【 TiDB 使用环境】生产环境
【 TiDB 版本】6.5.0
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
Top SQL 模块点开就报 502 错误,看了下是 /top/instance 这个接口直接 502 了。同时也想问一下 DashBoard 日志目录在哪里,一直没有找到
【资源配置】
【附件:截图/日志/监控】
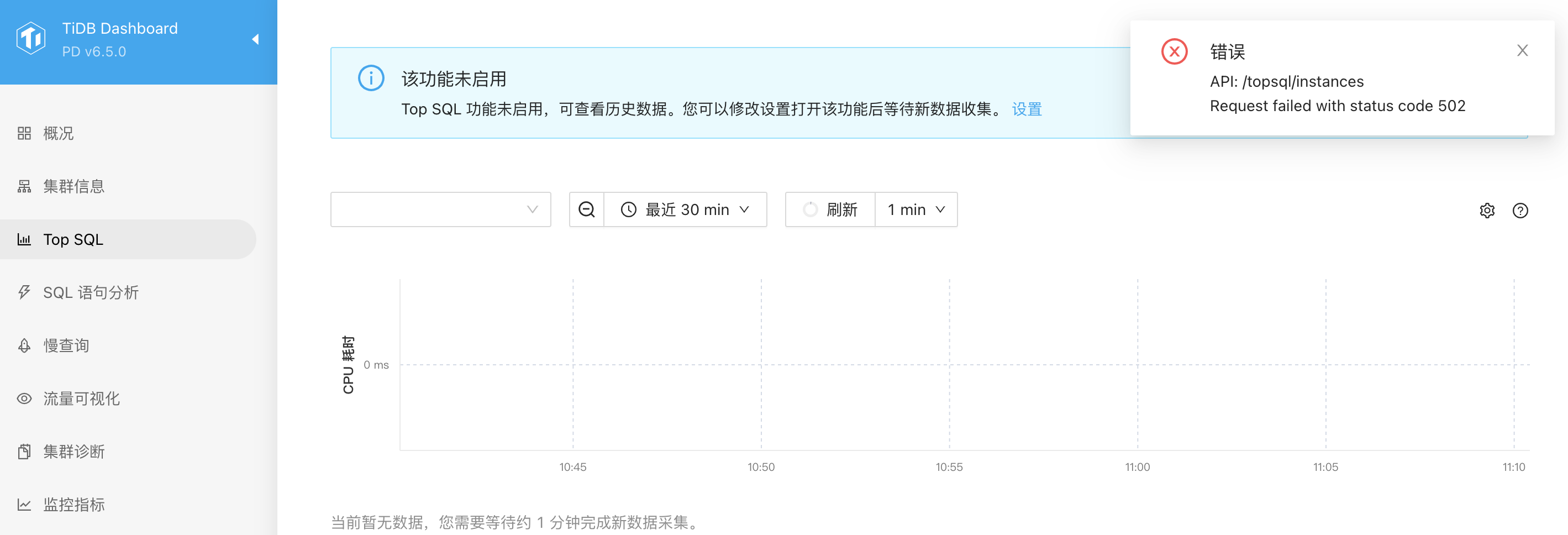
你点击一下设置看看,
相关的文档可见:
https://docs.pingcap.com/zh/tidb/stable/top-sql
要使用 Top SQL,你需要使用 TiUP(v1.9.0 及以上版本)或 TiDB Operator(v1.3.0 及以上版本)部署或升级集群。如果你已经使用旧版本 TiUP 或 TiDB Operator 进行了集群升级,请参见 FAQ 进行处理。
Top SQL 开启后会对集群性能产生轻微的影响(平均 3% 以内),因此该功能默认关闭。你可以通过以下方法启用 Top SQL:
- 访问 Top SQL 页面。
- 点击打开设置 (Open Settings)。在右侧设置 (Settings) 页面,将启用特性 (Enable Feature) 下方的开关打开。
- 点击保存 (Save)。
你仅能看到开启功能之后的 CPU 负载细节情况,在开启功能之前的 CPU 负载细节无法在界面上呈现。另外,数据有至多 1 分钟左右的延迟,因此你可能需要等待片刻才能看到数据。
