【 TiDB 使用环境】生产环境
【 TiDB 版本】4.0.9
【复现路径】
不太好复现,因为日志上看发生问题时select请求任务量和其它时间任务量相差不多,没有业务上的急剧激增一说
【遇到的问题:问题现象及影响】
影响:select性能急剧下降,select都是带索引的,一般走索引scan 100条性能大概在0.5s左右
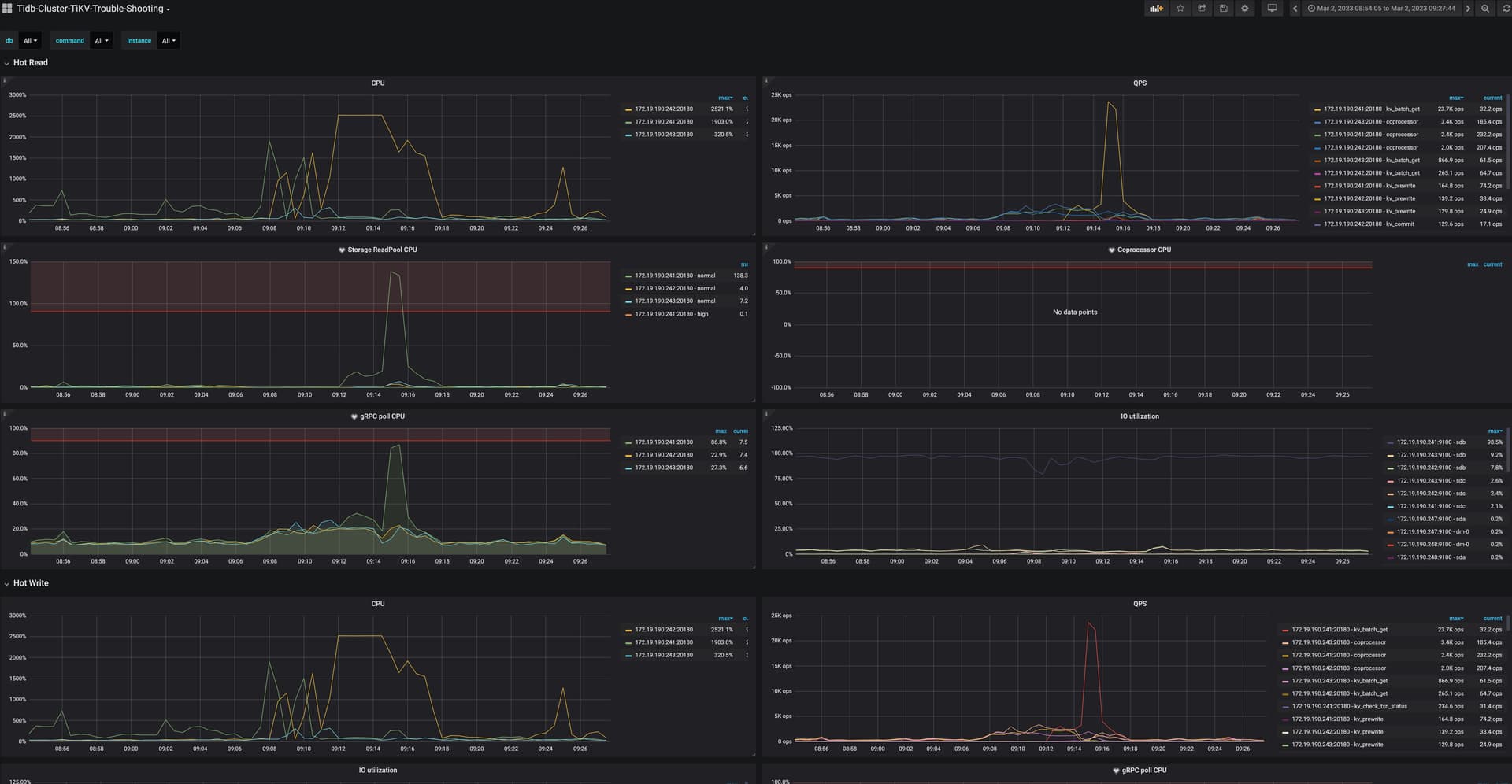
现象:监控上看其中一台TiKV的CPU急剧飙高,kv_batch_get的qps急剧增高,tikv的cpu高的机器上tikv_unified_read_pool_running_tasks指标突然变高。
大约过了5分钟后,集群恢复正常,监控指标恢复正常,中间无其他操作
【资源配置】
物理机,资源充裕
【附件:截图/日志/监控】
还需要什么监控能更详细的排查,请及时回复我,谢谢各位
你们的业务SQL是固定的吗?是不是有新业务上线?带来了新的未优化过的SQL?
