为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【概述】 按天分区,每天千万级数据量,使用tispark读取,越跑越慢
【应用框架及开发适配业务逻辑】tispak 方式连接到tidb ,通过写sql获取tidb数据表取数。tidb数据表使用默认方式。
【背景】 该tidb数据表,使用spark jdbc append方式写入。并使用tispark方式读取使用。写入与读取是两套代码。
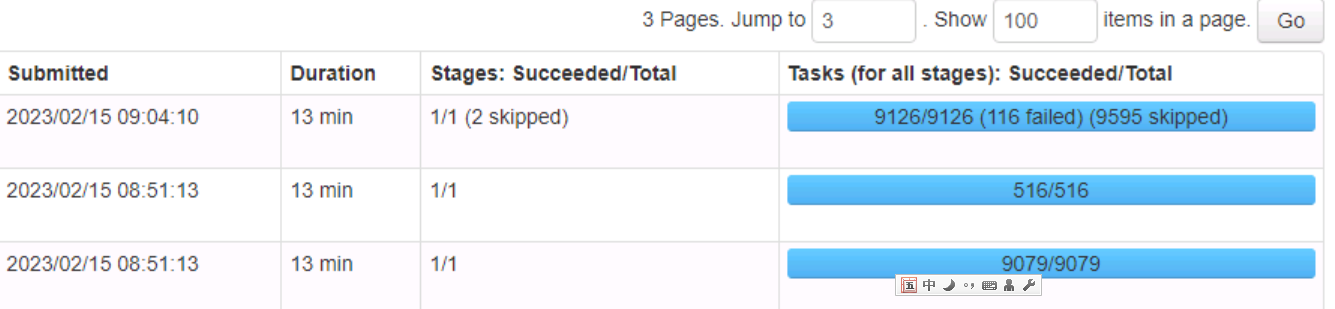
【现象】 spark管理页面的task 由一开始的2000个,逐步上升到9000个。在资源不变的情况下,越跑越慢。
1亿条数据,大概25G的样子,使用tisprark 写sql 读取到spark中 现在大概需要12分钟。
【问题】 每10分钟读一次,大概不到两天的数据量,使用时间字段取数(不超过两天,最近两天),跑了半年,为啥spark的计算任务(task),越来越多?
【业务影响】
【TiDB 版本】 5.7.25-TiDB-v5.2.1
【附件】
tidb 建表语句:
CREATE TABLE final_result_tabl1 (
col1 varchar(100) DEFAULT NULL,
col2 varchar(100) DEFAULT NULL,
col3 varchar(100) DEFAULT NULL,
…
createTime timestamp NULL DEFAULT NULL,
KEY index_a (createTime),
KEY index_b (createTime,col1),
KEY index_c (createTime,col2),
KEY index_d (createTime,col1,col2)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT=‘********’
PARTITION BY RANGE ( UNIX_TIMESTAMP(createTime) ) (
PARTITION 20220201_09 VALUES LESS THAN (1643677200),
PARTITION 20220202_09 VALUES LESS THAN (1643763600),
PARTITION 20220203_09 VALUES LESS THAN (1643850000),
…
PARTITION 20230101 VALUES LESS THAN (1672588800),
PARTITION 20230102 VALUES LESS THAN (1672675200),
PARTITION 20230103 VALUES LESS THAN (1672761600)
)
;