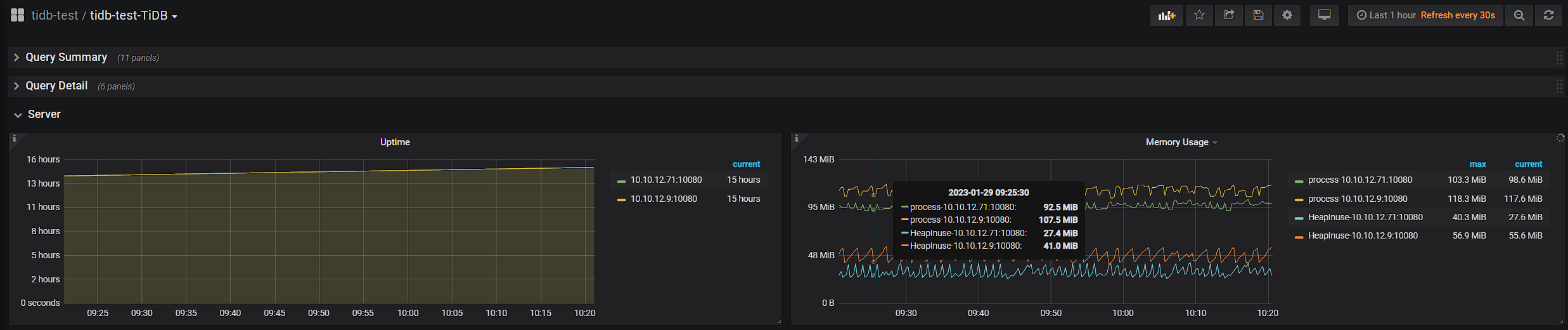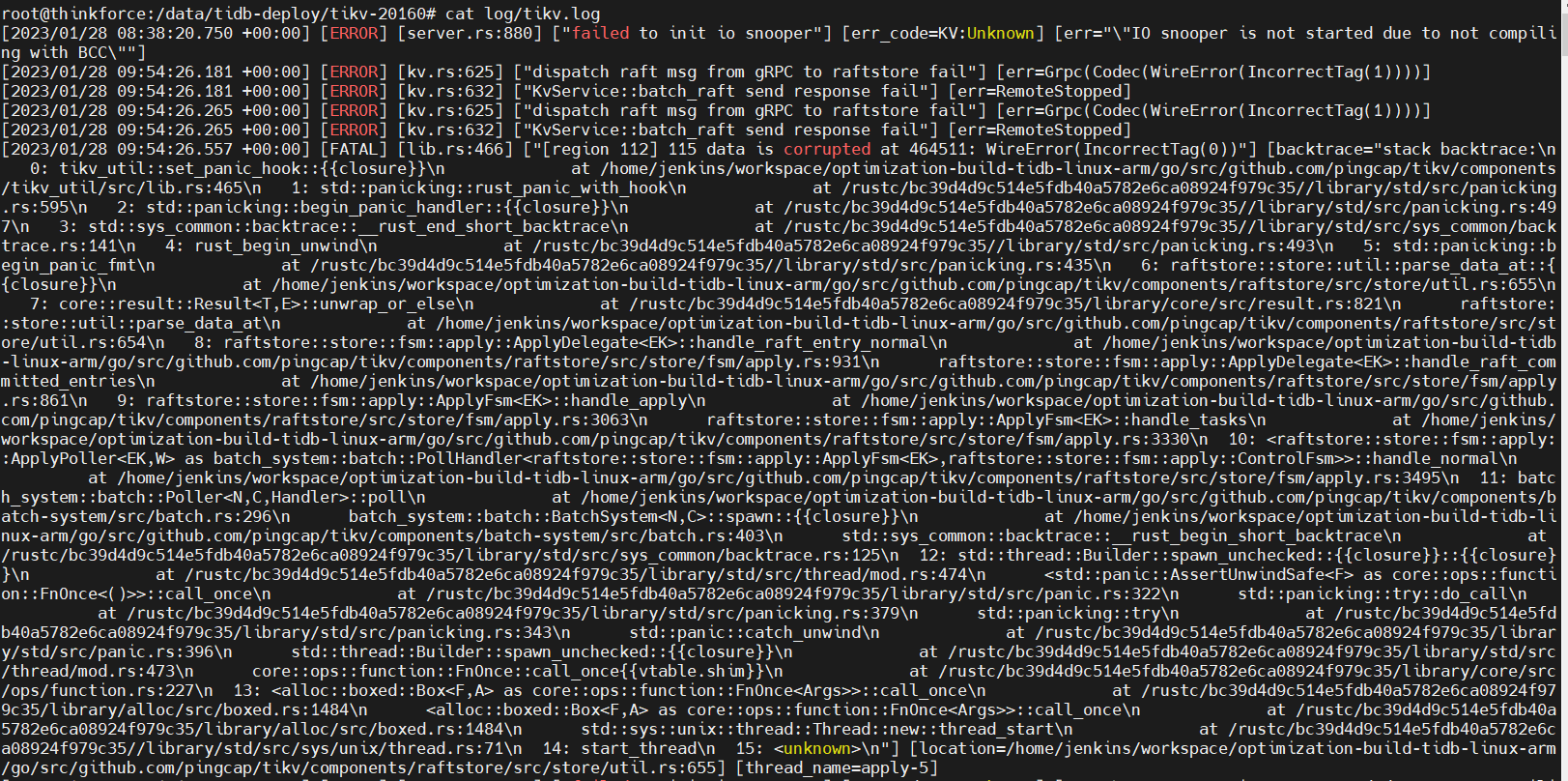
TiKV节点在我使用sysbench插入数据的时候报上图错误(该TIKV节点在日志中时间为09:34左右挂掉)
插入数据的命令是
sysbench --config-file=config1 oltp_common --tables=5 --table-size=100000000 prepare
Grafana部分截图如下

硬盘的空间肯定是够的
请问在不改变插入数据规模的情况下有什么解决办法吗
Grafana部分截图如下
硬盘的空间肯定是够的
请问在不改变插入数据规模的情况下有什么解决办法吗
参考https://github.com/tikv/tikv/issues/9852
This may cause by the
raftstorerun slowly and raft messages get pile up in the channel
尝试调大TiKV的raftstore.store-pool-size看看结果(8 → 32)
检查内存
内存是够的,挂掉的那个节点有256G内存,我把storage.block-cache.capacity 设为80G,但Grafana显示的是在内存到68.3G的时候就挂掉了
调大raftstore.store-pool-size参数并没有解决问题
混合部署的。请把问题节点的 pd和tidb的日志和监控也发下。
内存部分
pd-ctl 查下store的信息
在确认。混合部署的tikv是否打了label
调整下server.max-grpc-send-msg-len 的值在尝试一下
pd-ctl查到的store信息如下
{
"count": 3,
"stores": [
{
"store": {
"id": 5,
"address": "10.10.12.78:20160",
"labels": [
{
"key": "host",
"value": "h1"
},
{
"key": "zone",
"value": "z0"
}
],
"version": "5.0.3",
"status_address": "10.10.12.78:20180",
"git_hash": "63b63edfbb9bbf8aeb875aad28c59f082eeb55d4",
"start_timestamp": 1674902194,
"deploy_path": "/data/tidb-deploy/tikv-20160/bin",
