【 TiDB 使用环境】生产环境
【 TiDB 版本】6.5.0
现在我们数据库需要从阿里云迁移到华为云,文档里面有相关的方案,但是有一些不明白的地方请教一下大家
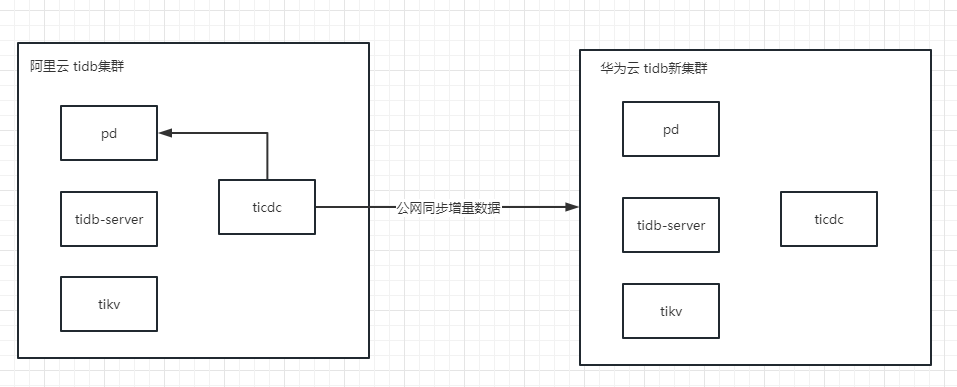
这里我对ticdc部署在源端tidb还是目标端这个问题比较疑惑
方案一:ticdc部署在源端, --sink-uri= 填目标端的公网ip地址进行同步,这个方案我试过了,数据虽然能同步,但是速度非常慢。
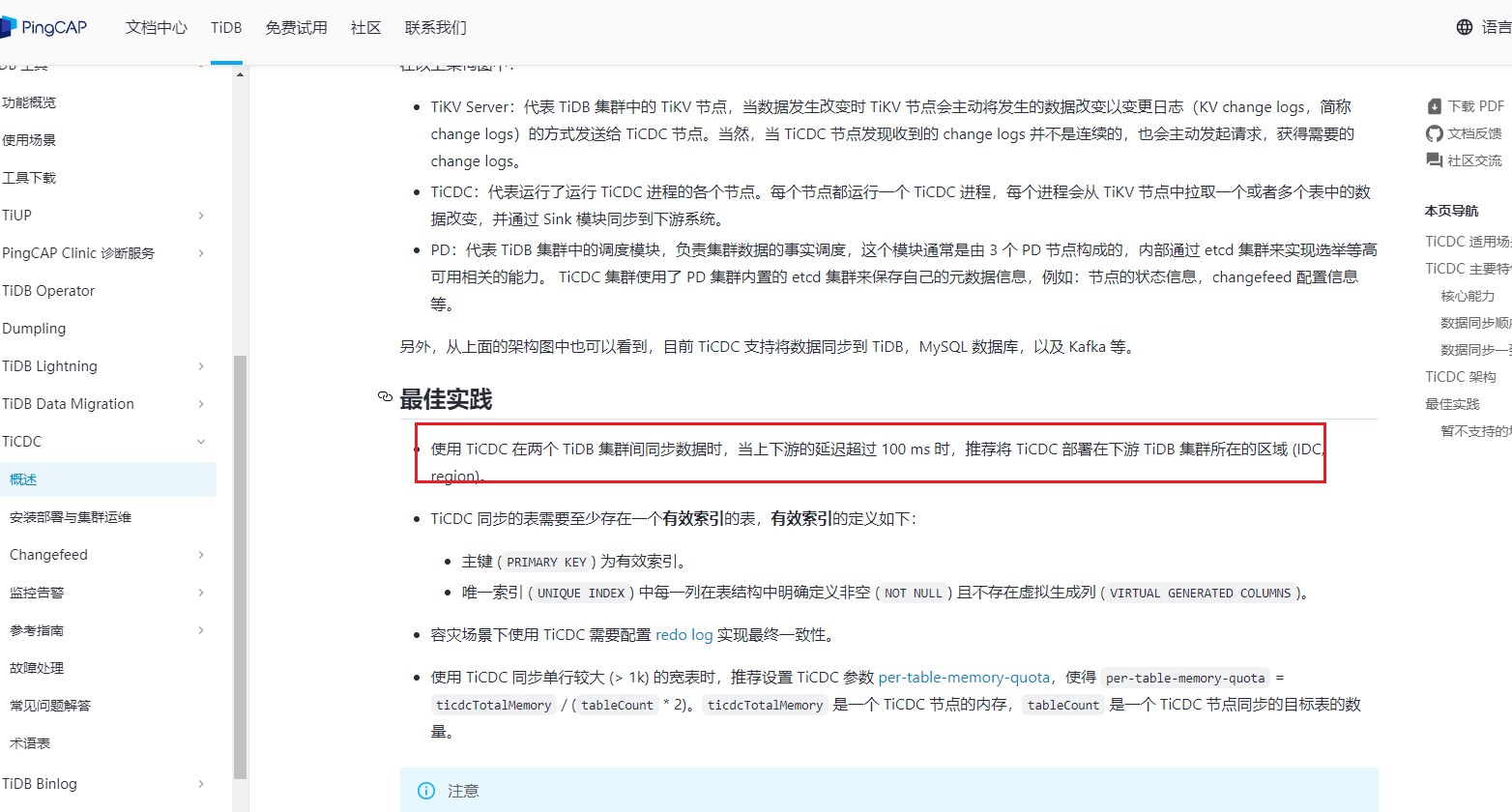
方案二:按照文档的最佳实践说明,将ticdc部署在目标端,–sink-uri= 填写目标端的内网ip地址
但是这个方案我不太明白,公网同步的时候我ticdc如果部署在目标端,怎么拉到源端的数据呢,而且两边的pd保存的都是各自内网的ip关系,请求不出去。
麻烦大佬们指点一下方案,谢谢
文档的意思是cdc的服务器放在目标端的网段中,cdc的实例还是部署在源端tidb集群里。
因为目标端在另外一个云,如果ticdc实例归在原端tidb集群里管理,那他拿到原端pd tikv节点的IP都是内网IP,到时候怎么能访问的了呢
ticdc跨公网的话,如果源端没开外网访问,但是能访问外网,那只能部署在源端,因为你部署在目标端无法访问源端,如果源端也能通过外网访问,那肯定是部署在目标端,但是跨外网的话,看你带宽有多大了,同步速度收带宽所限。
源端和目标端都能外网访问。如果ticdc部署在目标端机房但集群拓扑归属于源端,也就是pd使用源端的pd,那ticdc拿到源端的pd,kv的ip应该是内网ip,迁移的时候相当于目标端机房的ticdc用内网ip访问,好像也没办法拉到源端tikv的数据。
tiup ctl:v6.5.0 cdc changefeed create --server=http://xxx.xxx.50.118:8300 --sink-uri="mysql://root:youmai456@192.168.0.101:4000" --changefeed-id="mall-task1" --start-ts="439701707253350615"