除了通过图形化界面以外,你也可以配置 TiDB 系统变量 tidb_enable_top_sql 来启用 Top SQL 功能:
SET GLOBAL tidb_enable_top_sql = 1;
cluster 和 components 版本均为最新版本,现在是点进 Top SQL 模块就报错,没有其他的操作
该功能默认关闭。你可以通过以下方法启用 Top SQL:
- 访问 Top SQL 页面。
- 点击打开设置 (Open Settings)。在右侧设置 (Settings) 页面,将启用特性 (Enable Feature) 下方的开关打开。
- 点击保存 (Save)。
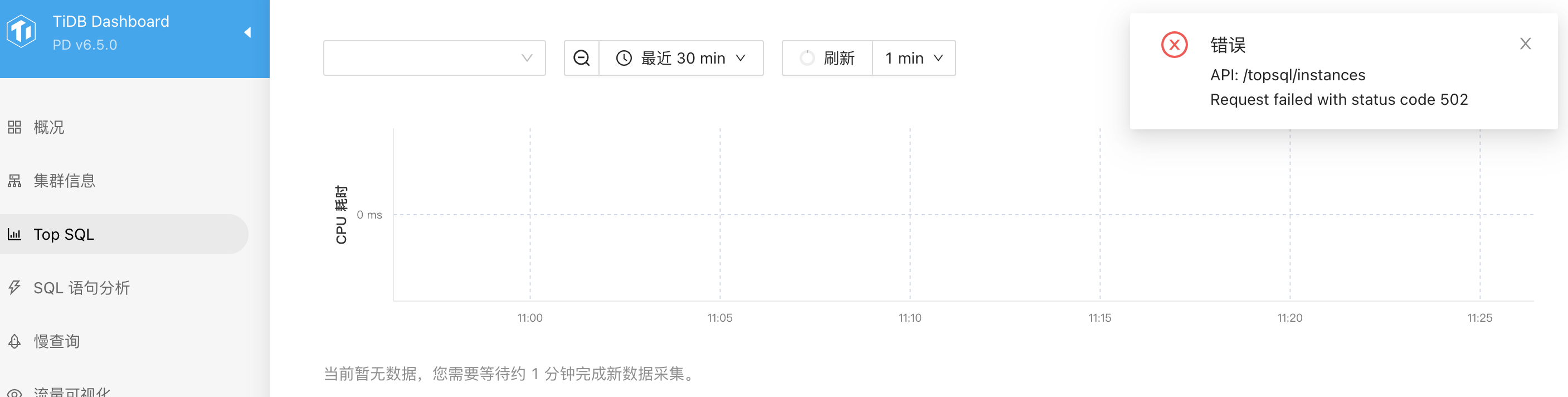
是正常启动的,但是 ng-monitoring-server 状态是 sleep。我另一个Top SQL 功能正常的集群,这个进程也是 sleep 状态
重启一下 Dashboard所在pd试试
单个pd重启,集群reload、restart,destroy 之后重装都不能解决这个问题。开始我觉得可能是服务器通信的某个端口出现问题了,但是安装的时候也没有任何报错。通过 postmasn 直接访问 Top SQL 报 502 的接口,不加 bearer token 的情况下也能返回 401,又证明了请求是能正常打到对应服务器的。 ![]()
重启下 prom 节点试试看
