【 TiDB 使用环境】生产环境
【 TiDB 版本】v4.0.9
【复现路径】做过哪些操作出现的问题
br每月1号全量备份数据,每天增量备份数据。
br 先restore 1 号的全量数据到新tidb集群,再restore当天的增量数据。
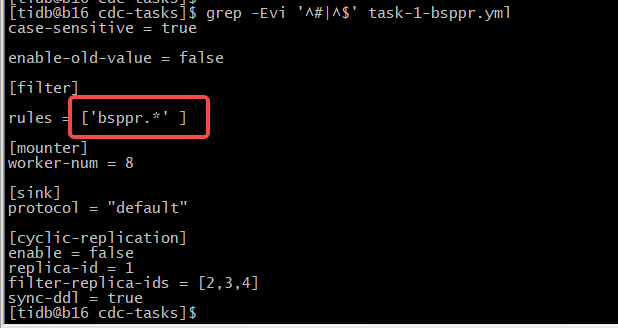
cdc 配置基于当天的增量数据 TSO 做同步数据。
【遇到的问题:问题现象及影响】
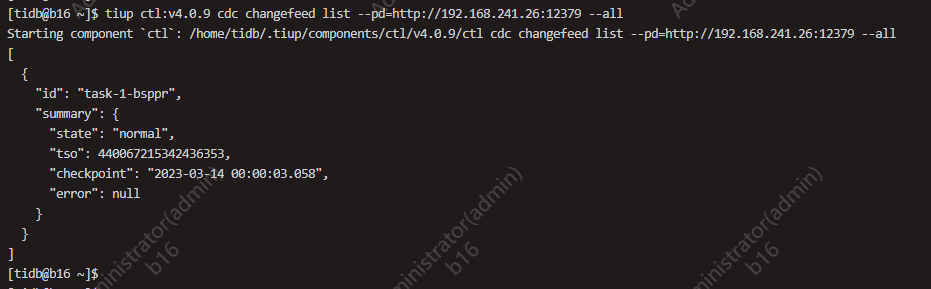
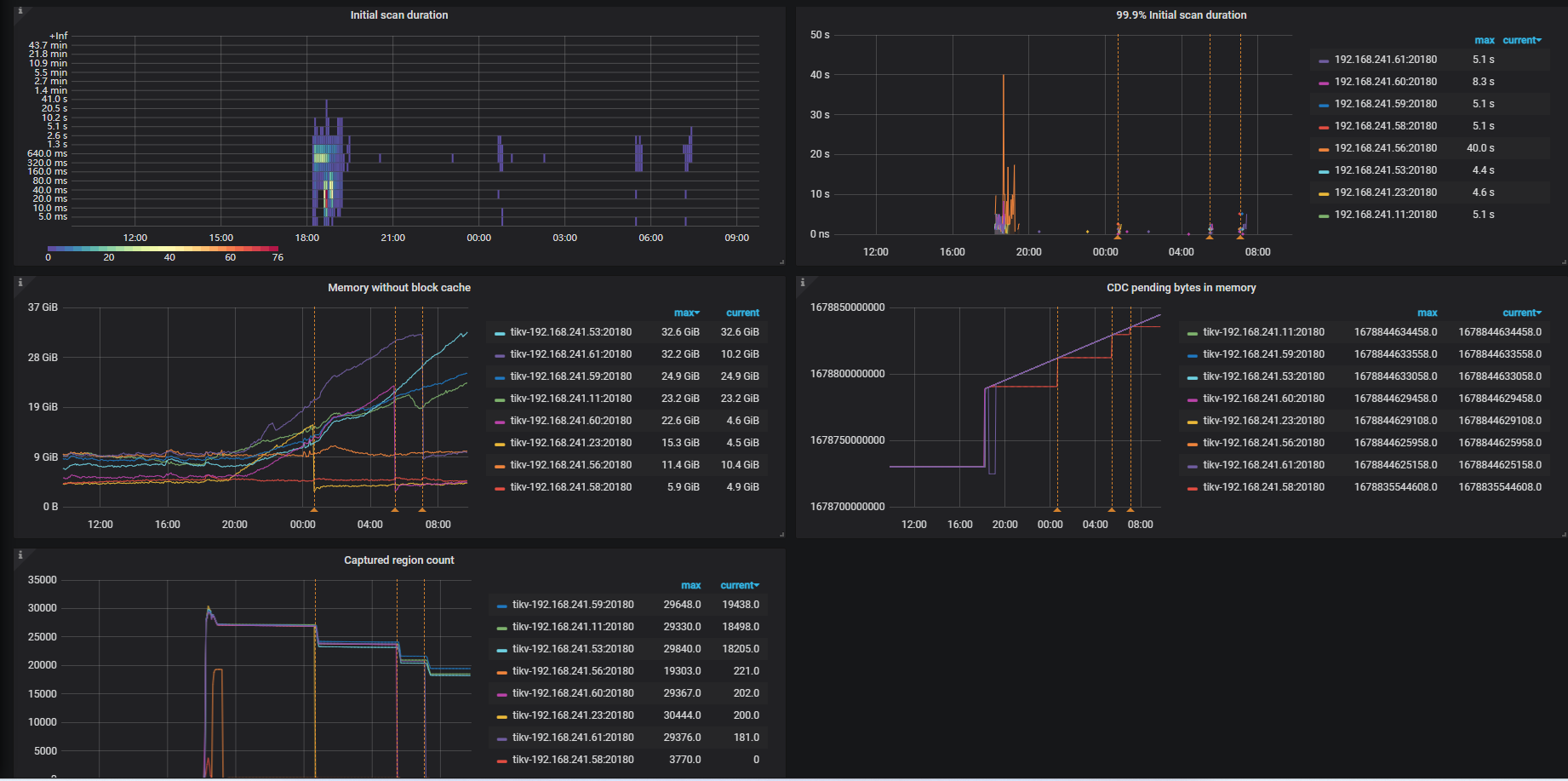
有1张表(这张表特别大,大概有60亿条数据)同步状态异常,好像其他的表看起来正常
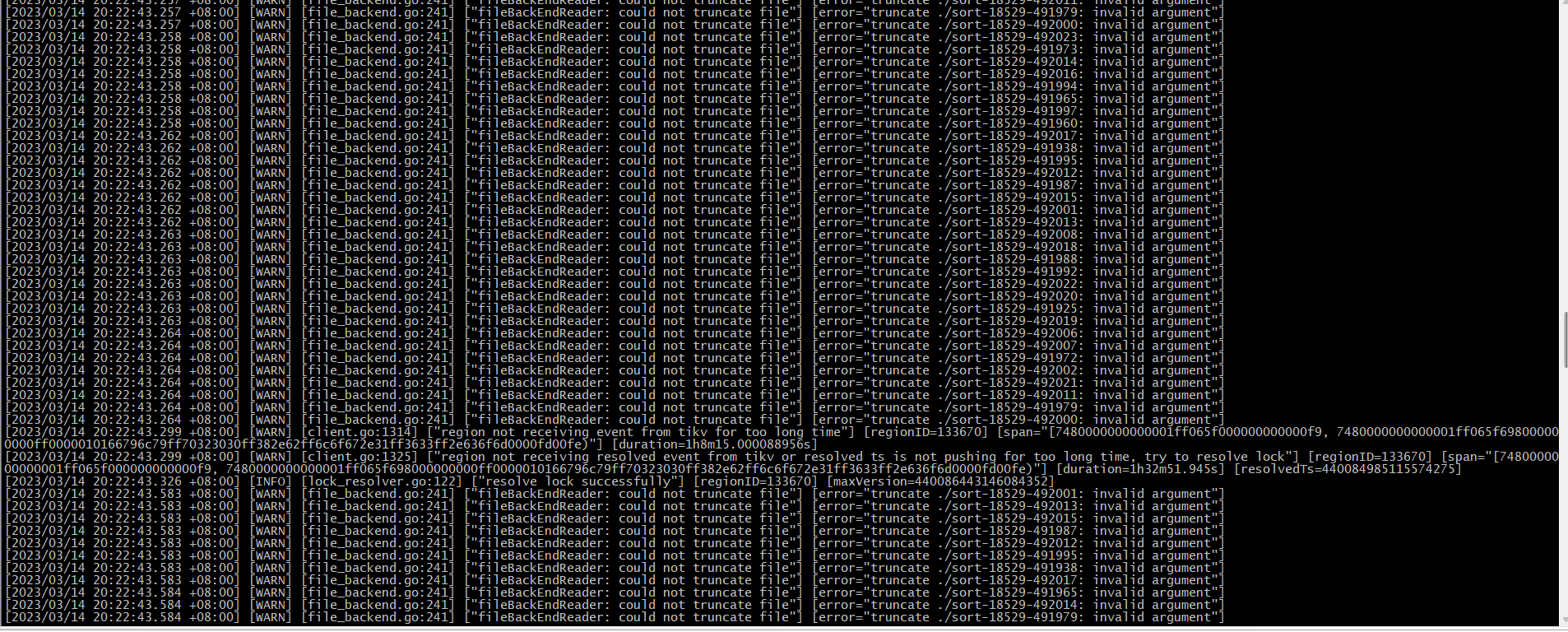
cdc日志一直在报这种信息:
我想问下这是什么情况? 增量时间是今天的凌晨0点,到现在也就20个小时呀, 怎么会有53.2 年啊?
