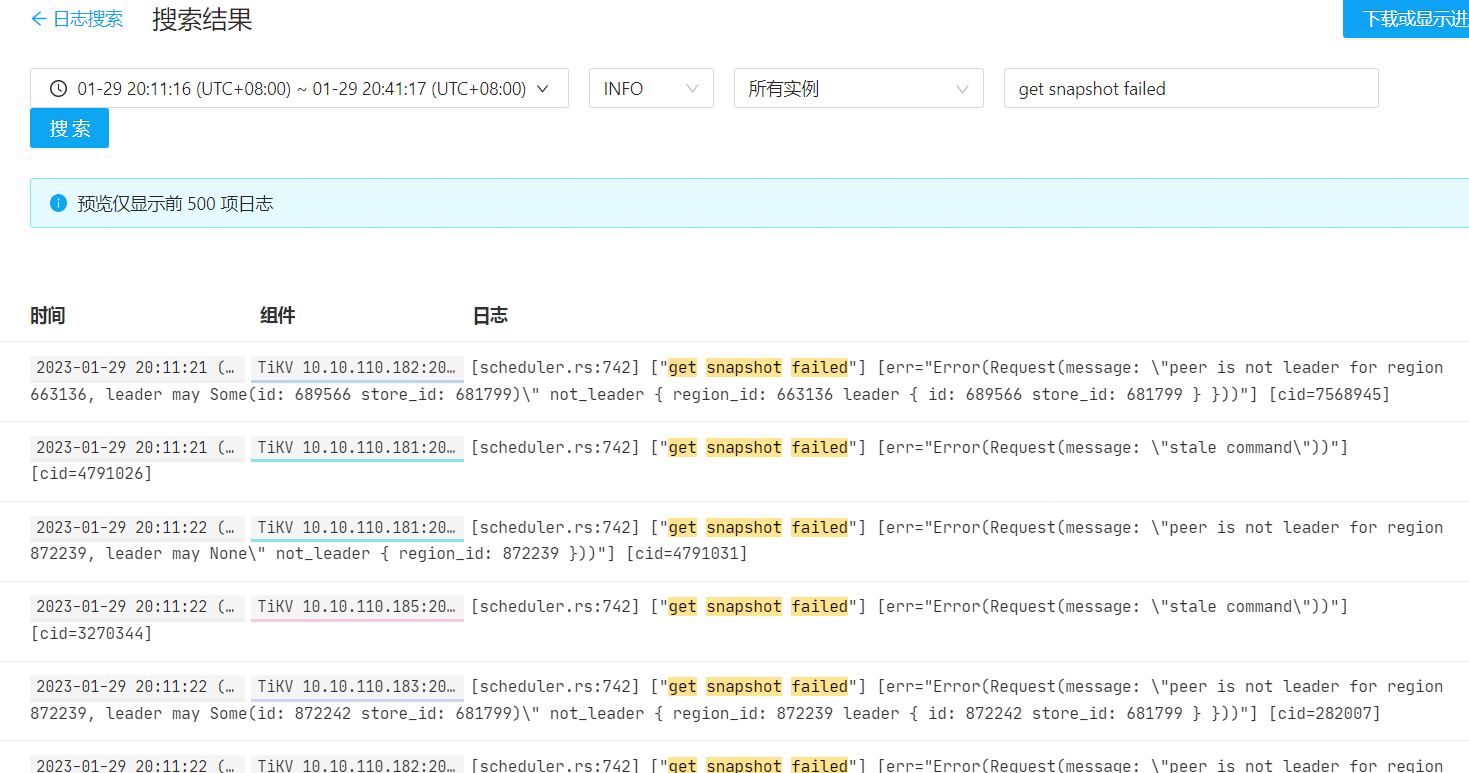
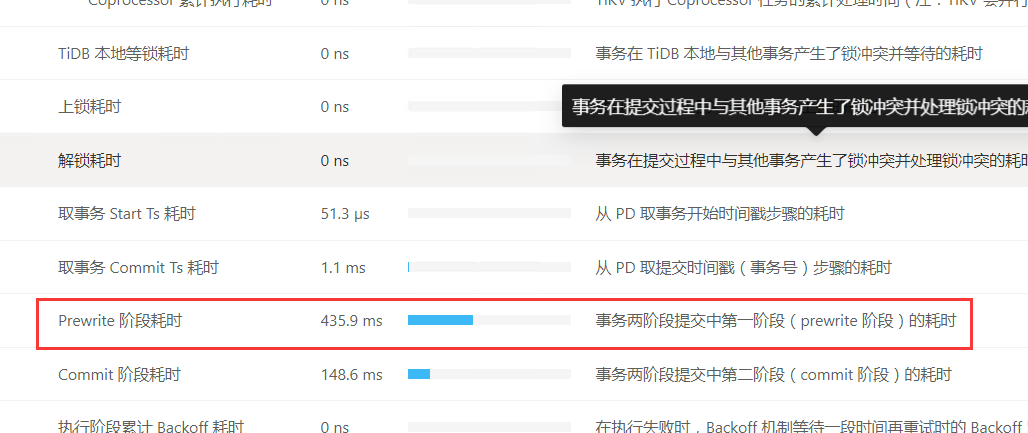
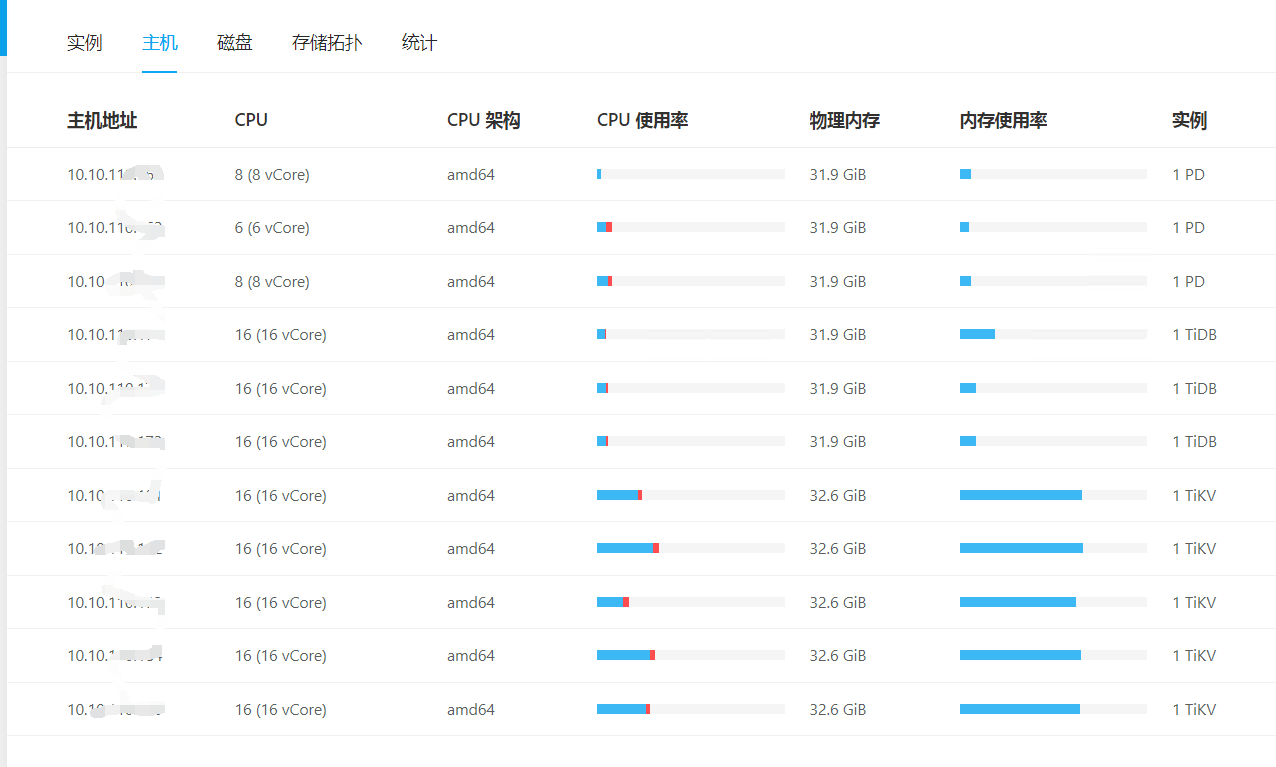
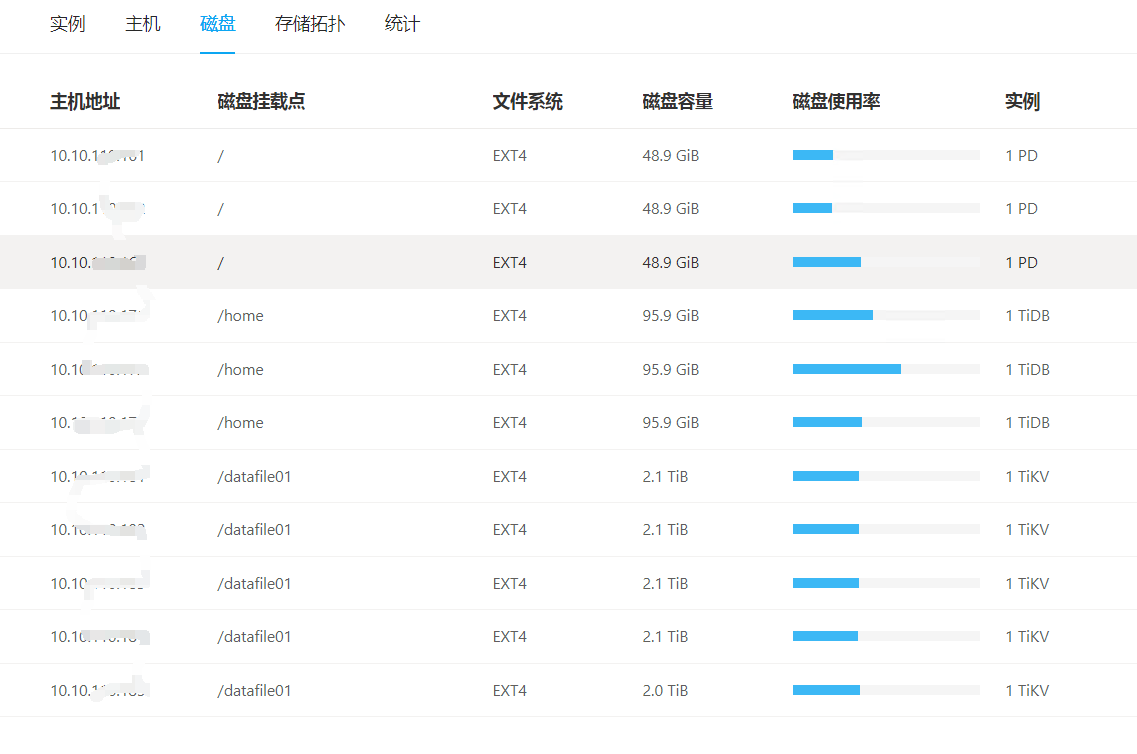
能补充下集群的配置信息么? 网络,硬件(cpu,mem,disk),节点信息等等

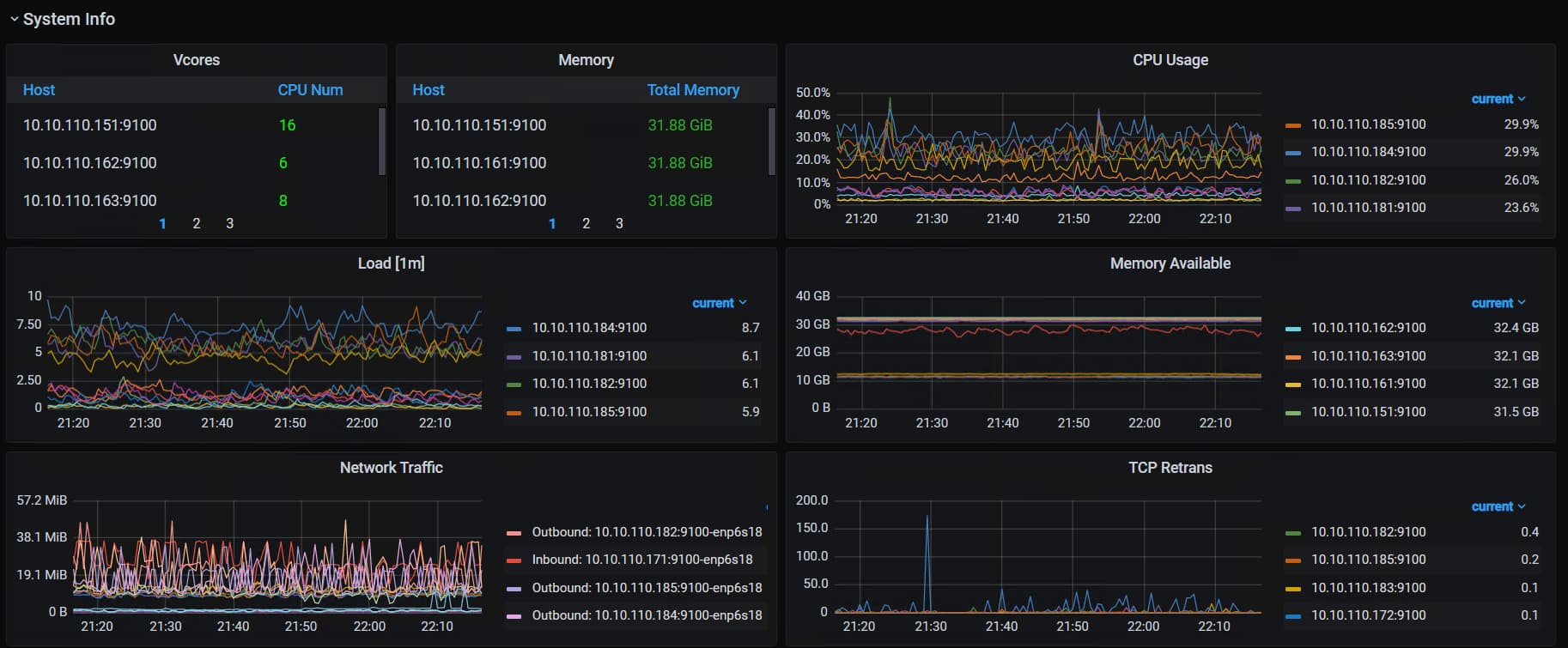
