【 TiDB 使用环境】生产环境
【 TiDB 版本】tidb-v6.1.3
【复现路径】从5.4.2 升级到6.1.3
【遇到的问题:问题现象及影响】
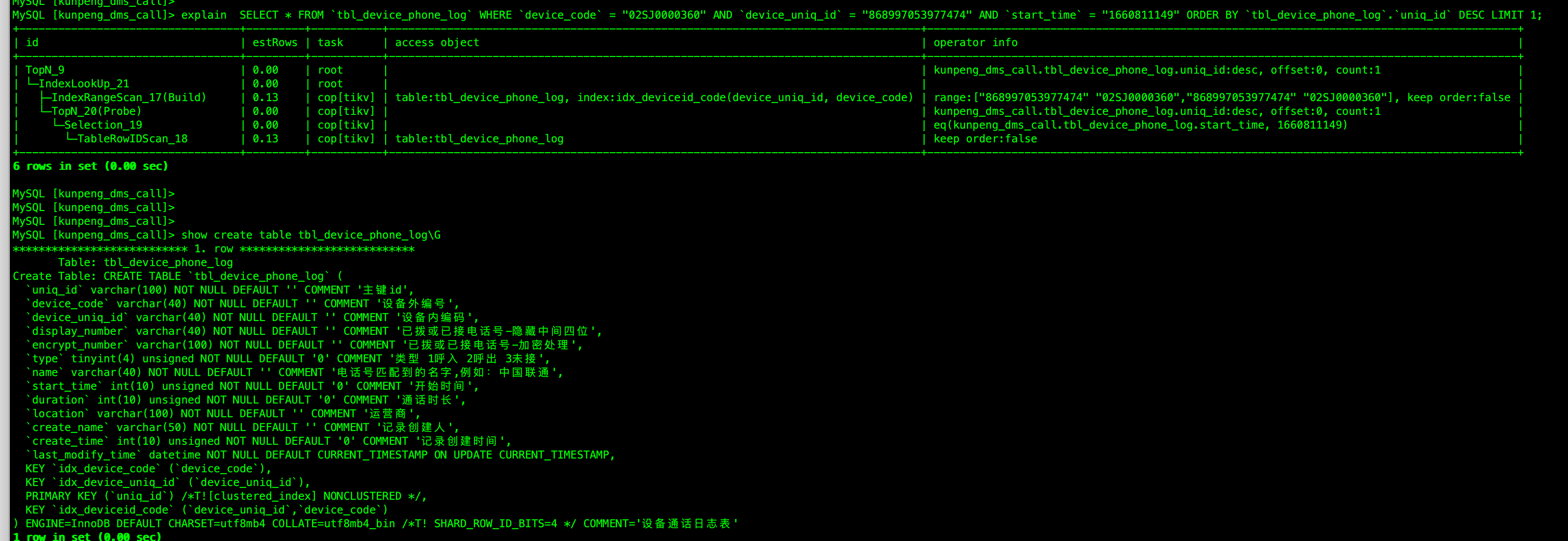