看着像是这个意思,我猜可能是那个表太大了,老集群性能又不太好。。
但也不至于要53年啊 ,我想不明白,也不知道现在杂处理
性能再弱也是线上正在用的集群,只落后1天不到的数据。这53年是杂出来的啊
如果是有问题,那应该直接报错退出啊, task的状态一直是normal状态~~~
sdojjy
(Sdojjy)
4
应该是 metrics 有异常吧,取了一个 0 时间,猜测是 1970 + 53 = 2023
sdojjy
(Sdojjy)
6
这个图上就有同步到了哪个时间点了
不过你 cdc 的版本比较早了, 可能还有其他未知的 bug
这个时间就是最开始的时间,就是我恢复增量的时间,最开始就这样没变过
CuteRay
(Cherry🍒)
8
看一下你这几台机器的时间,你这一批机器是用的同一个ntp服务器吗?
是的,新老集群都是chronyd同步的本地ntp还有aliyun ntp
你是说prometheus metric监控取值 异常吗?那怎么看实际的状态是否正常呢
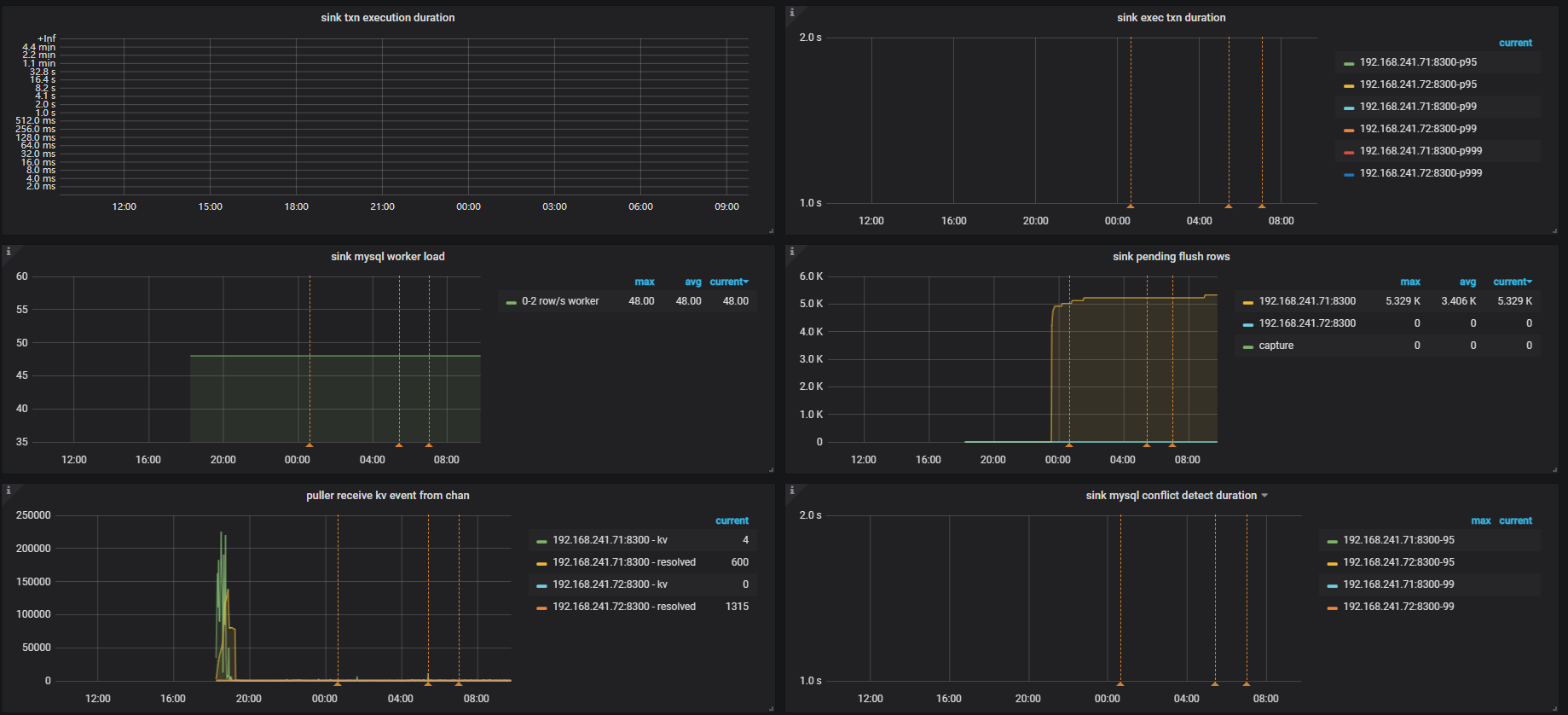
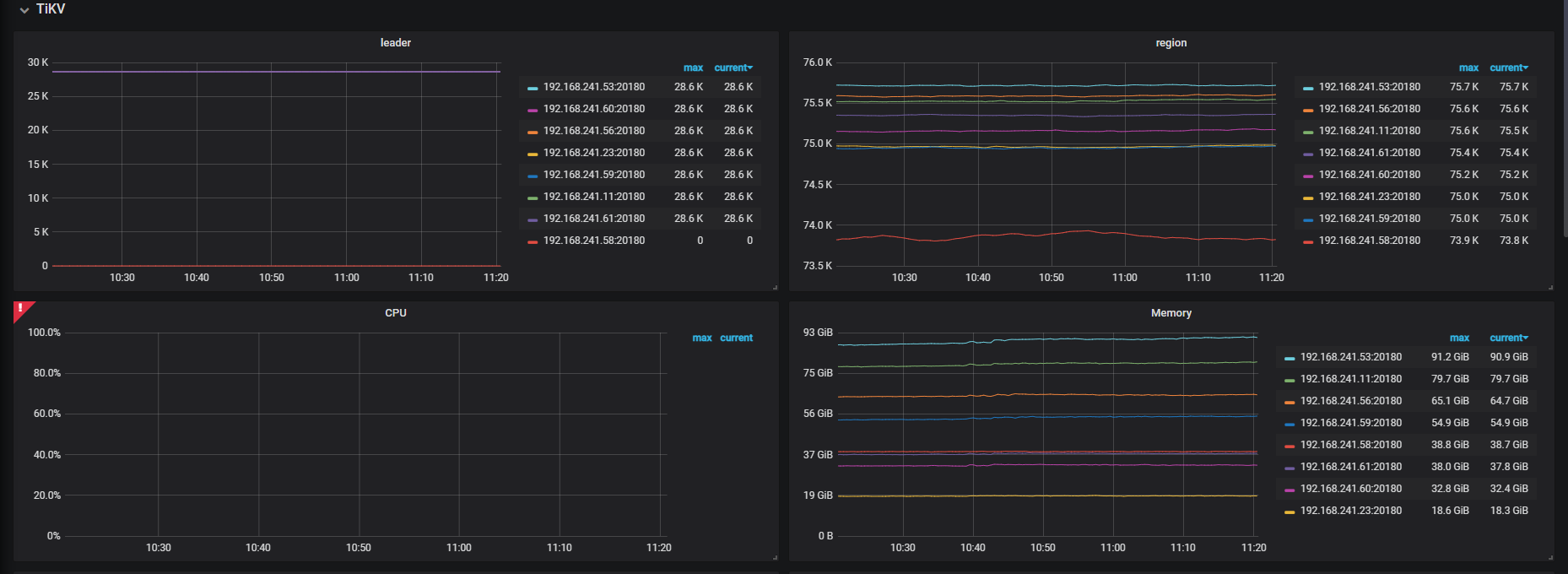
