孤独的狼
1
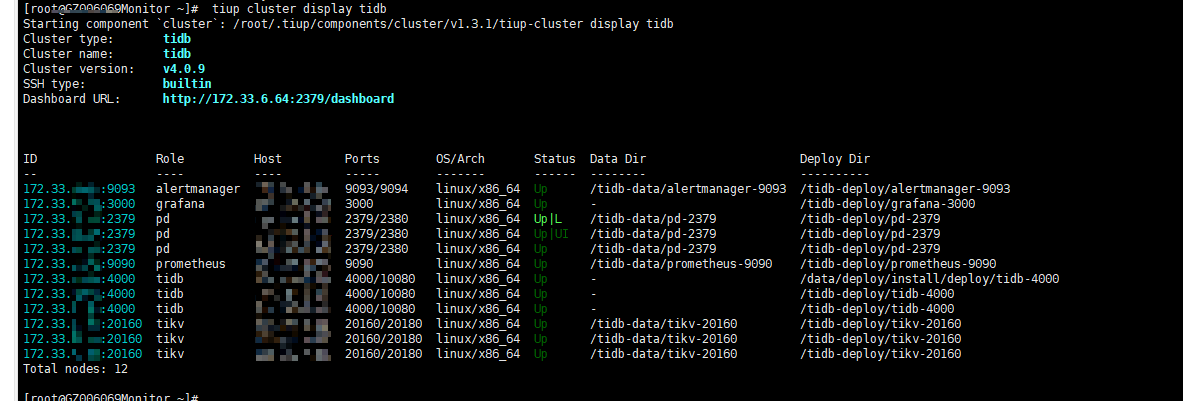
【 TiDB 使用环境】生产环境
【 TiDB 版本】 v4.0.9
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
prometheus 显示状态正常,采集不到数据
【资源配置】
【附件:截图/日志/监控】
drwxr-xr-x 3 tidb tidb 68 1月 17 10:02 01G00ZE4JVR1DEFJVMTRDBV9P5
drwxr-xr-x 3 tidb tidb 68 1月 17 10:02 01G06RTS5NFYSG50ZJ1KHZX7Y0
drwxr-xr-x 3 tidb tidb 68 1月 17 10:02 01G0CJ7CM5VBB4C8J09ZWN84H2
drwxr-xr-x 3 tidb tidb 68 1月 17 10:02 01G0JBKYDSVDXY7YH0BBG5942H
drwxr-xr-x 3 tidb tidb 88 1月 17 10:02 01G0R50J9CTEBYNFG5A3M79ZWG
drwxr-xr-x 3 tidb tidb 68 1月 17 10:02 01G0XYD67Y2SC71WM5MB69GN2N
drwxr-xr-x 3 tidb tidb 68 1月 17 10:02 01G13QSS84BYSXDVRCJ9CEWQQW
drwxr-xr-x 3 tidb tidb 68 1月 17 10:02 01G19H6D5FYNWN4F6P6VAMMK3K
drwxr-xr-x 3 tidb tidb 68 1月 17 10:02 01G1FAK1KEN08QEYN0CHQK06FX
drwxr-xr-x 3 tidb tidb 68 1月 17 10:02 01G1N3ZMT2279WZHM7NEGJSWFW
drwxr-xr-x 3 tidb tidb 68 1月 17 10:02 01G1TXC87AHEZ4YY60V06CBTPB
drwxr-xr-x 3 tidb tidb 88 1月 17 10:02 01G20PRVX46MK3ZQAEQMT96MHG
drwxr-xr-x 3 tidb tidb 68 1月 17 10:02 01G26G5G4KE40K16Q0CSZM15VY
drwxr-xr-x 3 tidb tidb 88 1月 17 10:02 01G28DYXFHG6VRDAA4X63P932X
