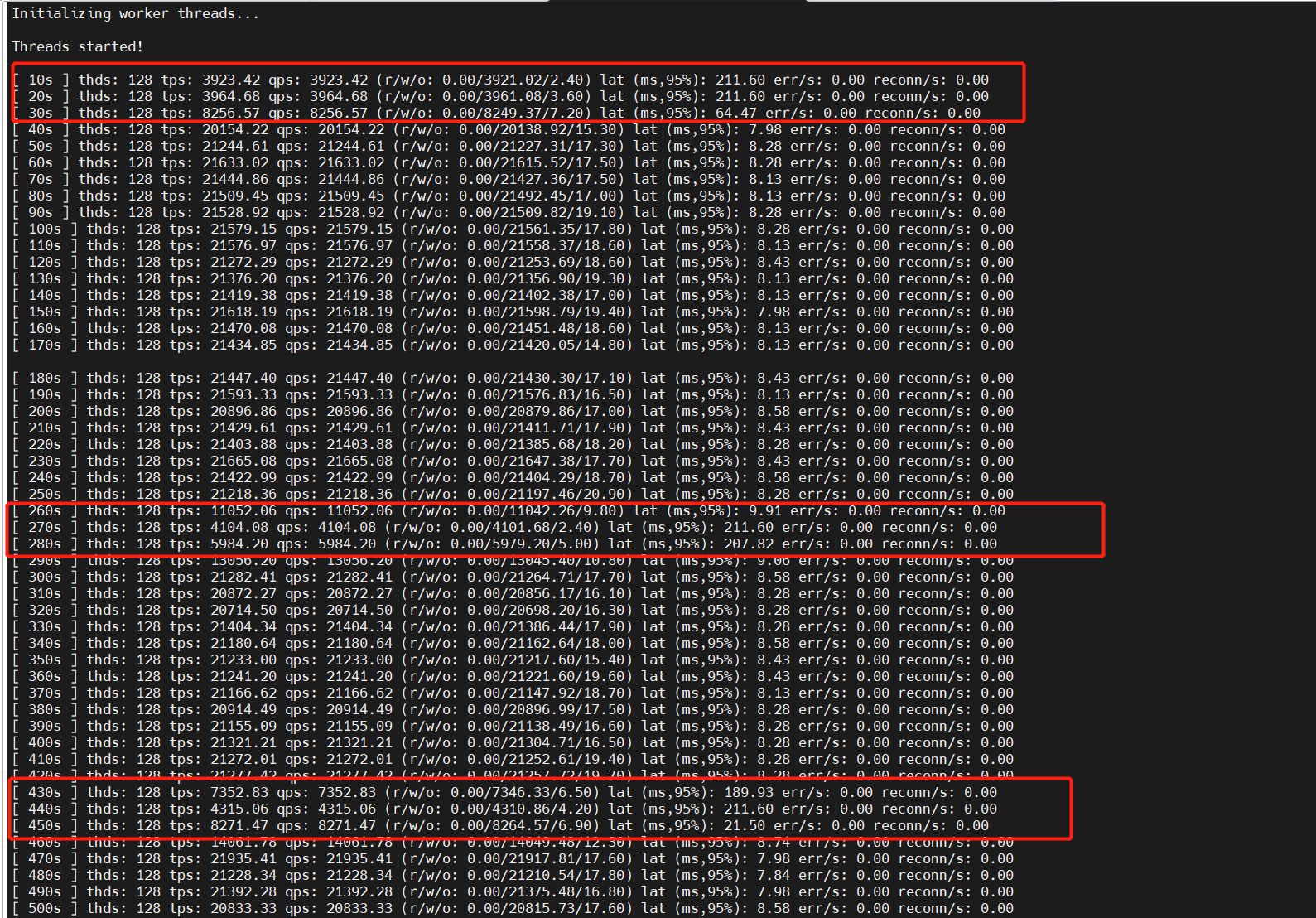
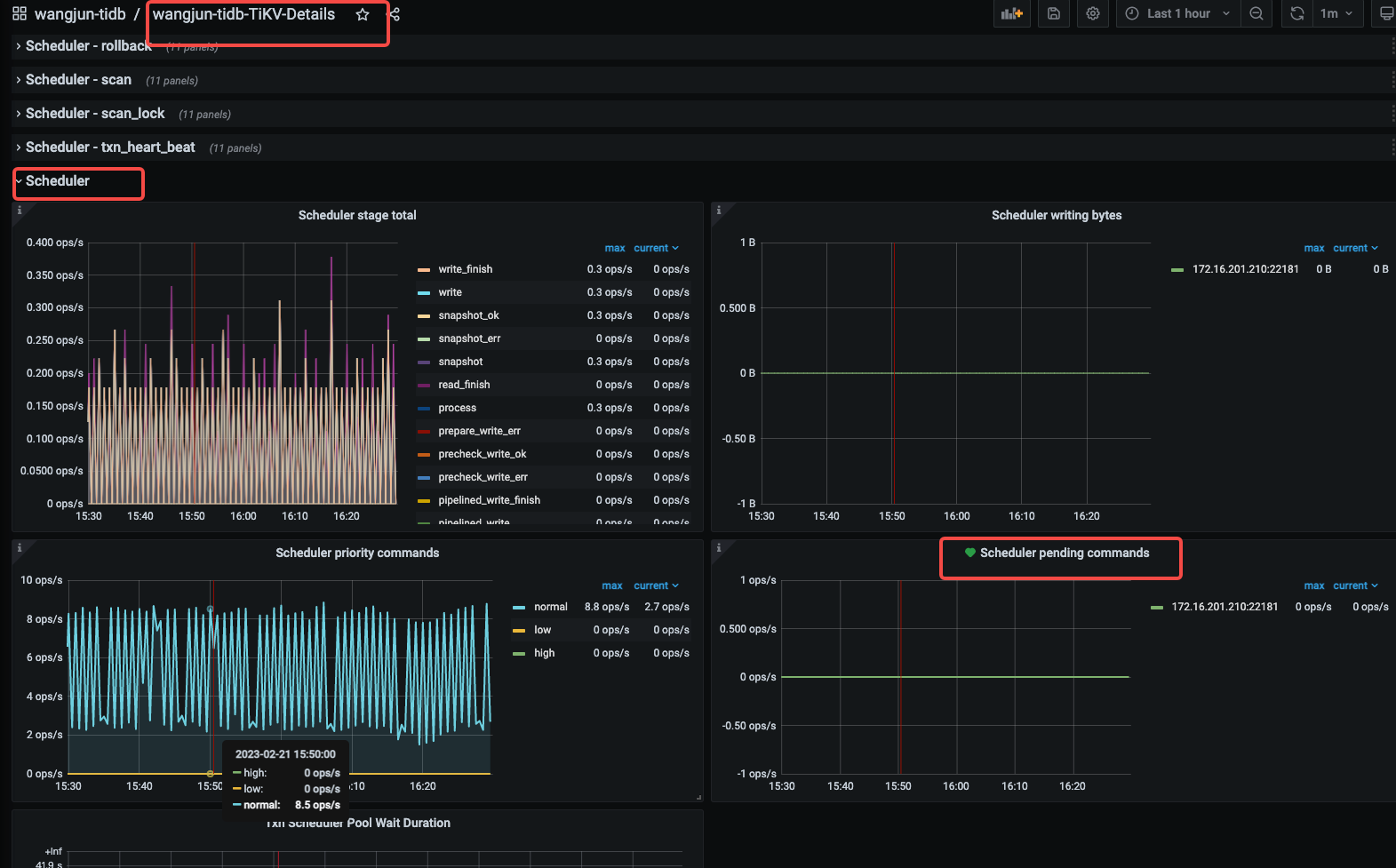
