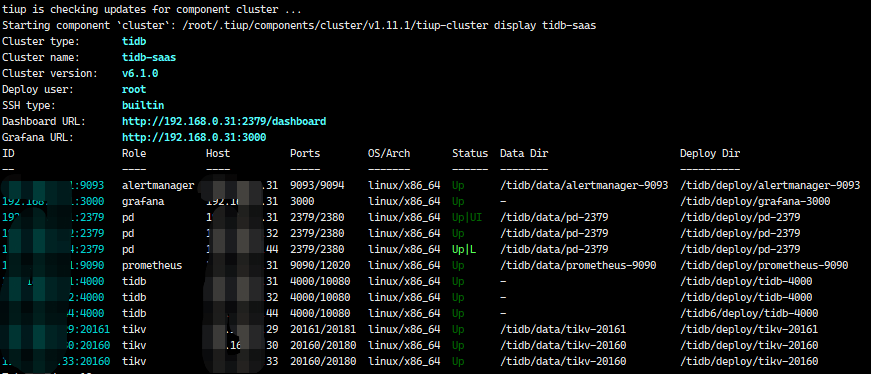
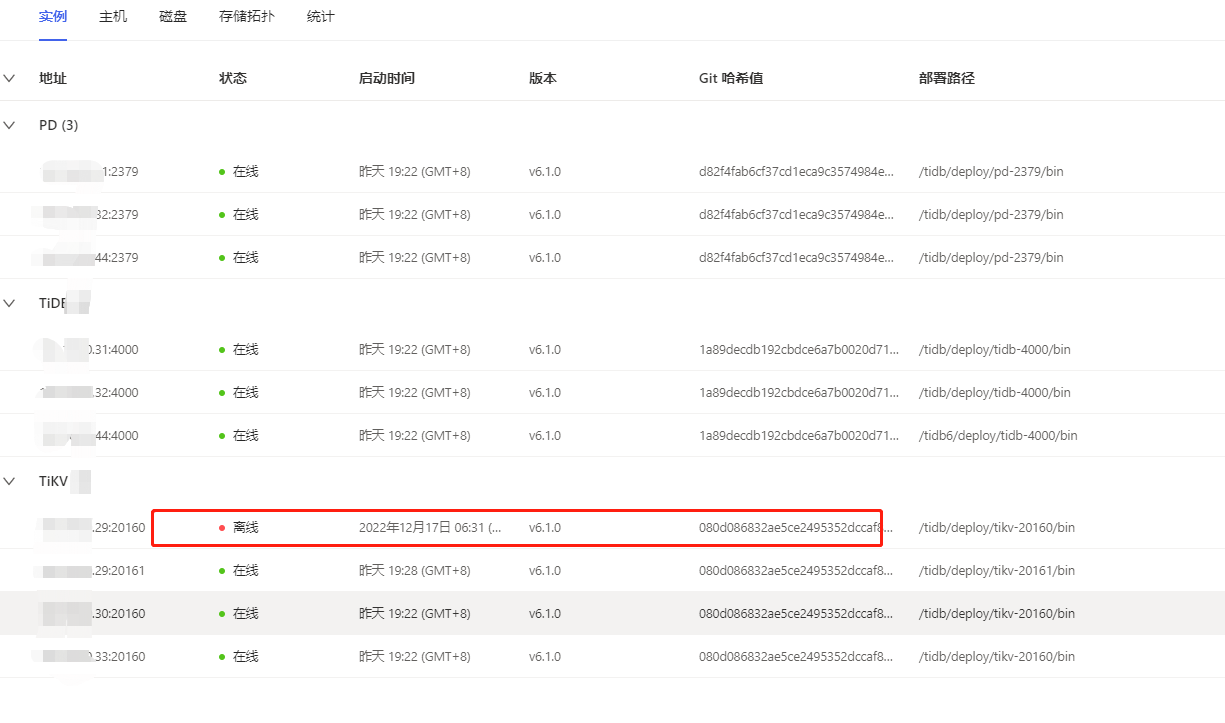
生产环境tidb6.1,pd、tidb、kv分别部署3个节点,一个kv节点自动离线后无法启动,整点时数据库性能下降持续时间大概10分钟,使用tiup cluster scale-in 强制将离线节点从集群中移除, 执行 tiup cluster prune命令清理,使用tiup cluster display查看节点信息离线节点已被移除,但是dashboard查看还在并显示离线状态
