【 TiDB 使用环境】压测
【 TiDB 版本】v4.0.6
【复现路径】原来6个tikv节点,现在新上3个同一物理机的tikv节点扩容,然后把原来6个tikv节点缩容。缩容时出于性能考虑,把region-schedule-limit、leader-schedule-limit都设置为0,让region和leader不参与评分均衡。
【遇到的问题:问题现象及影响】
新节点所在物理机硬盘占用比预计的要高,磁盘占用达到95%以后出现其中两个节点频繁disconnect现象。现在在其他物理机上新增2个节点,region-schedule-limit、leader-schedule-limit都设置1500,现象依然没有改善。
【资源配置】
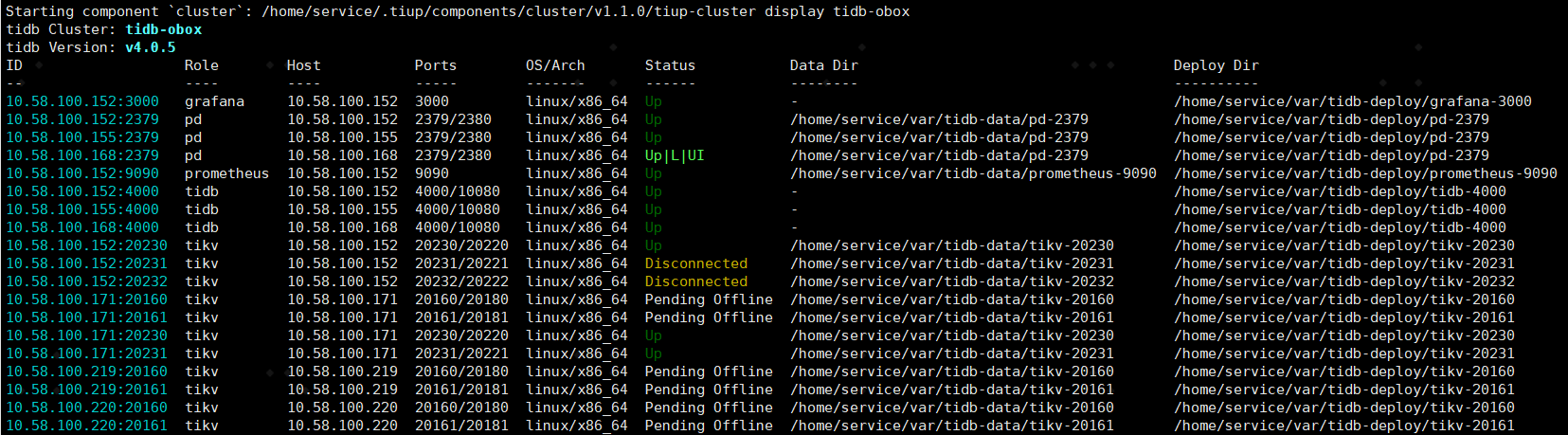
总共有6台机器,所有机器均为40C128G5T物理机。
10.58.100.152-20232.last.log.zip (1.3 MB)
10.58.100.152-20231.last.log.zip (1.5 MB)