drwxr-xr-x 3 tidb tidb 88 1月 17 10:02 01G292HXZQF785Y8A0RWH9R7PM
drwxr-xr-x 3 tidb tidb 88 1月 17 10:02 01G292J1Z8NH0P2EJXFA6797EQ
drwxr-xr-x 3 tidb tidb 68 1月 17 10:02 01G29F0D2J3VMH0799WC8D5VMS
drwxr-xr-x 3 tidb tidb 68 1月 17 10:02 01G29G9CCBNPWM6KQ1N44FXS3K
drwxr-xr-x 3 tidb tidb 33 12月 14 00:00 01GM63EDAWGHA85R4ST7KM454V.tmp
drwxr-xr-x 3 tidb tidb 68 1月 17 10:02 01GMDTV05ZPY8TKJZ2DGMYK1D3
drwxr-xr-x 3 tidb tidb 33 12月 18 21:31 01GMJPY4ZQMH1QR5DGJ7QY9N4A.tmp
drwxr-xr-x 3 tidb tidb 68 1月 17 10:02 01GMQ11XZF9GFHADYCXTDQD5W4
drwxr-xr-x 3 tidb tidb 68 1月 17 10:02 01GN6KPH5WDV7DF4XWPYXFGE58
drwxr-xr-x 3 tidb tidb 68 1月 17 10:02 01GNBZCD75QHVG9A95KVYNQX1M
drwxr-xr-x 3 tidb tidb 33 1月 9 10:05 01GPA4DGP40PSJFXQVCKKWGE6F.tmp
drwxr-xr-x 3 tidb tidb 33 1月 15 08:01 01GPSBNQRHK5W35F02KTXCZT4S.tmp
-rw-r–r-- 1 tidb tidb 0 7月 7 2020 lock
drwxr-xr-x 3 tidb tidb 24576 1月 15 07:44 wal
孤独的狼
2
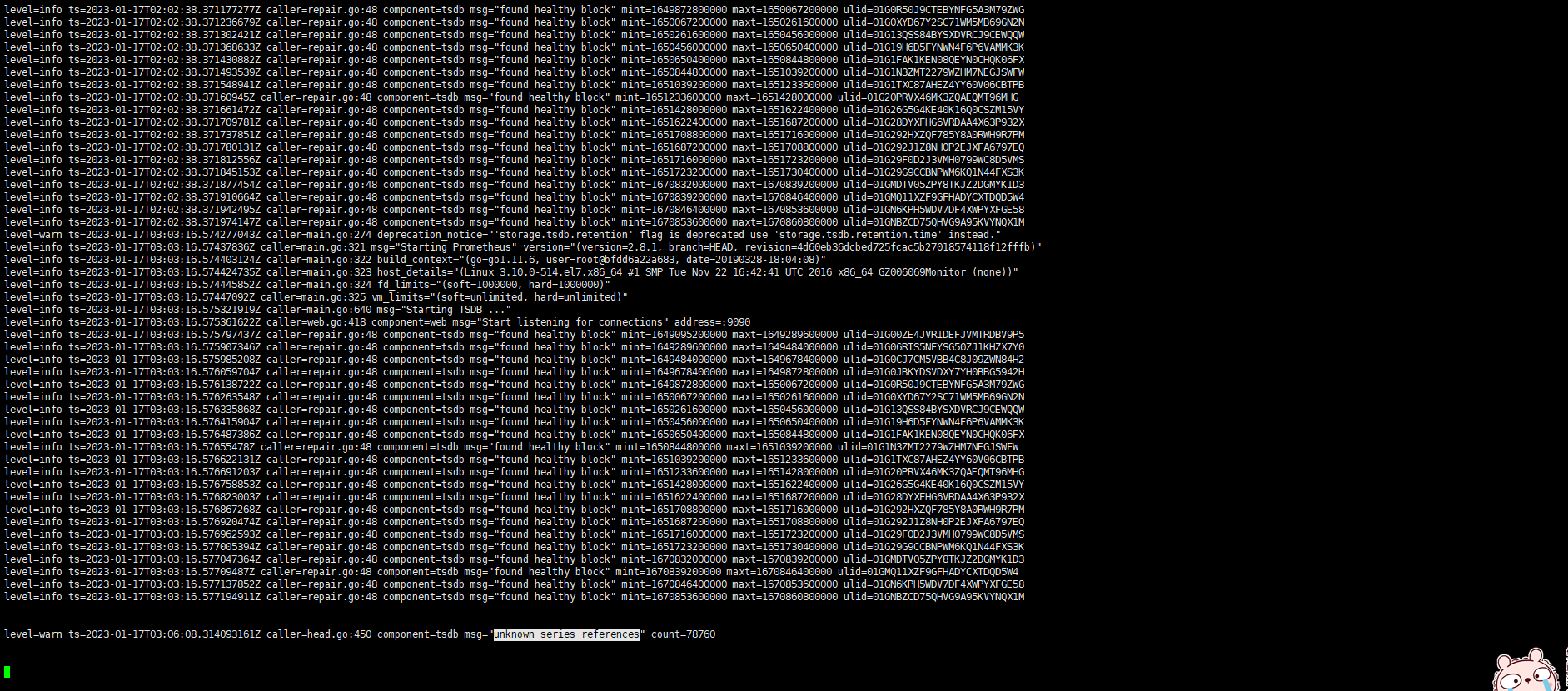
普罗米修斯的日志
level=warn ts=2023-01-17T02:02:38.369248526Z caller=main.go:274 deprecation_notice=“‘storage.tsdb.retention’ flag is deprecated use ‘storage.tsdb.retention.time’ instead.”