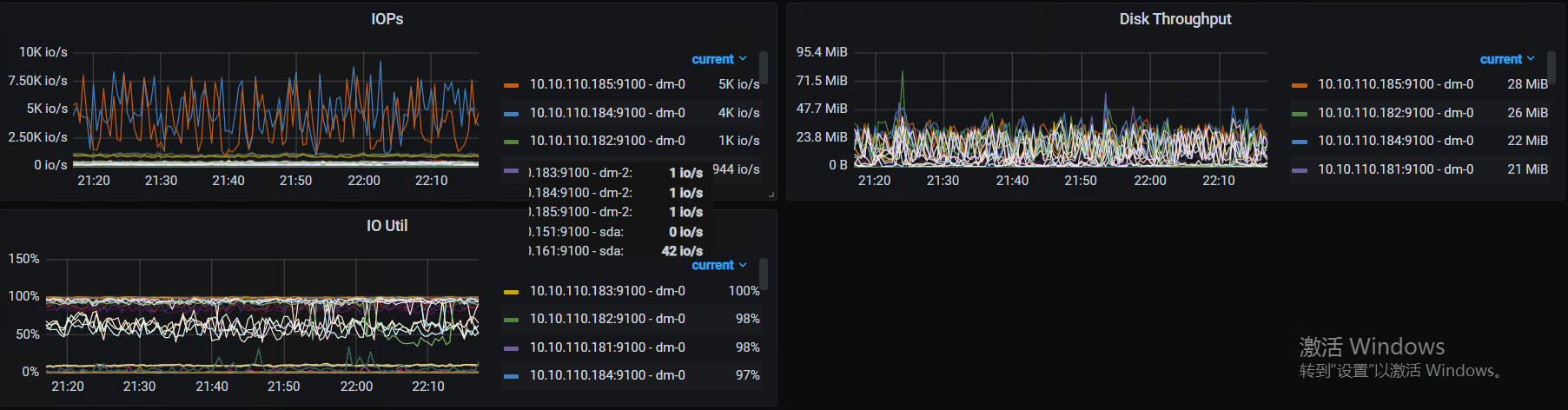
一直是这样的,有服务一直再写数据,我们是做智能设备的,设备的实时数据会10s左右写一次。
可以关注下 磁盘的吞吐性能和业务上的需求是否完全符合…
我感觉这个指标反映的情况是业务需求大于硬件性能的
从业务上来说 主要是写入数据,增加 批量写入的数据量,性能有所提升。但是 上面的报错一直存在,是不是 bug?
IO 不够,限制了很多服务之间的联系… 也没办法保证副本之间的同步了
