【集群版本】 v3.0.12升级至v4.0.16
【复现路径】
一个数据量较大的集群(数据量80TB左右,120个左右的tikv实例)进行版本升级
升级前期较为顺畅,大约1min左右可以完成1个实例的evict leader,但是还剩30多个实例时leader转移开始卡慢,出现600s超时的问题,于是手动对应节点的实例进行了restart以便加速升级速度,之后正常跑完升级流程。
【遇到的问题:问题现象及影响】
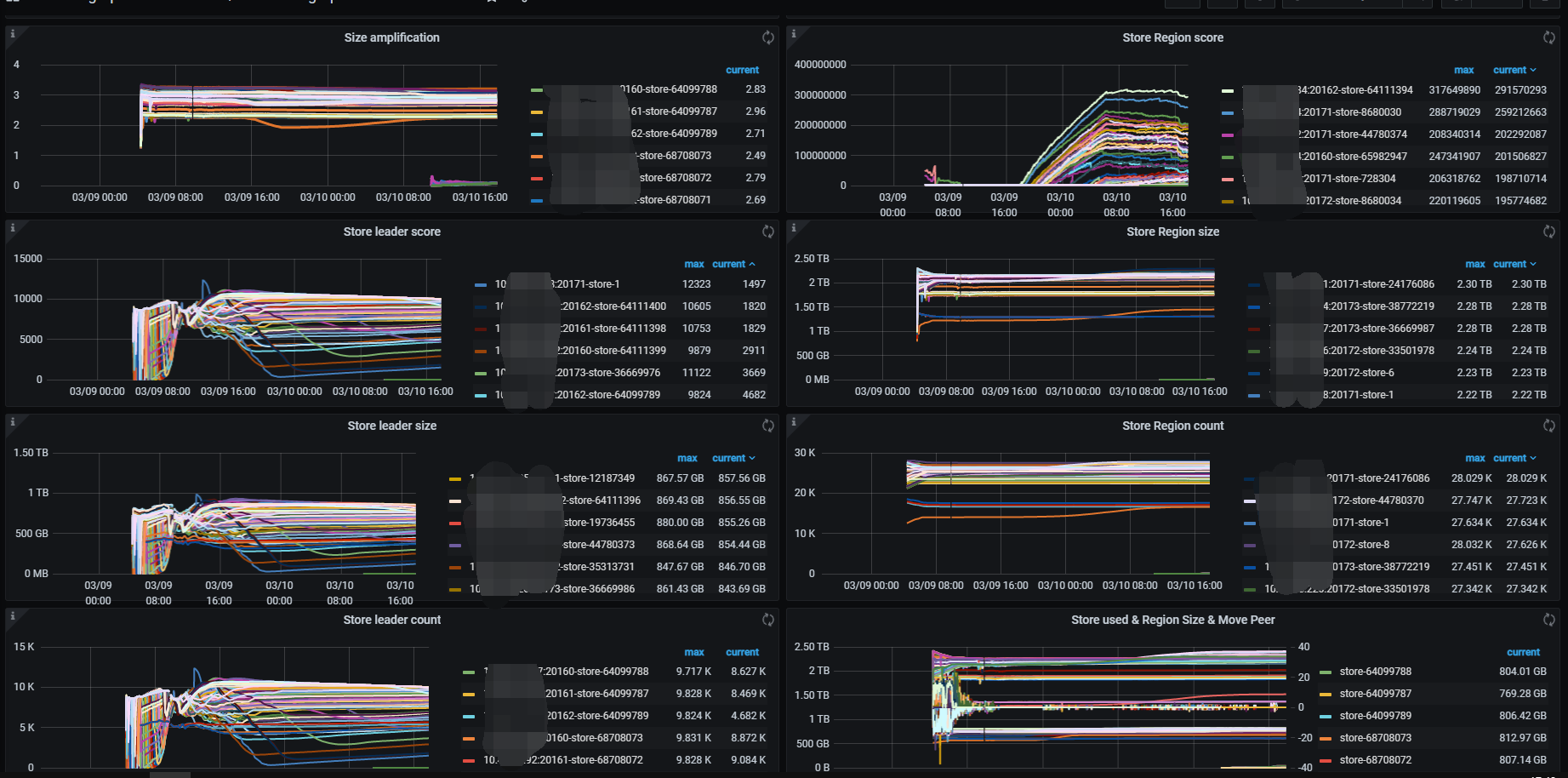
升级完成后,查看监控发现pd调度界面显示的异常peer开始增多,见下图。