level=info ts=2023-01-17T02:02:38.369346127Z caller=main.go:321 msg=“Starting Prometheus” version=“(version=2.8.1, branch=HEAD, revision=4d60eb36dcbed725fcac5b27018574118f12fffb)”
level=info ts=2023-01-17T02:02:38.369371412Z caller=main.go:322 build_context=“(go=go1.11.6, user=root@bfdd6a22a683, date=20190328-18:04:08)”
level=info ts=2023-01-17T02:02:38.369393031Z caller=main.go:323 host_details=“(Linux 3.10.0-514.el7.x86_64 #1 SMP Tue Nov 22 16:42:41 UTC 2016 x86_64 GZ006069Monitor (none))”
level=info ts=2023-01-17T02:02:38.369417405Z caller=main.go:324 fd_limits=“(soft=1000000, hard=1000000)”
level=info ts=2023-01-17T02:02:38.369435024Z caller=main.go:325 vm_limits=“(soft=unlimited, hard=unlimited)”
level=info ts=2023-01-17T02:02:38.370336222Z caller=main.go:640 msg=“Starting TSDB …”
level=info ts=2023-01-17T02:02:38.370387979Z caller=web.go:418 component=web msg=“Start listening for connections” address=:9090
level=info ts=2023-01-17T02:02:38.370877652Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1649095200000 maxt=1649289600000 ulid=01G00ZE4JVR1DEFJVMTRDBV9P5
level=info ts=2023-01-17T02:02:38.370975598Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1649289600000 maxt=1649484000000 ulid=01G06RTS5NFYSG50ZJ1KHZX7Y0
level=info ts=2023-01-17T02:02:38.371039848Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1649484000000 maxt=1649678400000 ulid=01G0CJ7CM5VBB4C8J09ZWN84H2
level=info ts=2023-01-17T02:02:38.371101029Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1649678400000 maxt=1649872800000 ulid=01G0JBKYDSVDXY7YH0BBG5942H
level=info ts=2023-01-17T02:02:38.371177277Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1649872800000 maxt=1650067200000 ulid=01G0R50J9CTEBYNFG5A3M79ZWG
level=info ts=2023-01-17T02:02:38.371236679Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1650067200000 maxt=1650261600000 ulid=01G0XYD67Y2SC71WM5MB69GN2N
level=info ts=2023-01-17T02:02:38.371302421Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1650261600000 maxt=1650456000000 ulid=01G13QSS84BYSXDVRCJ9CEWQQW
level=info ts=2023-01-17T02:02:38.371368633Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1650456000000 maxt=1650650400000 ulid=01G19H6D5FYNWN4F6P6VAMMK3K
level=info ts=2023-01-17T02:02:38.371430882Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1650650400000 maxt=1650844800000 ulid=01G1FAK1KEN08QEYN0CHQK06FX
level=info ts=2023-01-17T02:02:38.371493539Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1650844800000 maxt=1651039200000 ulid=01G1N3ZMT2279WZHM7NEGJSWFW
level=info ts=2023-01-17T02:02:38.371548941Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1651039200000 maxt=1651233600000 ulid=01G1TXC87AHEZ4YY60V06CBTPB
level=info ts=2023-01-17T02:02:38.37160945Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1651233600000 maxt=1651428000000 ulid=01G20PRVX46MK3ZQAEQMT96MHG
level=info ts=2023-01-17T02:02:38.371661472Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1651428000000 maxt=1651622400000 ulid=01G26G5G4KE40K16Q0CSZM15VY