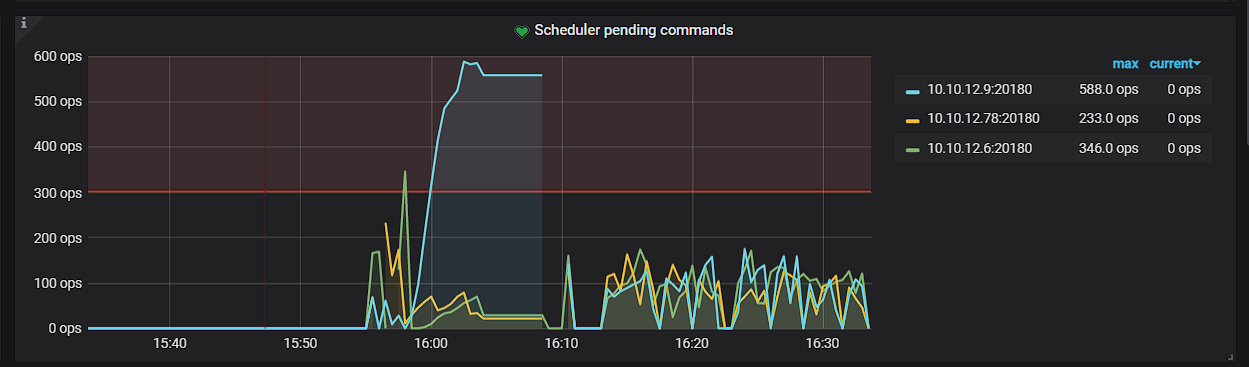
