【 TiDB 使用环境】生产环境 /测试/ Poc
生产环境
【 TiDB 版本】
v6.5.0
【复现路径】做过哪些操作出现的问题
不知道如何复现。
【遇到的问题:问题现象及影响】
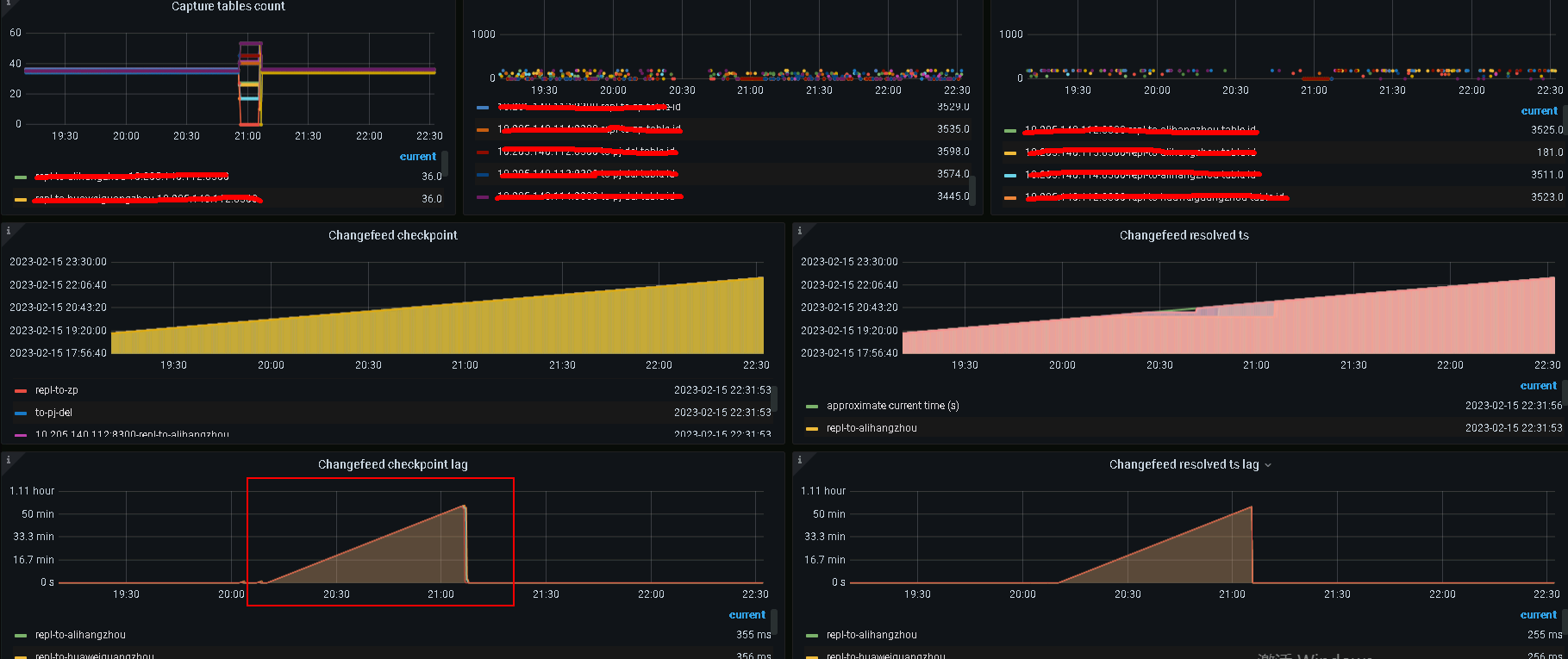
现象:平时间基本没什么延迟。最长的也就1min钟。但是ticdc偶尔出现长时间的延迟,checkpointLag一直增大。重启ticdc后。延迟又立马消失。
[2023/02/15 20:31:30.208 +08:00] [INFO] [replication_manager.go:551] ["schedulerv3: slow table"] [namespace=default] [changefeed=repl-to-tenxunguangzhou] [ta
bleID=2873] [tableStatus="region_count:10 current_ts:439475054874722304 stage_checkpoints:<key:\"puller-egress\" value:<checkpoint_ts:439474753250787343 reso
lved_ts:439474716537520134 > > stage_checkpoints:<key:\"puller-ingress\" value:<checkpoint_ts:439474753250787343 resolved_ts:439475054834876421 > > stage_che
ckpoints:<key:\"sink\" value:<checkpoint_ts:439474716537520134 resolved_ts:439474716537520134 > > stage_checkpoints:<key:\"sorter-egress\" value:<checkpoint_
ts:439474716537520134 resolved_ts:439474716537520134 > > stage_checkpoints:<key:\"sorter-ingress\" value:<checkpoint_ts:439474753250787343 resolved_ts:439474
716537520134 > > barrier_ts:439475054834876418 "] [checkpointTs=439474716537520134] [resolvedTs=439474716537520134] [checkpointLag=21m30.706968307s]
[2023/02/15 20:31:30.209 +08:00] [INFO] [replication_manager.go:551] ["schedulerv3: slow table"] [namespace=default] [changefeed=repl-to-zp] [tableID=3082] [
tableStatus="region_count:1 current_ts:439475054887567360 stage_checkpoints:<key:\"puller-egress\" value:<checkpoint_ts:439474977803337743 resolved_ts:439474
977803337743 > > stage_checkpoints:<key:\"puller-ingress\" value:<checkpoint_ts:439474977803337743 resolved_ts:439474977803337743 > > stage_checkpoints:<key:
\"sink\" value:<checkpoint_ts:439474977737801745 resolved_ts:439474977737801745 > > stage_checkpoints:<key:\"sorter-egress\" value:<checkpoint_ts:43947497773
7801745 resolved_ts:439474977737801745 > > stage_checkpoints:<key:\"sorter-ingress\" value:<checkpoint_ts:439474977737801745 resolved_ts:439474977737801745 >