建议你查阅下 region 的统计信息,如果发现有很大的差距,想办法优化下把
IO 不够 是SSD磁盘 的读写性能 达不到 业务需求吗?
查下 SSD 的性能参数,如果有可能,还会有 RAID , RAID 也有可能导致 SSD 性能无法释放
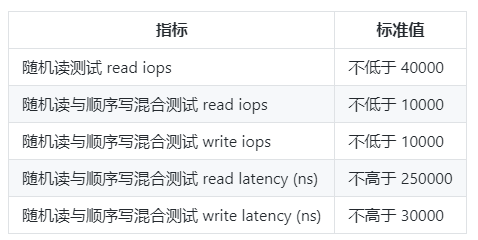
可以参考下这个
然后,我个人收藏了一些参数,你也可以参考下
fdatasync的性能参考
参考值一:非 NVMe 的 SSD 的 fdatasync/s 约 5~8K/s
参考值二:中早期 NVMe 的 fdatasync/s 约 20~50K/s
参考值三:当前成熟的 PCIE 3 的 NVMe 约 200~500K/s
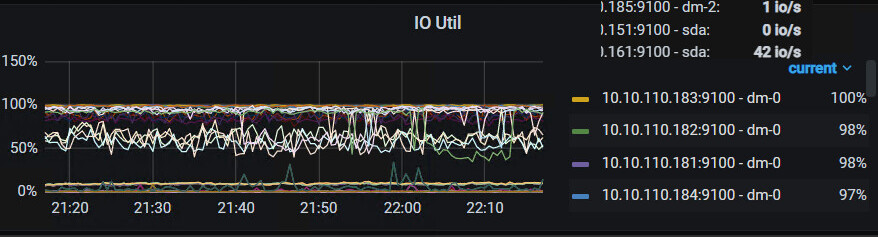
看起来是io能力不足(ioUtility%=100%),另外还可以补充看看网络传输的一些指标。
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。