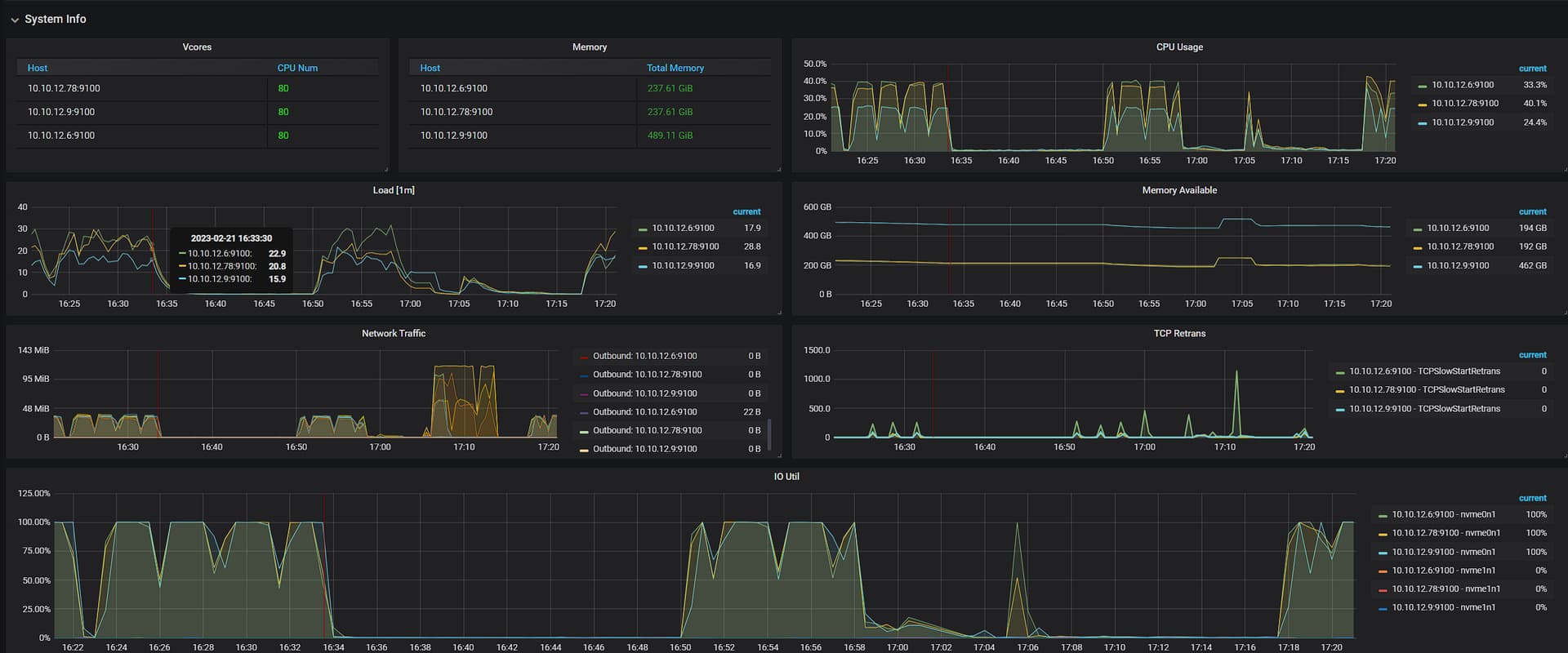
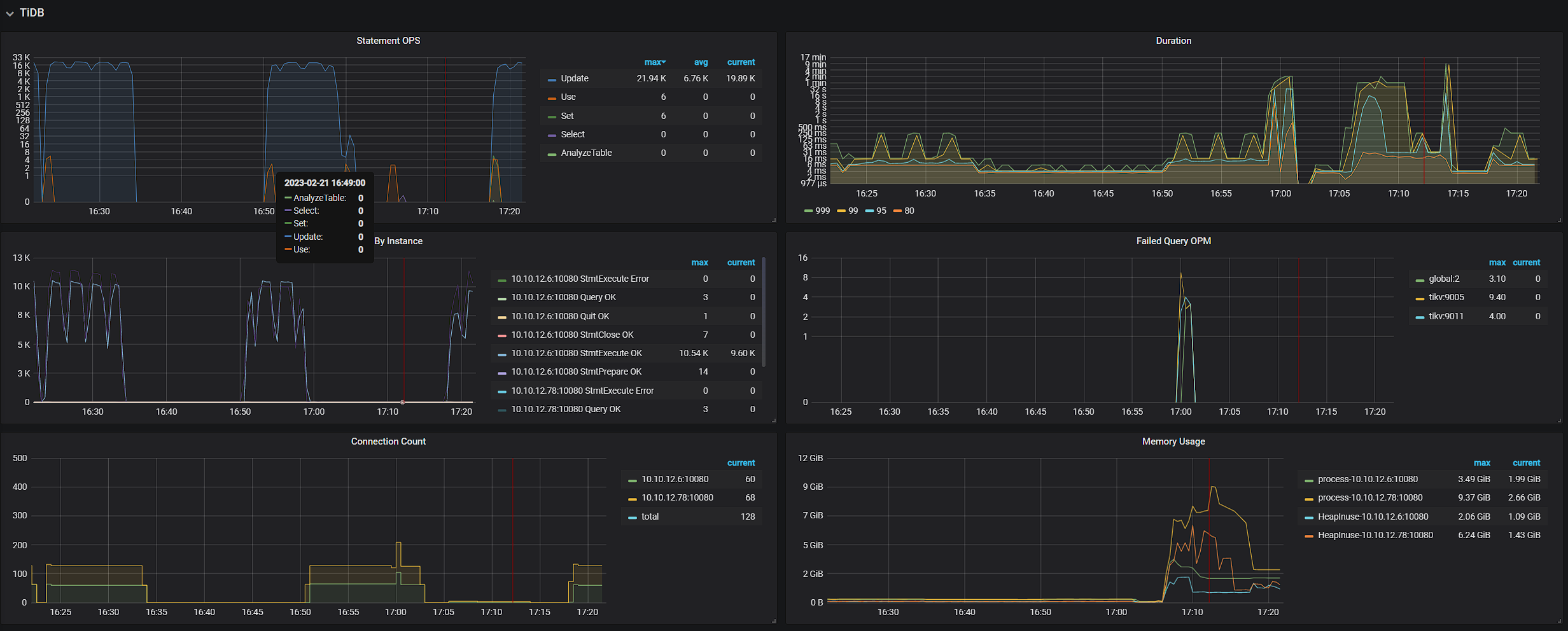