level=info ts=2023-01-17T02:02:38.371709781Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1651622400000 maxt=1651687200000 ulid=01G28DYXFHG6VRDAA4X63P932X
level=info ts=2023-01-17T02:02:38.371737851Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1651708800000 maxt=1651716000000 ulid=01G292HXZQF785Y8A0RWH9R7PM
level=info ts=2023-01-17T02:02:38.371780131Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1651687200000 maxt=1651708800000 ulid=01G292J1Z8NH0P2EJXFA6797EQ
level=info ts=2023-01-17T02:02:38.371812556Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1651716000000 maxt=1651723200000 ulid=01G29F0D2J3VMH0799WC8D5VMS
level=info ts=2023-01-17T02:02:38.371845153Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1651723200000 maxt=1651730400000 ulid=01G29G9CCBNPWM6KQ1N44FXS3K
level=info ts=2023-01-17T02:02:38.371877454Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1670832000000 maxt=1670839200000 ulid=01GMDTV05ZPY8TKJZ2DGMYK1D3
level=info ts=2023-01-17T02:02:38.371910664Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1670839200000 maxt=1670846400000 ulid=01GMQ11XZF9GFHADYCXTDQD5W4
level=info ts=2023-01-17T02:02:38.371942495Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1670846400000 maxt=1670853600000 ulid=01GN6KPH5WDV7DF4XWPYXFGE58
level=info ts=2023-01-17T02:02:38.371974147Z caller=repair.go:48 component=tsdb msg=“found healthy block” mint=1670853600000 maxt=1670860800000 ulid=01GNBZCD75QHVG9A95KVYNQX1M
^C
[root@GZ006069Monitor log]# tail -200f prometheus.log
孤独的狼
3
grafana采集的日志
t=2023-01-17T10:05:12+0800 lvl=eror msg=“Alert Rule Result Error” logger=alerting.evalContext ruleId=72 name=“server report failures alert” error=“Could not find datasource Data source not found” changing state to=alerting
t=2023-01-17T10:05:12+0800 lvl=eror msg=“Alert Rule Result Error” logger=alerting.evalContext ruleId=31 name=“TiKV channel full alert” error=“Could not find datasource Data source not found” changing state to=alerting
t=2023-01-17T10:05:12+0800 lvl=eror msg=“Alert Rule Result Error” logger=alerting.evalContext ruleId=35 name=“TiKV scheduler worker CPU alert” error=“Could not find datasource Data source not found” changing state to=alerting
t=2023-01-17T10:05:14+0800 lvl=eror msg=“Alert Rule Result Error” logger=alerting.evalContext ruleId=61 name=“TiKV Storage ReadPool CPU alert” error=“Could not find datasource Data source not found” changing state to=alerting
t=2023-01-17T10:05:14+0800 lvl=eror msg=“Alert Rule Result Error” logger=alerting.evalContext ruleId=60 name=“Async apply CPU alert” error=“Could not find datasource Data source not found” changing state to=alerting
t=2023-01-17T10:05:15+0800 lvl=eror msg=“Alert Rule Result Error” logger=alerting.evalContext ruleId=63 name=“TiKV gRPC poll CPU alert” error=“Could not find datasource Data source not found” changing state to=alerting