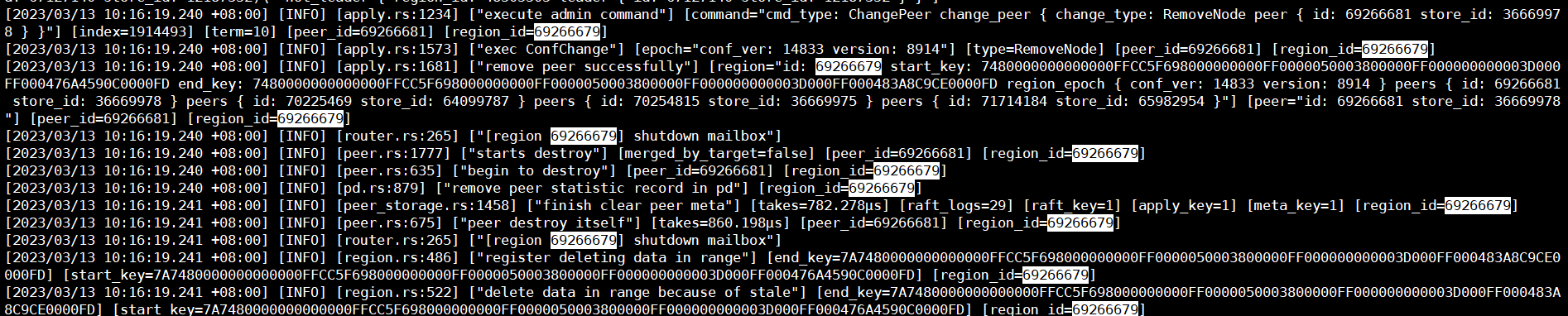
经查看pd leader的日志以及手动测试发现,常规的leader transfer operator和remove peer等极大概率超时,下图为我随机选取一个operator的执行日志:
首先是pd leader展示的超时流程:

然后是目标store展示的此region相关的操作:

至"deleting applied snap file"之后截止,也不知道是卡住了还是日志就展示这么点东西。
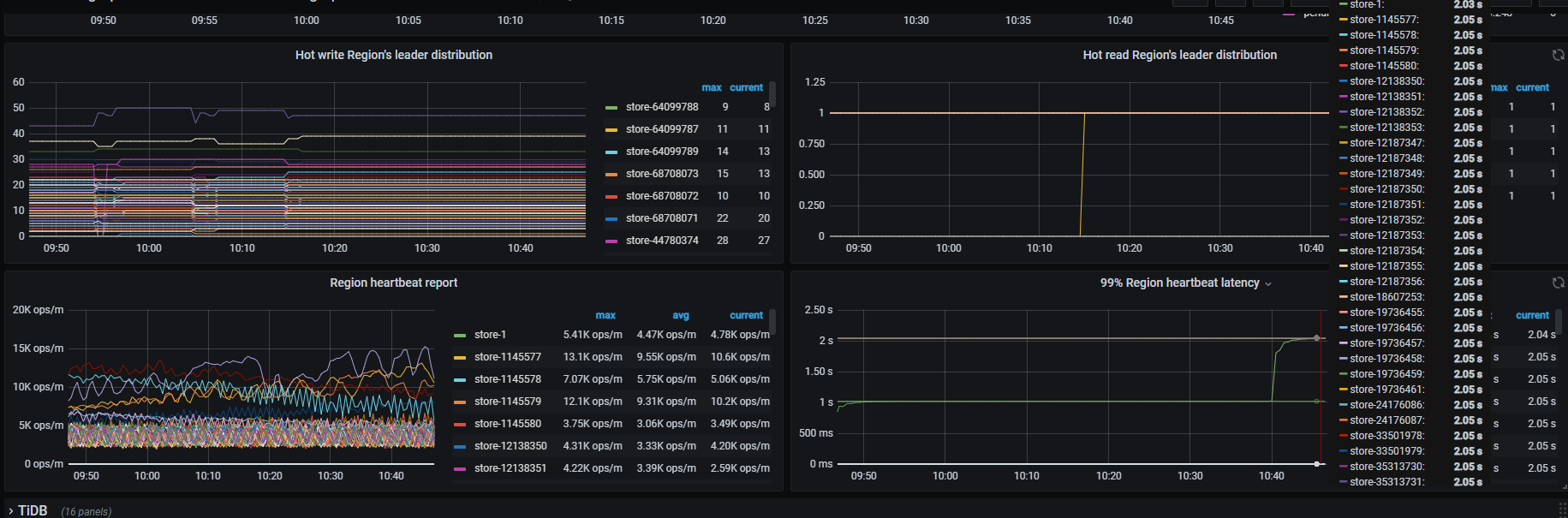
当前由于磁盘使用率较高,因此我进行了扩容,但是发现新节点的均衡速度极其缓慢。
【我的猜测以及我问题】
我个人猜测可能是强制重启带来了较大范围的region peer置换,这种置换的速率较低引发了extra-peer和learner-peer的堆积。
请问下是否有什么办法来处理上述的operator超时问题?从而加快region的调度速度,只调整region调度参数目前只能导致更多的堆积而无法对加速起到实质作用了。
【其他附件】
pd当前配置:
» config show
{
"replication": {
"enable-placement-rules": "false",
"location-labels": "host",
"max-replicas": 3,
"strictly-match-label": "false"
},
"schedule": {
"enable-cross-table-merge": "false",
"high-space-ratio": 0.75,
"hot-region-cache-hits-threshold": 3,
"hot-region-schedule-limit": 4,
"leader-schedule-limit": 8,
"leader-schedule-policy": "count",
"low-space-ratio": 0.8,
"max-merge-region-keys": 200000,
"max-merge-region-size": 20,
"max-pending-peer-count": 16,
"max-snapshot-count": 3,
"max-store-down-time": "30m0s",
"merge-schedule-limit": 16,
"patrol-region-interval": "100ms",
"region-schedule-limit": 256,
"replica-schedule-limit": 64,
"split-merge-interval": "1h0m0s",
"tolerant-size-ratio": 0
}
}
» scheduler show
[
"label-scheduler",
"balance-region-scheduler",
"balance-hot-region-scheduler",
"balance-leader-scheduler"
]