能看下 您访问的PD 节点的报错日志吗 ??? PD的日志。您点击下 看看
我这从6.1升级到6.5测试了下,没问题。6.5的PD可以使用
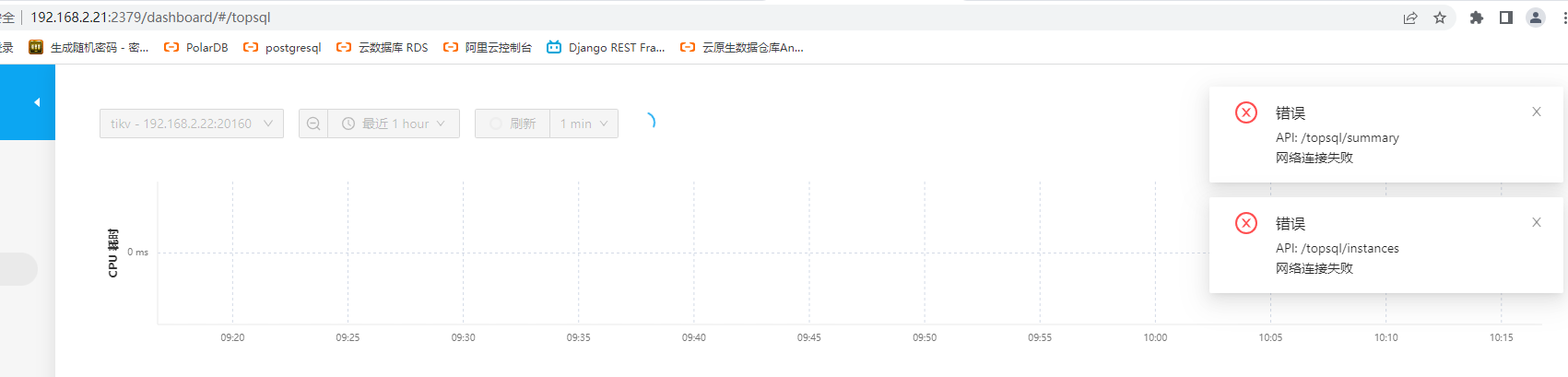
我这模拟了一下您的错误。dashboard这个地址 没有实现负载均衡能力,仅仅一个PD节点提供这个能力。
表现是:您访问 21 22 23IP的地址都会被 转发到 一个PD节点上。 top SQL 下面使用的是sqllite数据库。可能这个数据库出现问题了
监控机节点重启,pd节点重启目前都没用 ![]()
我也是从6.1升到6.5的,这个报错依旧没解决
错误还不太一样,你这个删除文件之后是通信失败,我这个是通信成功。因为通过 postman 模拟请求,不带 bearer token 的情况下,会提示 401,所以错误应该出现在接口请求后面的逻辑里,(比如某个服务挂掉,但是日志并没有对应的 ERROR 错误)我看看 dashboard 的源码逻辑吧,感谢回答 ![]()
生产环境,只不过是虚拟机模拟的多台机器。测试集群都是实体机倒是没出现过这种问题。
我的意思是dashboard的功能仅仅就是个监控。 何不干掉重新搞下呢。 这种分布式数据库架构都实现了高可用。
-
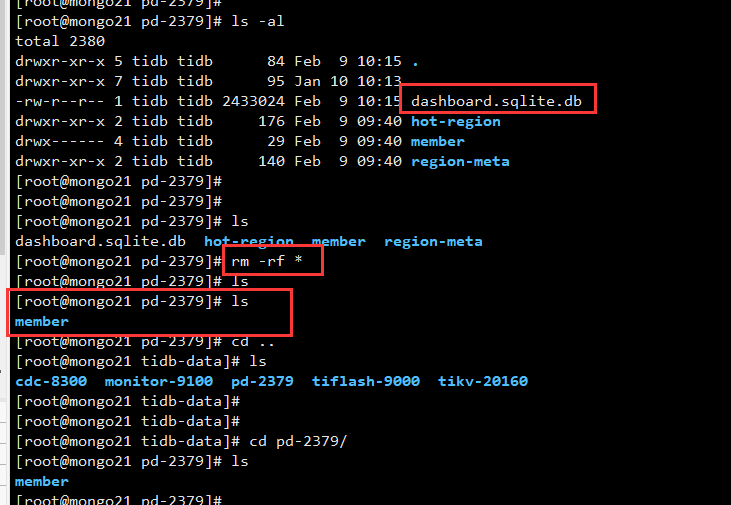
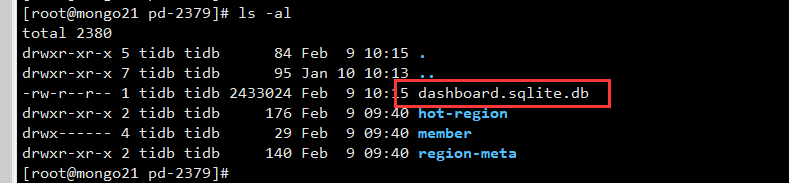
删掉dashboard的数据文件,我删除的是PD数据目录下的所有文件。 数据文件只会存在一个pd节点上.