t=2023-01-17T10:05:15+0800 lvl=eror msg=“Alert Rule Result Error” logger=alerting.evalContext ruleId=22 name=“Lock Resolve OPS alert” error=“Could not find datasource Data source not found” changing state to=alerting
t=2023-01-17T10:05:16+0800 lvl=eror msg=“Alert Rule Result Error” logger=alerting.evalContext ruleId=48 name=“Transaction Retry Num alert” error=“Could not find datasource Data source not found” changing state to=alerting
t=2023-01-17T10:05:16+0800 lvl=eror msg=“Alert Rule Result Error” logger=alerting.evalContext ruleId=25 name=“gRPC poll CPU alert” error=“Could not find datasource Data source not found” changing state to=alerting
t=2023-01-17T10:05:16+0800 lvl=eror msg=“Alert Rule Result Error” logger=alerting.evalContext ruleId=40 name=“etcd disk fsync” error=“Could not find datasource Data source not found” changing state to=alerting
t=2023-01-17T10:05:17+0800 lvl=eror msg=“Alert Rule Result Error” logger=alerting.evalContext ruleId=33 name=“TiKV raft store CPU alert” error=“Could not find datasource Data source not found” changing state to=alerting
t=2023-01-17T10:05:20+0800 lvl=eror msg=“Alert Rule Result Error” logger=alerting.evalContext ruleId=57 name=“Append log duration alert” error=“Could not find datasource Data source not found” changing state to=alerting
t=2023-01-17T10:05:20+0800 lvl=eror msg=“Alert Rule Result Error” logger=alerting.evalContext ruleId=45 name=“Parse Duration alert” error=“Could not find datasource Data source not found” changing state to=alerting
t=2023-01-17T10:05:20+0800 lvl=eror msg=“Alert Rule Result Error” logger=alerting.evalContext ruleId=56 name=“TiKV raft store CPU alert” error=“Could not find datasource Data source not found” changing state to=alerting
t=2023-01-17T10:05:20+0800 lvl=eror msg=“Alert Rule Result Error” logger=alerting.evalContext ruleId=46 name=“Compile Duration alert” error=“Could not find datasource Data source not found” changing state to=alerting
t=2023-01-17T10:05:20+0800 lvl=eror msg=“Alert Rule Result Error” logger=alerting.evalContext ruleId=29 name=“Critical error alert” error=“Could not find datasource Data source not found” changing state to=alerting
t=2023-01-17T10:05:21+0800 lvl=info msg=“Shutdown started” logger=server reason=“System signal: terminated”
t=2023-01-17T10:05:21+0800 lvl=info msg=“Stopped NotificationService” logger=server reason=“context canceled”
t=2023-01-17T10:05:21+0800 lvl=info msg=“Stopped CleanUpService” logger=server reason=“context canceled”
t=2023-01-17T10:05:21+0800 lvl=info msg=“Stopped TracingService” logger=server reason=nil
t=2023-01-17T10:05:21+0800 lvl=info msg=“Stopped ProvisioningService” logger=server reason=“context canceled”
t=2023-01-17T10:05:21+0800 lvl=info msg=“Stopped AlertingService” logger=server reason=“context canceled”
t=2023-01-17T10:05:21+0800 lvl=info msg=“Stopped RemoteCache” logger=server reason=“context canceled”
t=2023-01-17T10:05:21+0800 lvl=info msg=“Stopped UsageStatsService” logger=server reason=“context canceled”
