loops:1, commit_txn: {prewrite:14ms, slowest_prewrite_rpc: {total: 0.014s, region_id: 1911628, store: 10.120.33.66:20160, tikv_wall_time: 13.6ms, scan_detail: {get_snapshot_time: 20.4µs, rocksdb: {block: {cache_hit_count: 15, read_count: 2, read_byte: 4.76 MB, read_time: 4.87ms}}}, write_detail: {store_batch_wait: 142.5µs, propose_send_wait: 0s, persist_log: {total: 2.69ms, write_leader_wait: 72ns, sync_log: 2.61ms, write_memtable: 16.5µs}, commit_log: 2.78ms, apply_batch_wait: 22.3µs, apply: {total:88.1µs, mutex_lock: 0s, write_leader_wait: 0s, write_wal: 22.3µs, write_memtable: 13.3µs}}}, region_num:3, write_keys:5, write_byte:752} 8.86 KB N/A
└─Point_Get_6 root 1 table:cr_customer_position, handle:8032919450 1 time:721.6µs, loops:2, Get:{num_rpc:1, total_time:688.6µs} N/A N/A
表有自增主键,4个二级索引,50字段,更新中更新4个字段