服务器为新机器:配置为48c 256g, 服务器内存剩余还挺多,cdc进程才吃了100G内存。
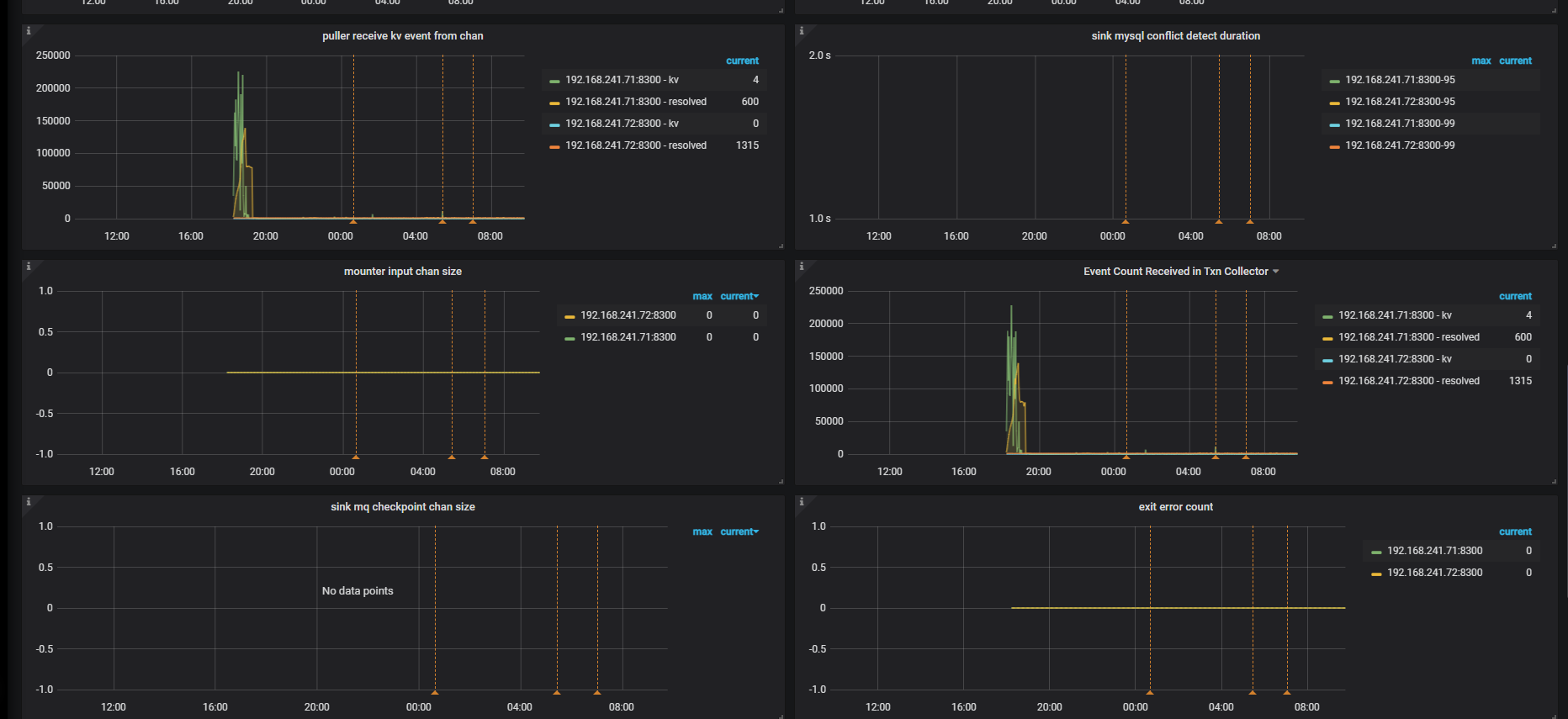
以下为grafana的一些截图:
sdojjy
(Sdojjy)
15
现在 cdc log 里还有大量的 warning 吗?
grafana 可以用 [FAQ] Grafana Metrics 页面的导出和导入 这里面提到的方法导出一下
还是和上面的截图一样,没变化,状态也是normal
嗯 对,你把 CheckpointTs 记录下来,重新创建两个任务。
1 个赞