在搭建集群后利用Sysbench进行测试,读测试(point_select)可以正常进行,写测试(index_update)遇到报错
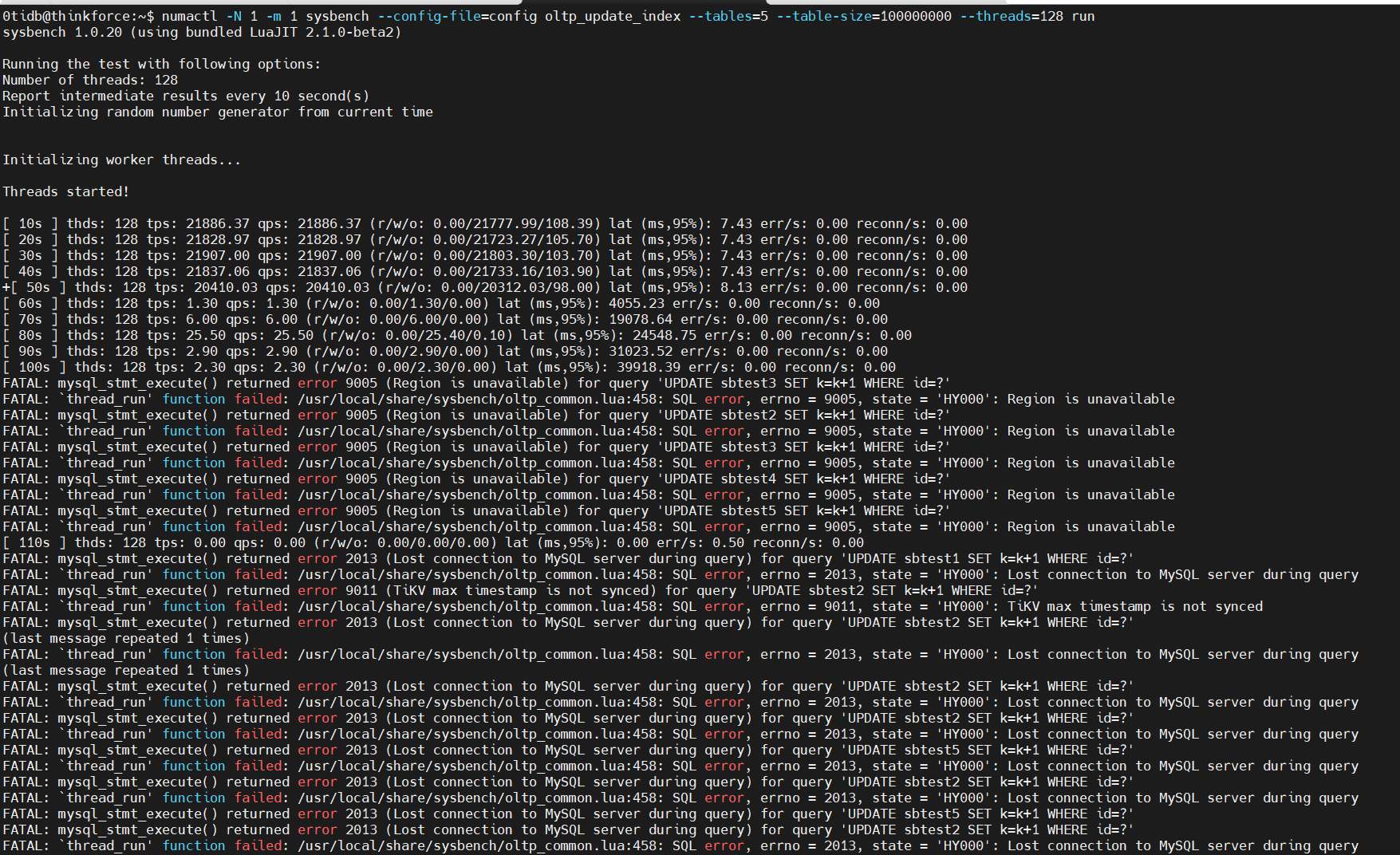

感觉一致性好像出了问题,想问问大佬们应该如何解决?