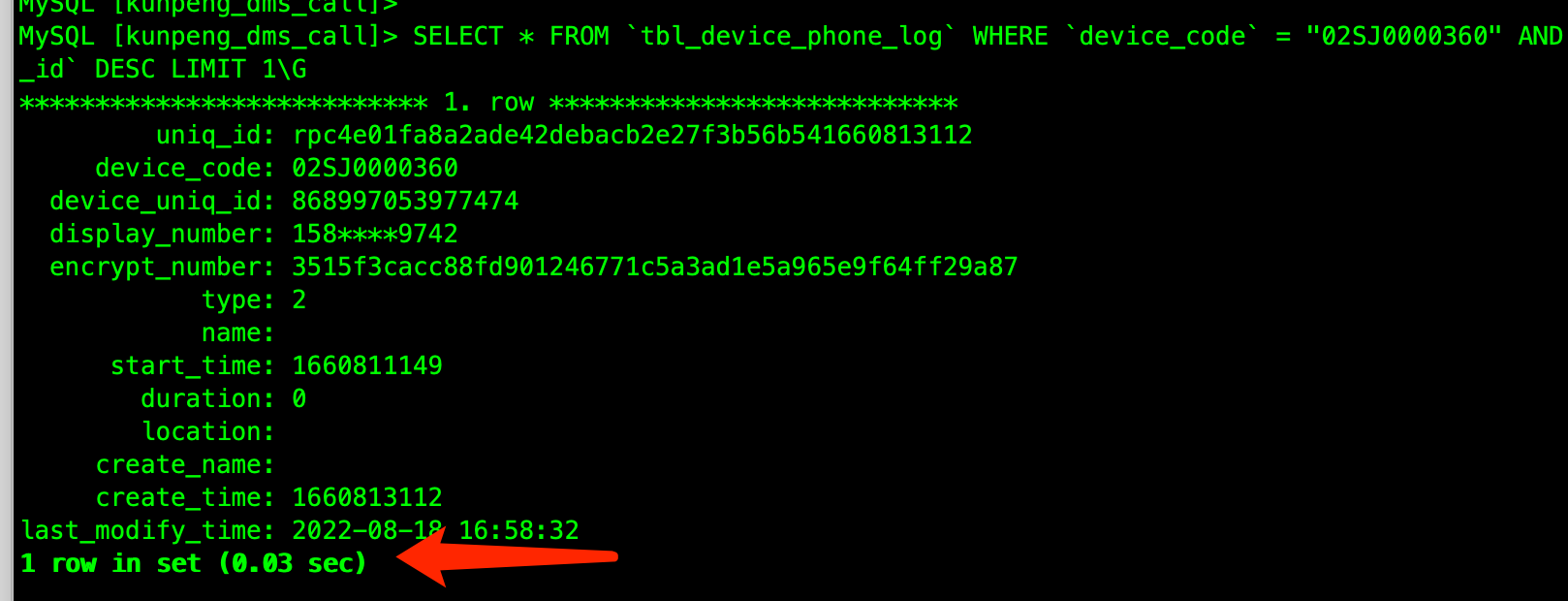
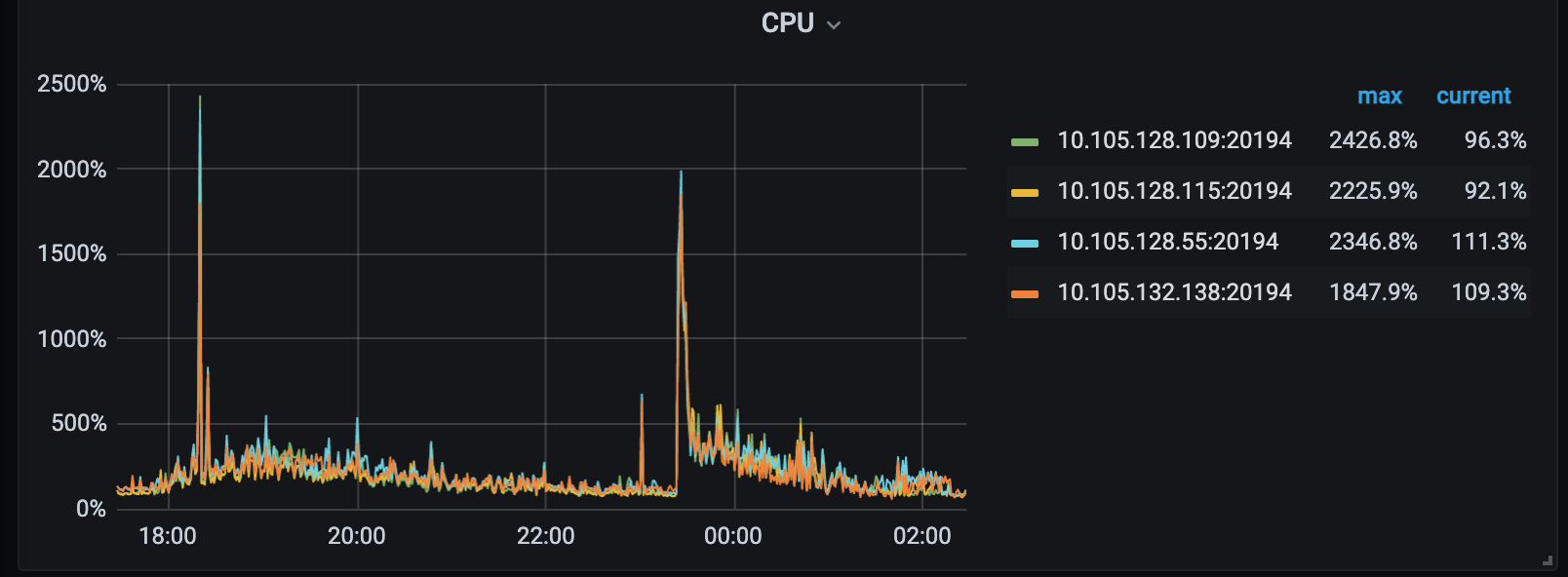
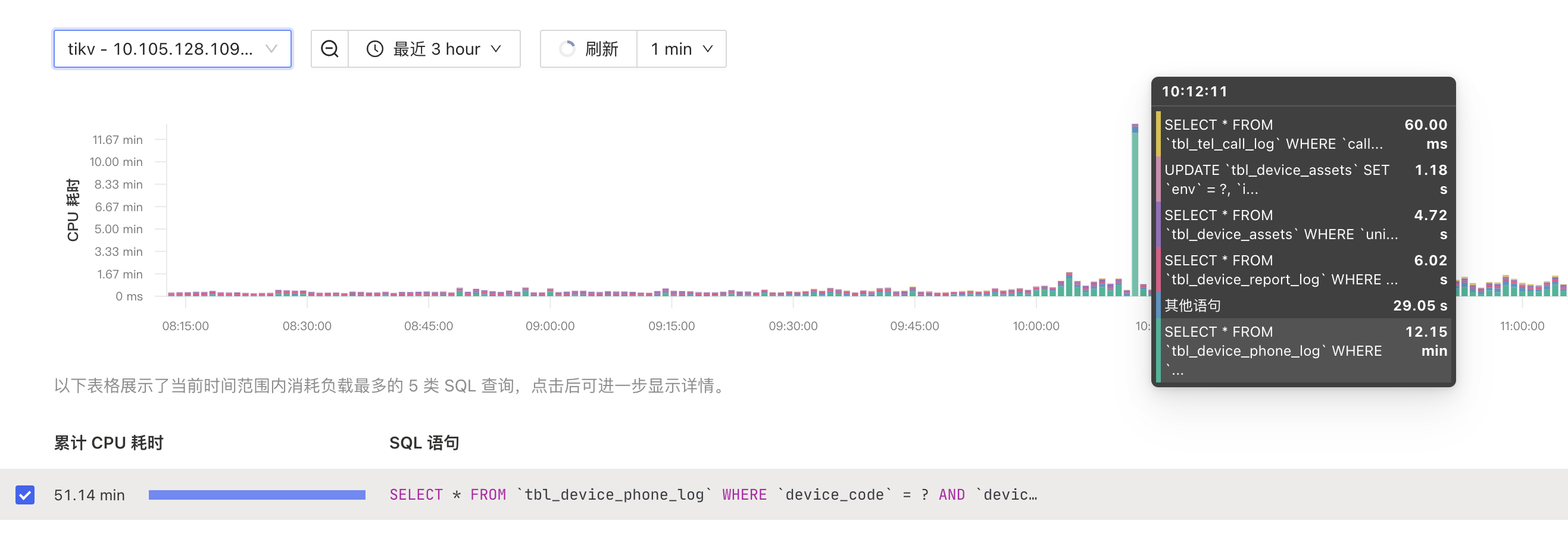
业务一个请求SQL 请求量波动,导致tikv cpu 突增。 手动查看sql 执行计划用到正确的索引,且执行速度0.05s
但是在慢查询中看到大量慢查询在0.5s 以上,且wait_time 字段较大。如何分析具体的性能瓶颈 ?
