海石花47
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.1
【遇到的问题:问题现象及影响】
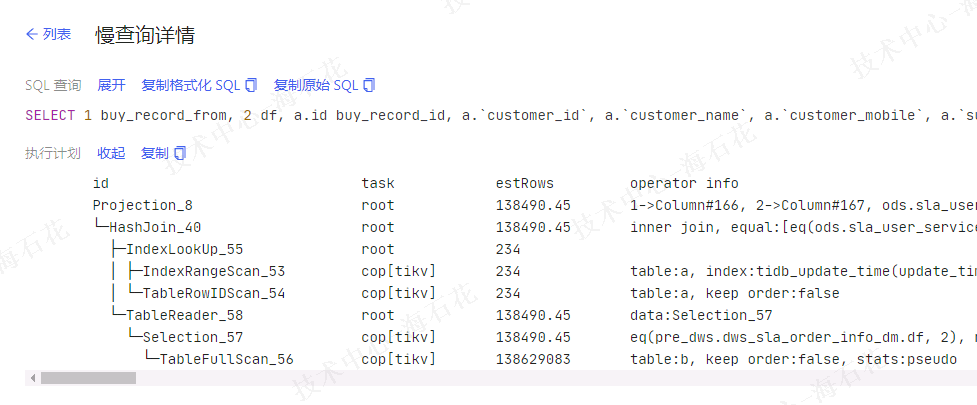
如下所示,a表数据量十几万,加上Update_time之后也就几百行数据量
但是,b表数据量上亿
两个表的相关字段都有索引
直接跑,会挂,问,sql我该如何优化?? 感谢各位大神帮助!
SELECT
a.xxx
FROM
a
JOIN b ON a.order_no = b.order_no
AND b.df = 2
WHERE
a.update_time >= '2023-03-09 13:36:07'
【资源配置】
【附件:截图/日志/监控】
update_time上有索引吗?执行计划发一下看看
海石花47
4
虽然我已经没法复现那个情况了,但是你这个思路看起来不错,谢谢拉
人如其名
(人如其名)
6
这个b.order_no,b.bf没索引吧,不然估计应该会走索引而不是hashjoin,如果经过关联后order_no,bf值不多的话。
也有可能是 a.order_no = b.order_no 都没有索引,如果其中1个字段有索引,也有可能取走index join
看执行计划b表全表扫描了,而且执行信息里有pseudo关键字表示表统计信息可能不准,导致执行有问题。所以需要检查一下索引情况以及analyze 表更新表统计信息,处理好之后应该问题可以得到解决
Running
(Hacker Zs58i2 Gb)
10
order_no 和 update_time 加上索引,或者直接使用tiflash
海石花47
11
都是单索引,不是联合索引。 但是不是会索引合并的吗?
海石花47
13
当时的情况是 b表因为程序出问题了 导致有个字段全是null,数据量也异常到上亿,且疯狂增长。 所以估计当时的表健康度很低。
system
(system)
关闭
15
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。