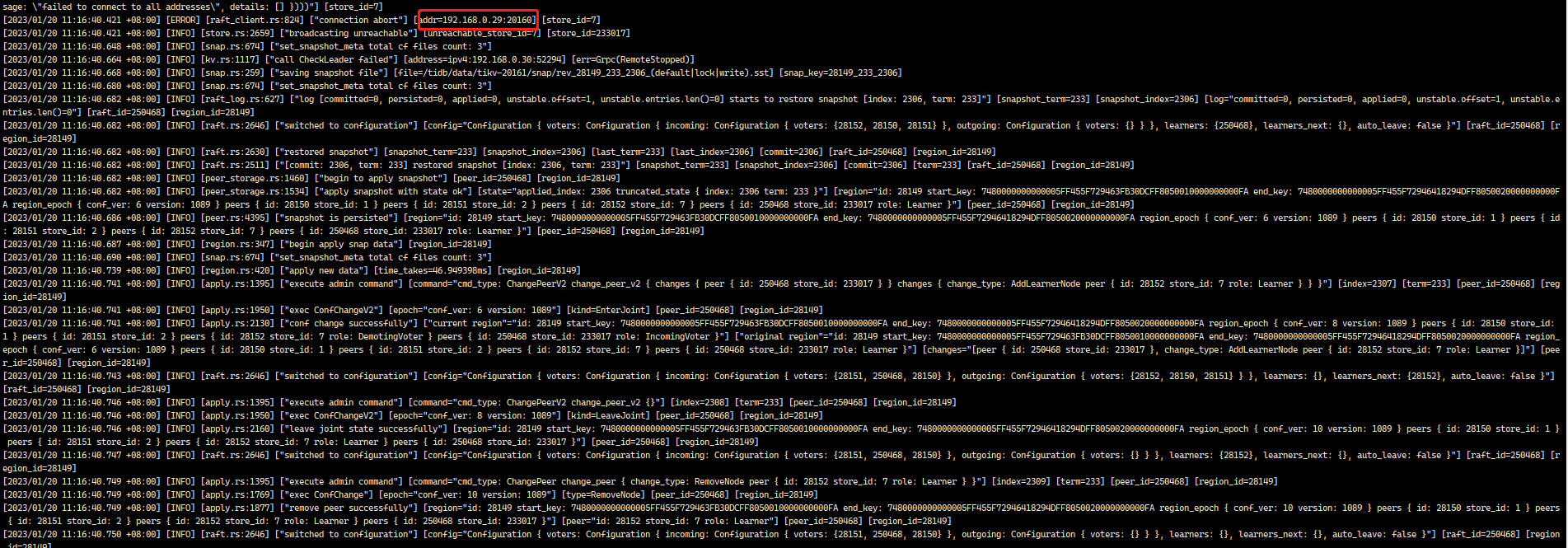
重新在原离线服务器(系统已重装)部署kv 提示20160存在安装失败,修改端口号改成20161/20181重新部署成功,查看kv日志之前被移除的节点还在并且报错,错误日志如下
使用tiup cluster display 查看目前节点信息如下
web端查看节点信息如下
已离线的节点无法移除,请高人指点下,感激!!!!!!!!!!
dba-kit
(张天师)
2
你下线时的操作步骤再详细讲一下?有没有等TiKV把所有leader都驱逐完毕啊?