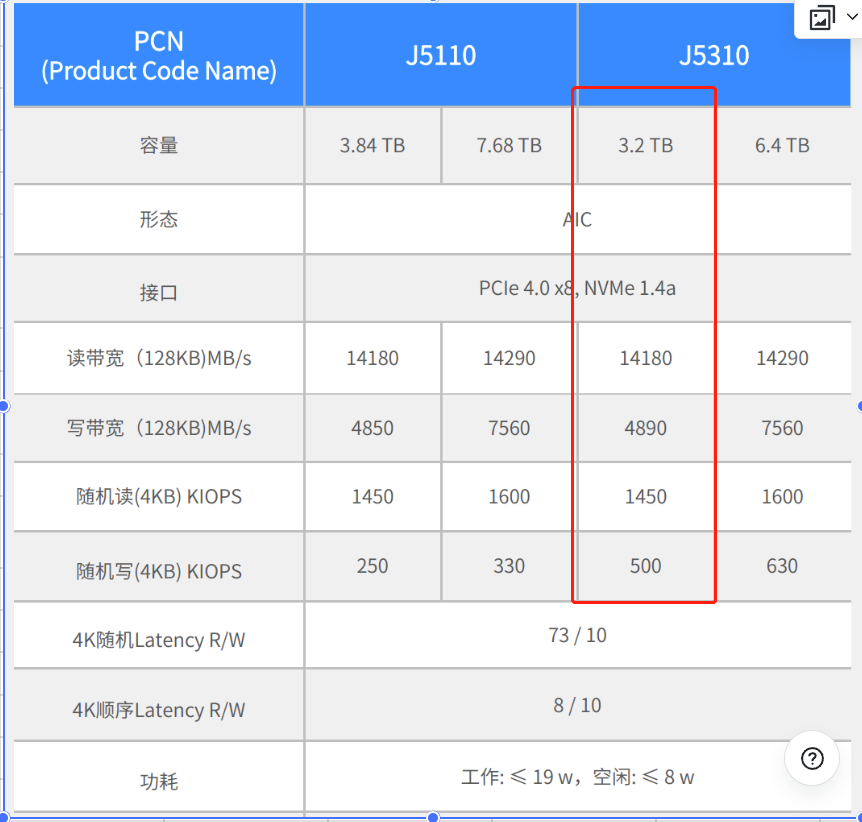
硬件配置:3台: arm处理器(2×40c 2.5GHz) 内存:32GB×8 硬盘:500G SSD / dapustor 3.2T
| 集群拓扑 | 10.10.12.6 | 10.10.12.78 | 10.10.12.9 |
|---|---|---|---|
| numa 0 | TiKV、PD | TiKV、PD | TiKV 、PD |
| numa 1 | TiDB | TiDB | Haproxy、Sysbench |
Tidb配置项:
server_configs:
tidb:
log.level: error
mem-quota-query: 34359738368
performance.server-memory-quota: 34359738368
performance.txn-total-size-limit: 10485760000
prepared-plan-cache.enabled: true
token-limit: 3001
tikv:
coprocessor.split-region-on-table: false
log-level: error
raftdb.max-background-jobs: 12
raftstore.apply-max-batch-size: 1024
raftstore.apply-pool-size: 8
raftstore.hibernate-regions: true
raftstore.raft-max-inflight-msgs: 1024
raftstore.store-max-batch-size: 1024
raftstore.store-pool-size: 4
rocksdb.compaction-readahead-size: 2MB
rocksdb.defaultcf.max-write-buffer-number: 32
rocksdb.writecf.max-write-buffer-number: 32
server.grpc-concurrency: 8
server.max-grpc-send-msg-len: 5242880
storage.block-cache.capacity: 64G
storage.scheduler-worker-pool-size: 8