> barrier_ts:439475054834876418 "] [checkpointTs=439474977737801745] [resolvedTs=439474977803337743] [checkpointLag=4m54.307444085s]
[2023/02/15 20:31:30.209 +08:00] [INFO] [replication_manager.go:551] ["schedulerv3: slow table"] [namespace=default] [changefeed=repl-to-zp] [tableID=3040] [
tableStatus="region_count:1 current_ts:439475054888091648 stage_checkpoints:<key:\"puller-egress\" value:<checkpoint_ts:439474977803337743 resolved_ts:439474
977803337743 > > stage_checkpoints:<key:\"puller-ingress\" value:<checkpoint_ts:439474977803337743 resolved_ts:439474977803337743 > > stage_checkpoints:<key:
\"sink\" value:<checkpoint_ts:439474977737801745 resolved_ts:439474977737801745 > > stage_checkpoints:<key:\"sorter-egress\" value:<checkpoint_ts:43947497773
7801745 resolved_ts:439474977737801745 > > stage_checkpoints:<key:\"sorter-ingress\" value:<checkpoint_ts:439474977737801745 resolved_ts:439474977737801745 >
> barrier_ts:439475054834876418 "] [checkpointTs=439474977737801745] [resolvedTs=439474977803337743] [checkpointLag=4m54.307444085s]
[2023/02/15 20:31:30.209 +08:00] [INFO] [replication_manager.go:551] ["schedulerv3: slow table"] [namespace=default] [changefeed=repl-to-zp] [tableID=2887] [
tableStatus="region_count:5 current_ts:439475054887567360 stage_checkpoints:<key:\"puller-egress\" value:<checkpoint_ts:439474753250787343 resolved_ts:439474
732082659333 > > stage_checkpoints:<key:\"puller-ingress\" value:<checkpoint_ts:439474753250787343 resolved_ts:439475054873673746 > > stage_checkpoints:<key:
\"sink\" value:<checkpoint_ts:439474732082659333 resolved_ts:439474732082659333 > > stage_checkpoints:<key:\"sorter-egress\" value:<checkpoint_ts:43947473208
2659333 resolved_ts:439474732082659333 > > stage_checkpoints:<key:\"sorter-ingress\" value:<checkpoint_ts:439474753250787343 resolved_ts:439474732082659333 >
> barrier_ts:439475054834876418 "] [checkpointTs=439474732082659333] [resolvedTs=439474732082659333] [checkpointLag=20m31.407444085s]
【资源配置】
cdc.zip (612.6 KB)
【附件:截图/日志/监控】
附件日志为cdc owner 2023/02/15 20:00到21:20的日志