"last_heartbeat": 1674959822476930860,
"state_name": "Up"
},
"status": {
"capacity": "2.864TiB",
"available": "2.597TiB",
"used_size": "56.64GiB",
"leader_count": 874,
"leader_weight": 1,
"leader_score": 874,
"leader_size": 75180,
"region_count": 1748,
"region_weight": 1,
"region_score": 162305.90022865508,
"region_size": 147112,
"start_ts": "2023-01-28T10:36:34Z",
"last_heartbeat_ts": "2023-01-29T02:37:02.47693086Z",
"uptime": "16h0m28.47693086s"
}
},
{
"store": {
"id": 1,
"address": "10.10.12.78:20161",
"labels": [
{
"key": "host",
"value": "h1"
},
{
"key": "zone",
"value": "z1"
}
],
"version": "5.0.3",
"status_address": "10.10.12.78:20181",
"git_hash": "63b63edfbb9bbf8aeb875aad28c59f082eeb55d4",
"start_timestamp": 1674902194,
"deploy_path": "/data/tidb-deploy/tikv-20161/bin",
"last_heartbeat": 1674959822977079499,
"state_name": "Up"
},
"status": {
"capacity": "2.864TiB",
"available": "2.597TiB",
"used_size": "56.63GiB",
"leader_count": 874,
"leader_weight": 1,
"leader_score": 874,
"leader_size": 71932,
"region_count": 1748,
"region_weight": 1,
"region_score": 162305.90022885762,
"region_size": 147112,
"start_ts": "2023-01-28T10:36:34Z",