这里我尝试过–server=使用目标端ticdc的外网ip,–sink-uri=输出到目标端内网ip的tidb集群,最终在–start-ts=这步报错,ticdc拿不到源端之前记录的时间点进行增量同步。
确实,跨公网ticdc部署在目标端无法获取到本地tikv的变化数据了,pd倒是可以指定为pd的外网ip和端口,然后在阿里云的安全组中开放一下pd的ip和端口给ticdc。。。
这个操作我也试过了,我尝试扩容一个公网的pd想给ticdc来用,结果原端集群直接炸了,我还把生产给搞崩了。看这个帖子:救急!!!,生产集群崩了,pd没办法选举.
你现在两个集群不是部署在阿里云和华为云的ecs上吗?每个ecs应该能开放外网ip加端口的,但是你部署的时候肯定是要以内网ip来进行部署的,因为网络延迟低,所以你现在只能在源端(阿里云)部署ticdc然后连接到目标端(华为云)进行同步了,部署在目标端(华为云)的话,虽然ticdc能够连接到源端(阿里云)的pd的外网ip,但是连接不到tikv的内网ip,所以确实第二种方法是行不通了。。。
这种方案传输是OK的,但是cdc输出端垮了公网,速度非常慢的,基本类似于同步不出去(公网宽带都有100M),所以也是不可用的。
大佬还有其他的迁移办法吗
上游和下游tidb集群都是用内网ip部署的,请教下怎么能让ticdc能访问到所有 TiKV 和 PD呢
用阿里云的dts 同步到华为云的mysql 或tidb
看了一下,阿里云DTS居然支持同步tidb了,这个好像挺少人用的,你那边有试过成功的吗
dba-kit
(张天师)
17
对数据的同步周期有要求么?如果是6.5.0的话,其实也可以考虑通过OSS来搞,通过PiTR把增量更新同步到OSS上,阿里云周期性的应用一下增量日志。不过这种方案适合做一次性的数据切换,但是做不了常态的热备。
我看了下,算间接支持支持了。利用Pump 和 Drainer输出到kafka,DTS消费kafka再输出到目标端
1 个赞
要不断的做增量同步,等业务切割完检查再没有增量同步后就结束了。我试下这方案行不行
dba-kit
(张天师)
20
PiTR和TiCDC一样,都可以保证RPO完全不丢数据,就是RTO有些长,需要每隔一段时间来应用changelog,对业务验证读是可以了。唯一缺点是读写得一起切换过去,没办法先切读,后切写。