不同pd的访问节点都会 转到这个包含dashboard的数据文件的PD上
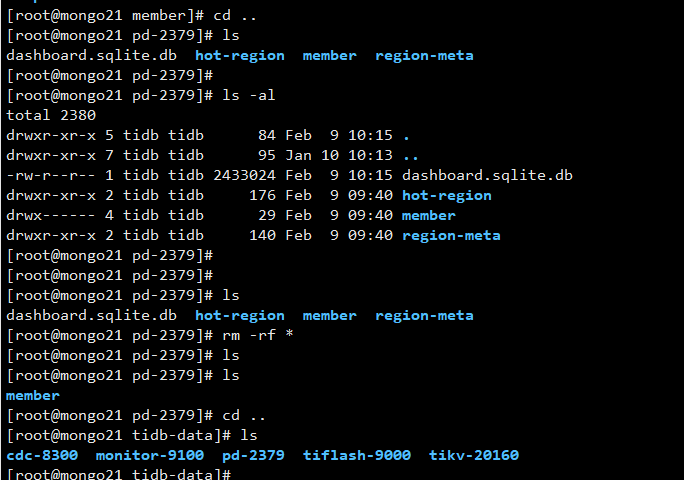
-
查看集群状态
-
检查dashboard:此时各种报错
-
移除错误的节点
tiup cluster scale-in tpln_qa --node 192.168.2.21:2379
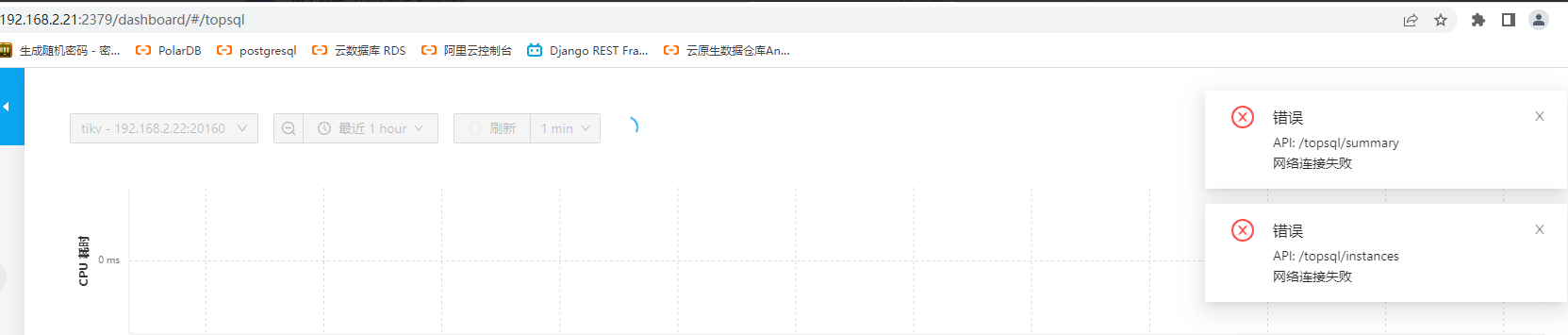
5.等待切换
6.此时dasbord的所有内容都切换到 192.168.2.22节点上了
- 添加一个新的pd节点
谨慎:先测试环境无误在操作。
您当时destroy的是 tidb集群吗 ??
试了下,还是报502。嗯呢,是destroy的集群,虽然是生成环境,但是还没有接入项目,在部署运维阶段