t=2023-01-17T10:05:21+0800 lvl=info msg=“Stopped Stream Manager”
t=2023-01-17T10:05:21+0800 lvl=info msg=“Stopped RenderingService” logger=server reason=nil
t=2023-01-17T10:05:21+0800 lvl=info msg=“Stopped UserAuthTokenService” logger=server reason=“context canceled”
t=2023-01-17T10:05:21+0800 lvl=info msg=“Stopped PluginManager” logger=server reason=“context canceled”
t=2023-01-17T10:05:21+0800 lvl=info msg=“Stopped InternalMetricsService” logger=server reason=“context canceled”
t=2023-01-17T10:05:21+0800 lvl=info msg=“Stopped HTTPServer” logger=server reason=nil
t=2023-01-17T10:05:21+0800 lvl=eror msg=“Server shutdown” logger=server reason=“System signal: terminated”
^C
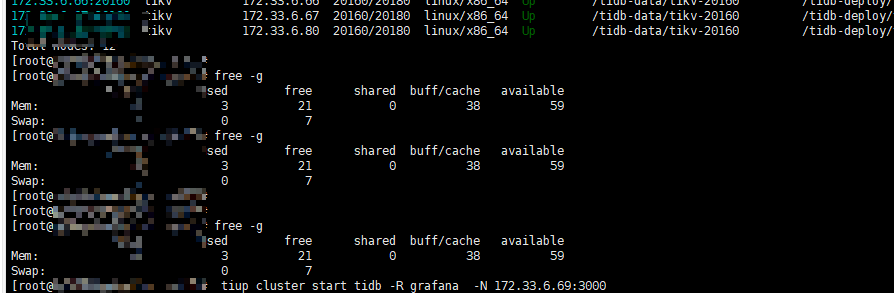
[root@GZ006069Monitor logs]# free -g
total used free shared buff/cache available
Mem: 62 2 21 0 38 59
Swap: 7 0 7
[root@GZ006069Monitor logs]#
[root@GZ006069Monitor logs]# free -g
total used free shared buff/cache available
Mem: 62 2 21 0 38 59
Swap: 7 0 7
[root@GZ006069Monitor logs]#
[root@GZ006069Monitor logs]#
[root@GZ006069Monitor logs]# tail -f grafana.log
孤独的狼
4
因为资源问题,前面监控关闭过一段时间,监控的历史数据可以删除,我就是想采集最新的监控数据,监控以前的数据可以删除
prometheus是不是故障重启啊?故障重启需要恢复wal,需要比较多的内存。tiup我不熟悉,你不要数据的话,你看看能不能缩掉监控重新建。k8s一般都是删掉pv删掉pod,自动就重新拉起来了。
历史数据都能删除了,直接scale-in scale-out最简单了
DBRE
7
按照“Starting TSDB”关键词过滤下prometheus日志看下是否prometheus不断重启。
另外可以在prometheus.yml增加如下配置来减少数据采集,然后tiup cluster restart xxx -R promethues。
不过此方式在每次拓扑变化的话,prometheus.yml会被覆盖。详细可以参考专栏 - TiDB监控Prometheus磁盘内存问题 | TiDB 社区
vim prometheus.yml
找到job_name: "tikv"处:添加
metric_relabel_configs:
- source_labels: [name]
separator: ;
regex: tikv_thread_nonvoluntary_context_switches|tikv_thread_voluntary_context_switches|tikv_threads_io_bytes_total
action: drop
- source_labels: [name,name]
separator: ;
regex: tikv_thread_cpu_seconds_total;(tokio|rocksdb).+
action: drop
孤独的狼
10
scale-in scale-out 具体如何使用
孤独的狼
11
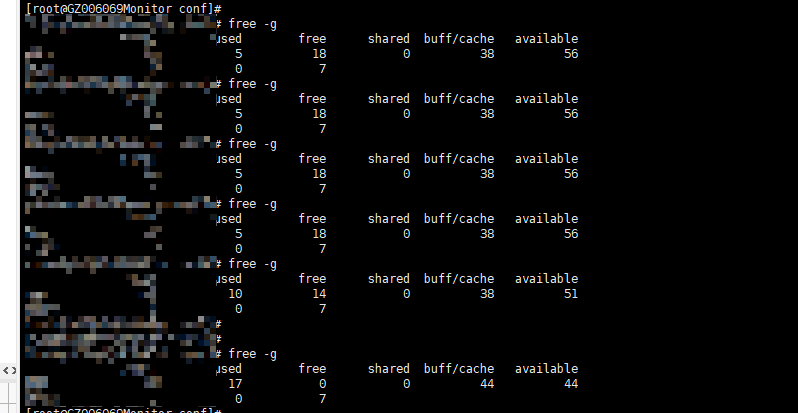
这个我加了,还是不行。 我怀疑是历史数据的问题,
level=warn ts=2023-01-17T03:06:08.314093161Z caller=head.go:450 component=tsdb msg=“unknown series references” count=78760
^C
[root@GZ006069Monitor log]# tail -200f prometheus.log
报错未知序列引用
DBRE
13
这个需要等一段时间再观察下,不是立即就会正常的,包括web api的访问。这个阶段应该是prometheus后台有某些操作
孤独的狼
14
不敢等太久,内存吃的太多了。上面还有转发的服务。监控挂了不影响线上,转发挂了会影响线上的
裤衩儿飞上天
16
tiup cluster scale-in [flags]
tiup cluster scale-out [topology.yaml] [flags]
处理prometheus的过期历史日志可以有下面的方式,建议先在测试环境验证正常再在生产环境执行。
1.临时解决方案:可以参考这个帖子试试看:prometheus的监控数据可以删除么?
删除某个时间段所有数据
curl -X POST -g ‘http://127.0.0.1:9090/api/v1/admin/tsdb/delete_series?match[]= {name =~“.+”}&start=2022-03-29T00:00:00Z&end=2022-03-30T00:00:00Z’
2.长久解决方案:
推荐:使用tiup cluster edit-config 更改prometheus 的storage_retention 的配置设置日志保留时长,然后tiup reload prometheus
(还有个不推荐但可以生效的方式:修改prometheus启动脚本中的-storage.tsdb.retention参数值,然后tiup reload prometheus )
DBRE
18
那可以先缩容再扩容prometheus节点,然后修改prometheus.yml
WalterWj
(王军 - PingCAP)
20
额 一方面是看 prome 的数据量多大,一般保存 30 天,但是如果实例数多的话存的数据就多了
另外一方面可能是你看 grafana 的时候,拉了 30 天数据然后看了一些比较复杂耗内存的监控面板导致的。
处理一般是减少保存时间,或者加内存。