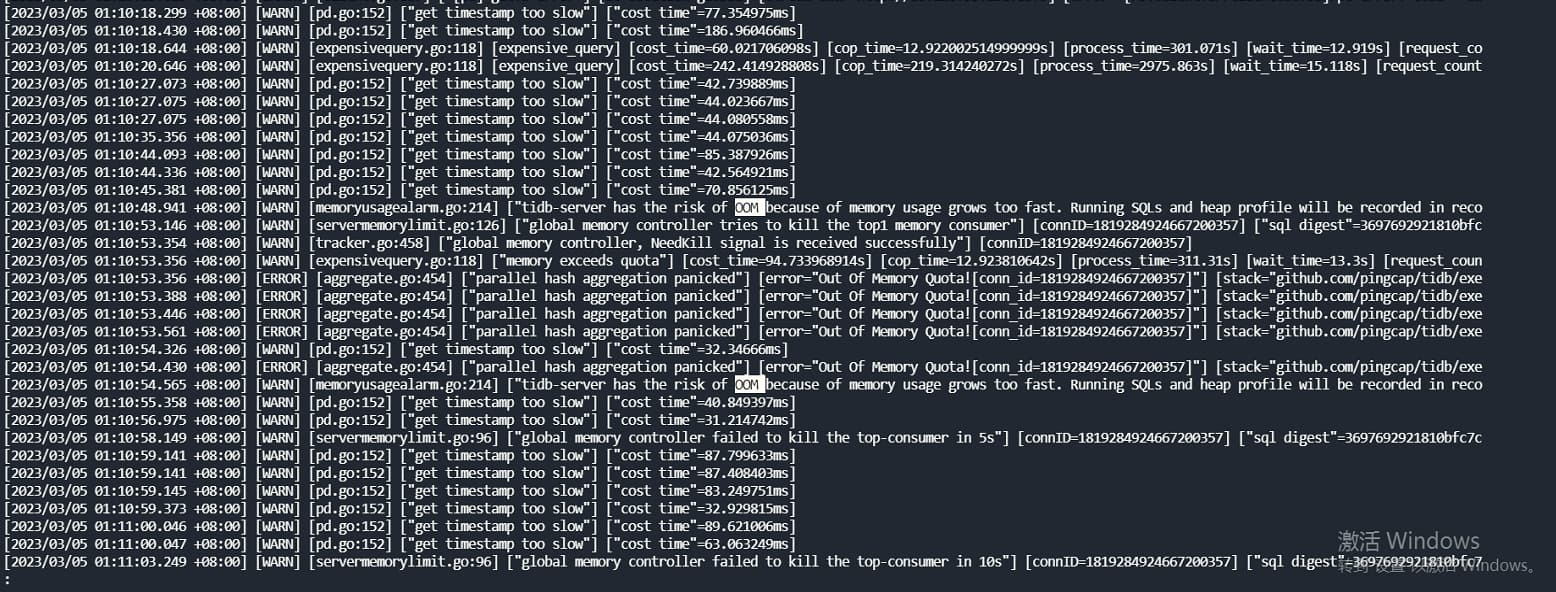
6.5不能杜绝oom导致的tidb-server重启,但是很大程度上减少了内存的使用(paging能力)以及对消耗内存高的SQL的global kill能力。但是需要注意的是:
1、当内存使用比较高的情况下,每次只会杀掉占用内存最多的一个SQL,每分钟一次,如果内存上涨比较快,且多个占用内存高的SQL同时跑,那么也有可能会导致OOM的情况。
2、如果系统内部发出了kill命令,但是响应不及时那么也会继续占用内存,导致实例oom,你这种场景可能遇到的就是kill不及时,在进入hashagg算子时候有一些场景目前测试是kill没那么及时。
你这里内存占用比较大应该是hashagg算子导致的,group by:dcdb.cr_trans_remain_mapping.ta_cfm_serial_no这里目测这个字段的重复度比较低导致大量内存中的分组聚合,需要进行规避:1、想办法不走hashagg,比如看是否能用streaagg代替;2、不采用默认的并发方式,给hashagg聚合算子设置单线程set global tidb_hashagg_final_concurrency=1;set global tidb_hashagg_partial_concurrency=1,同时开启落盘;但是要注意的是tidb目前的落盘处理性能比较差,参考这里:https://asktug.com/t/topic/994873,官方后续应该会对落盘进行优化。