dba-kit
(张天师)
3
默认情况下,tiup在驱逐leader时候只会等待5min,如果数据量太大,有可能你scale-in虽然结束(报error),但是后台还在执行驱逐leader。
dba-kit
(张天师)
4
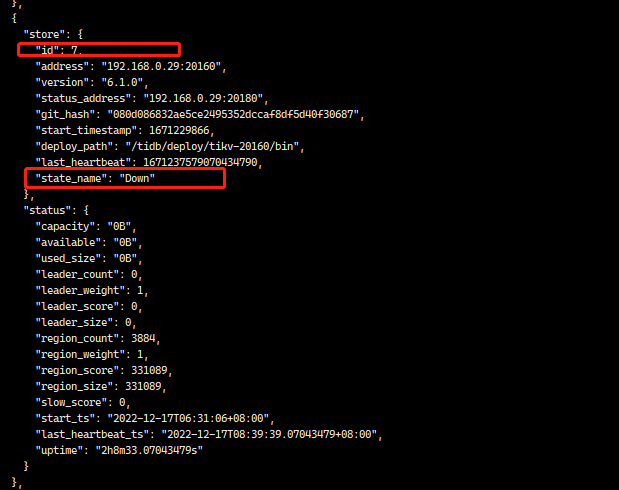
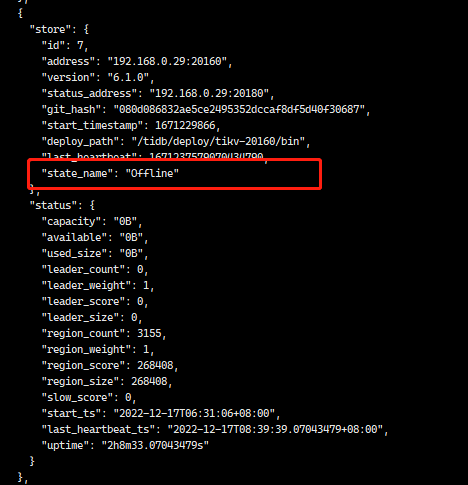
可以执行一下这个命令,看下节点状态是否正常
tiup ctl:v6.1.0 pd store --jq '.stores[] | .store | {address, version, state_name}'
pd ctl 看看还有没下线节点(store)的信息
离线节点是12.17号离线的,发现数据库在整点时候性能会下降,大约会持续10分钟,查看数据库发现一个kv节点离线了也无法启动了,使用 tiup cluster scale-in 强制将离线节点从集群中移除, 十几分钟以后执行 tiup cluster prune,执行后查看离线节点还在,几个小时之后再次执行清理离线节点还在
dba-kit
(张天师)
8
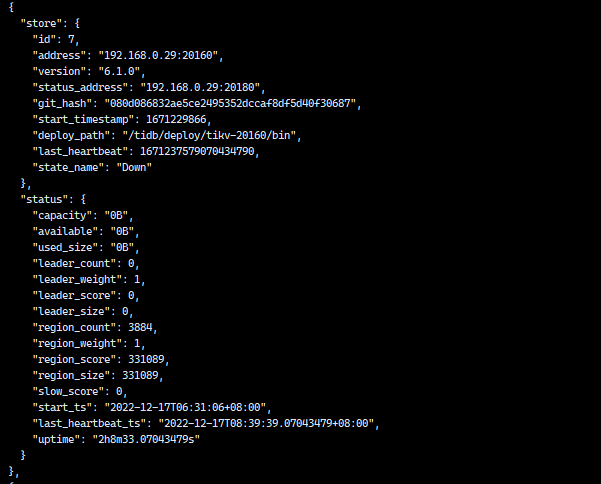
uptime看起来是最近还在使用,你登陆tikv节点,ps看下进程是否还在?
另外节点状态是 down,并不是tombstone,我怀疑可能还有leader没有被转移走,就被你强制删除了
store delete store_id 试试
注意 id 别错了
裤衩儿飞上天
10
他先是节点异常 起不来了,然后强制删除了节点,系统还重装了
进程不在了,我是重装了系统,
之前的端口号是20160的,这个20161是我后来添加的
dba-kit
(张天师)
12
各状态的含义如图所示,建议先别直接delete store,怕真的丢region。(虽然你重装系统了,但是tikv数据大概率在数据盘,不是系统盘,所以重装后数据还在。这也是为啥你直接用原来的端口安装会报错的原因)
裤衩儿飞上天
15
听 天师的 ,先检查下 region 有没有少副本的,都正常了 再执行删除
不过你这节点17号离线的,都好几天了,副本应该已经补齐了
裤衩儿飞上天
18
等等看 顺便监控下 store 7的region 信息
dba-kit
(张天师)
19
offline阶段其实是在转移leader到其他节点,不过你数据都已经删除了,不知道能不能正常转移。。
pd-ctl上执行这个,看下还有没有region信息遗留
region store 7
dba-kit
(张天师)
20
region check down-peer也执行下,看下是不是所有region状态都正常