【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【复现路径】使用load批量加载csv文件或者使用batch on id limit 10000 insert into t2 select * from t1导入
【遇到的问题:问题现象及影响】入库较慢,同样场景下gp性能是tidb的10倍左右,是否存在优化空间。
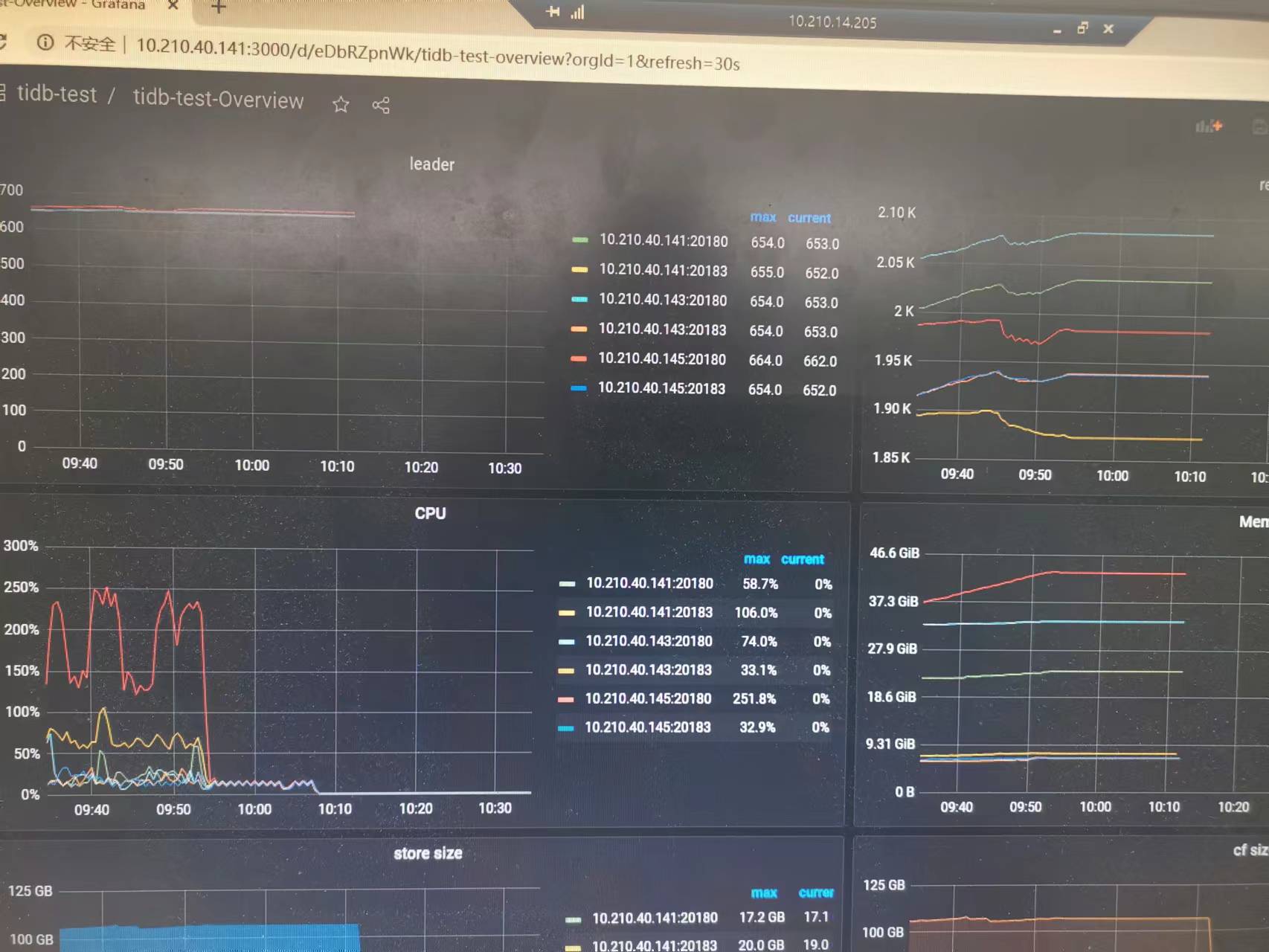
另外截图为通过监控查看tikv的cpu和mem,使用率差距较大(同ip的部署在同一节点),为什么会产生此类现象。
【资源配置】
【附件:截图/日志/监控】
表提前分片了吗?从文件一次性导入和insert into select * 速度是一样的?
如果是CSV文件的话,建议用tidb-lightning来搞,直接写tikv,速度飞快
我测试出来insert into 比 load 要快。分片不是自动做的么?
官方文档参考这里:https://docs.pingcap.com/zh/tidb/stable/tidb-lightning-configuration ,csv格式可以微调的还不少,基本上都能兼顾到
用了的,跟load差不多。性能也不行啊。
1、TiDB Lightning用的是local模式吗?(这种方式理论上是最快的)
2、预分片的话,能减少表自动分片的开销,节约时间
P.S:如果慢的话,可以把csv平均拆成多份,开并发,名称前缀相同即可,参考:https://docs.pingcap.com/zh/tidb/stable/get-started-with-tidb-lightning
不太可能,你用的不是直接写入TiKV的模式吧?可以看文档https://docs.pingcap.com/zh/tidb/stable/tidb-lightning-physical-import-mode ,我这里使用经验是,导入速度基本和tidb-lightning机器的CPU核数成正比
刚看了下,是使用的local模式。预分片和并发,我测测看。
那你tidb-lightning所在机器的配置如何?local模式对lightning机器的配置要求比较高,基本上配置越高导入速度越快
local模式就是你说的直接写入吧。我了解到的lighting实质也是分批load吧。刚好我测得两种结果一致的。
你现在的导入速度是多少?lightning日志上应该有显示,你的存储IO峰值理论能到多少?你期望能到多少?
实在不行,把csv文件直接拆成两份,前缀名一致,再用lightning开并发2导入,看看速度上去了没
没单独的机器,是部署在集群的一个节点上的。CPU肯定是没打满。
现在是2w/s。IO使用率只到20%。并发估计有效果,晚点验证下。batch on id limit 10000 insert into t2 select * from t1,这个可以咋优化呢。
我建议用lightning全部导出来再导进新表,这样最快;
insert into t2 select * 这种方式之前在其他数据库遇到过,非常慢,大概原理是因为是一行一行处理数据的(类似游标),不知道tidb是不是也是这样的?(处理方式也是批量导出到本地再导入)
使用 load data 的时候最好指定一下 tidb_dml_batch_size ,设置 tidb_dml_batch_size = 20000
batch dml其实效率很低的,这个主要是为了避免大事务超过TiDB内存默认限制,还比不上自己划分chunk多起几个select into快
有效果,能到3w/s。对比下来,还是差得多。
现在你还是单线程在load data,把文件拆批,多开几个load data 速度就起来了。
逻辑单线程导入 3w/s已经挺高了,我的基本都是2w/s ![]()
tidb得多开点并发才能快。或者用lightning的local模式快很多。如果你在tidb的processlist上能看到SQL语句那就不是local模式。