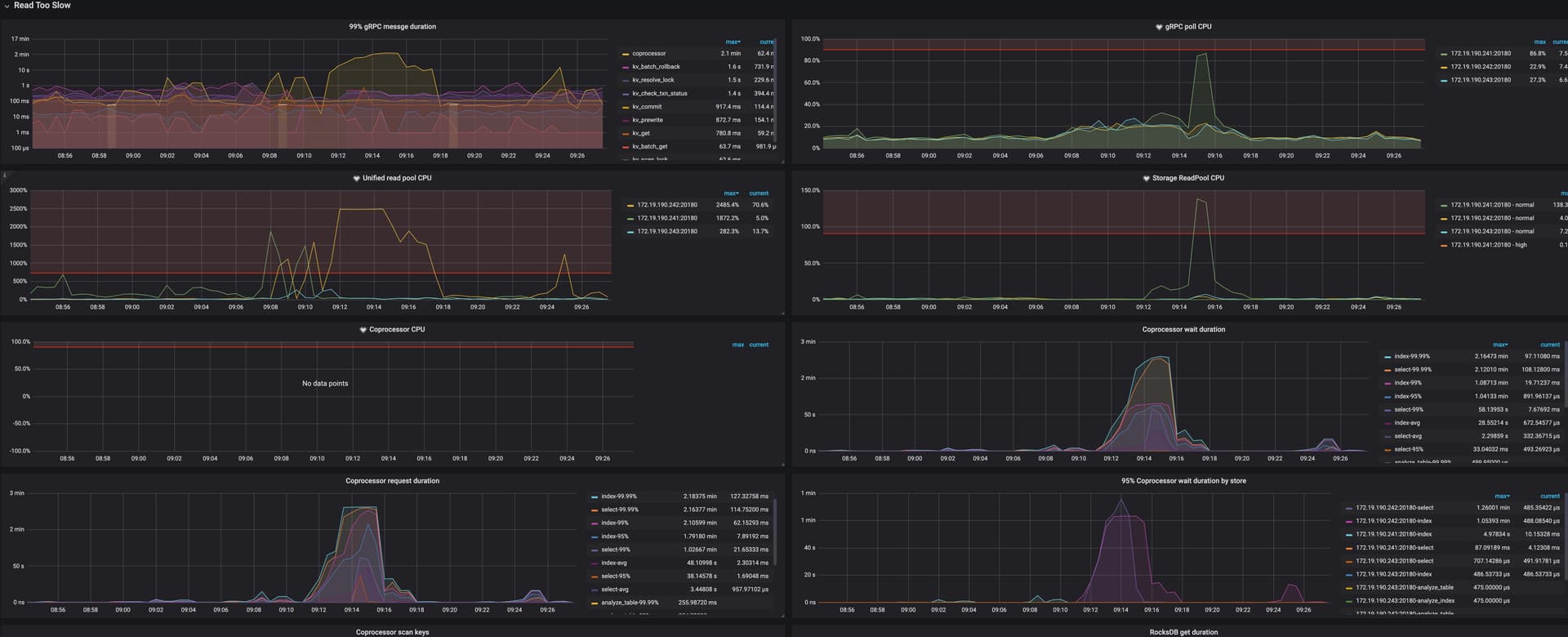
您好,慢sql看了,都是之前正常的sql查询,在其他时间段没有问题。。。但在有问题的时段,Cop时间出奇的高,一般0.5s能解决的,能飙到18-20s
Kongdom
(Kongdom)
7
dashboard的语句分析看看,时间段内有没有执行次数特别多的语句。感觉是有热点吧。
看看总的qps,是不是也增加了?还是降低了?
其中一个tikv的grpc是增加了很多。如果总的qps没增加,那有点不正常啊。
h5n1
(H5n1)
9
如果sql没变化 看看执行计划是不是有过变化贴一个sql信息看看,slow.log里的
监控上总的qps是增加了,但应该是处理速度慢导致的指标增加。业务上的日志统计出来,qps并没有差多少
那估计是sql执行计划变化导致的扫表吧,看coprocessor响应那么慢,估计是扫描的范围太大导致的吧。
检查下你说的日常很快的sql现在很慢了,看看执行计划是不是符合预期。
如果是执行计划变化导致的,找找官网手册,有绑定的方式。
ffeenn
(ThatBoy)
12
有时候并不一定是慢sql造成的, Overview 面板 有异常吗。
db_user
(Db User)
14
看下analyze相关;
show analyze status;
看看有没有失败状态的
show variables like;‘%analyze%’ 看看自动analyze的时间段;
在tidb.log中搜索data too long关键字看看是否有相关的表出现这种字样