"last_heartbeat_ts": "2023-01-29T02:37:02.977079499Z",
"uptime": "16h0m28.977079499s"
}
},
{
"store": {
"id": 4,
"address": "10.10.12.71:20160",
"labels": [
{
"key": "host",
"value": "h3"
},
{
"key": "zone",
"value": "z0"
}
],
"version": "5.0.3",
"status_address": "10.10.12.71:20180",
"git_hash": "63b63edfbb9bbf8aeb875aad28c59f082eeb55d4",
"start_timestamp": 1674959822,
"deploy_path": "/data/tidb-deploy/tikv-20160/bin",
"last_heartbeat": 1674917576942024622,
"state_name": "Down"
},
"status": {
"capacity": "2.864TiB",
"available": "2.658TiB",
"used_size": "61.8GiB",
"leader_count": 0,
"leader_weight": 1,
"leader_score": 0,
"leader_size": 0,
"region_count": 1748,
"region_weight": 1,
"region_score": 162076.62883248986,
"region_size": 147112,
"start_ts": "2023-01-29T02:37:02Z",
"last_heartbeat_ts": "2023-01-28T14:52:56.942024622Z"
}
}
]
}
Tikv打了Label
上面参数调整之后看看
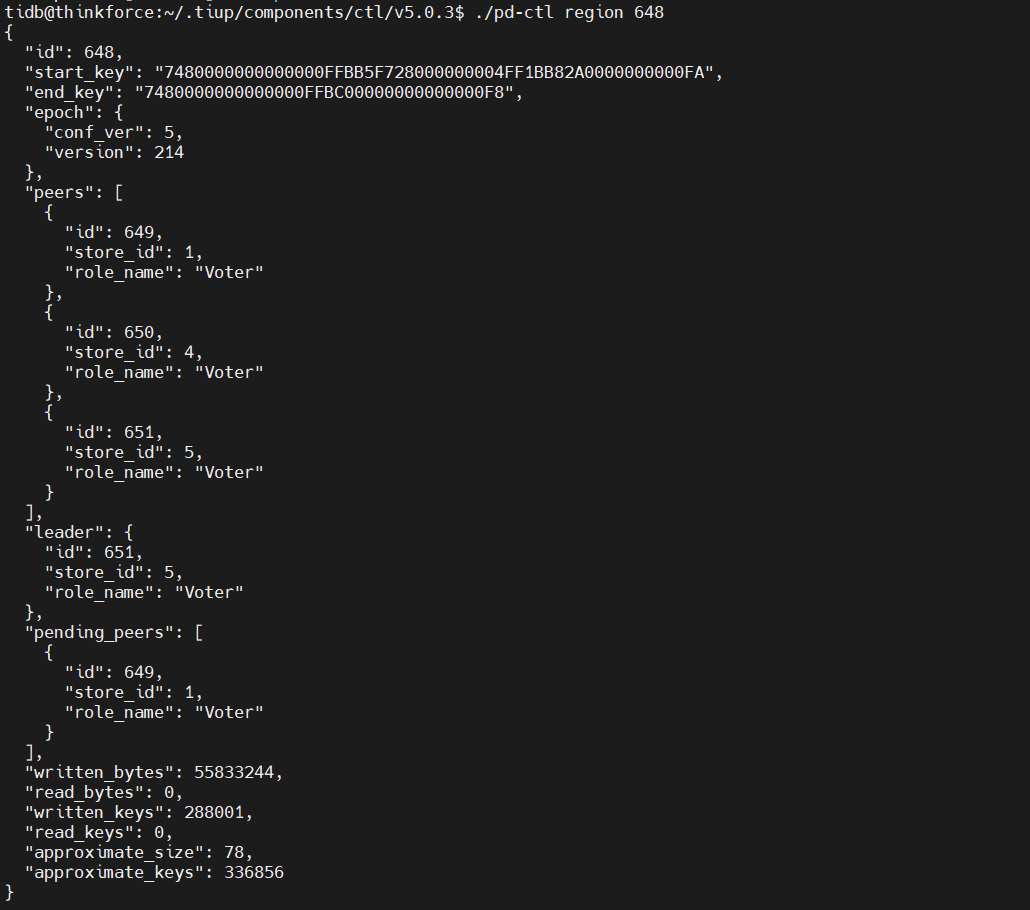
如果还是有问题。看下日志中给的 region 648 查下这个region的情况
好的,是调小这个参数吗?我突然想到调大grpc-concurrency这个参数会不会也有效果,我都试一试,迟一些来给您反馈
ok.
如果是region问题。可以先查一下 tikv-ctl --data-dir /path/to/tikv bad-regions
这个要在挂掉的tikv节点上运行
region check 看下是否有异常的peer