【附件:截图/日志/监控】
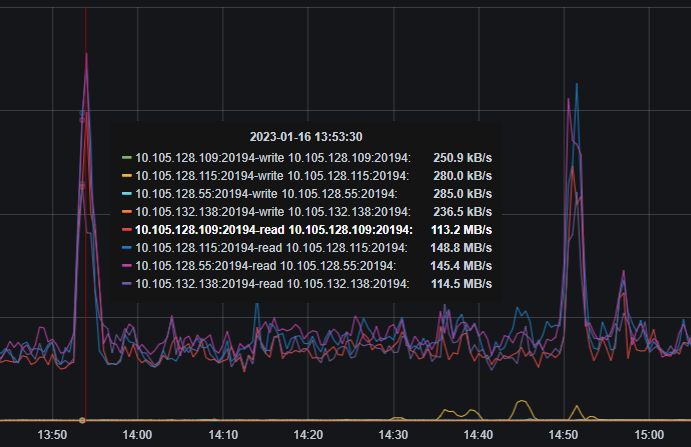
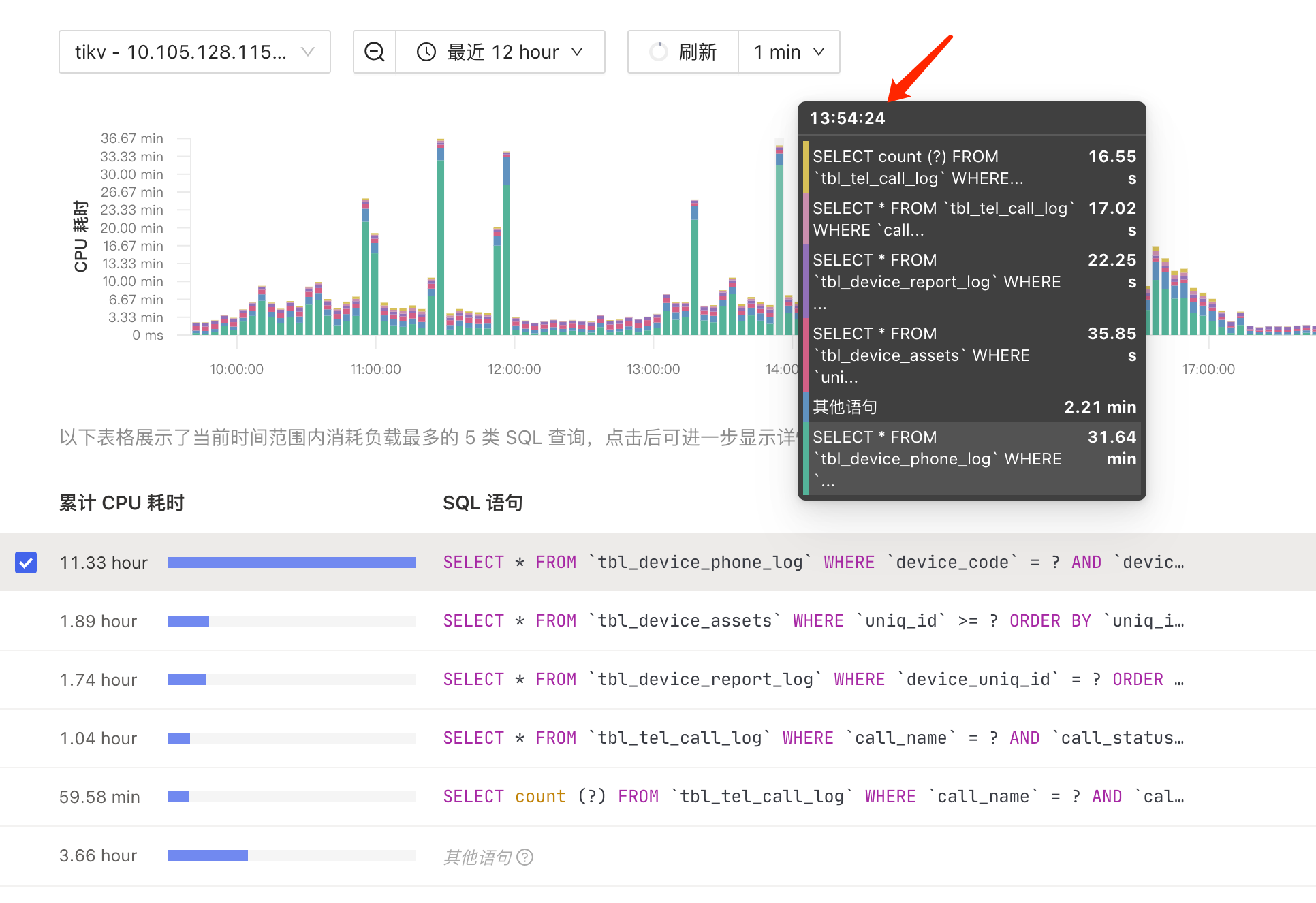
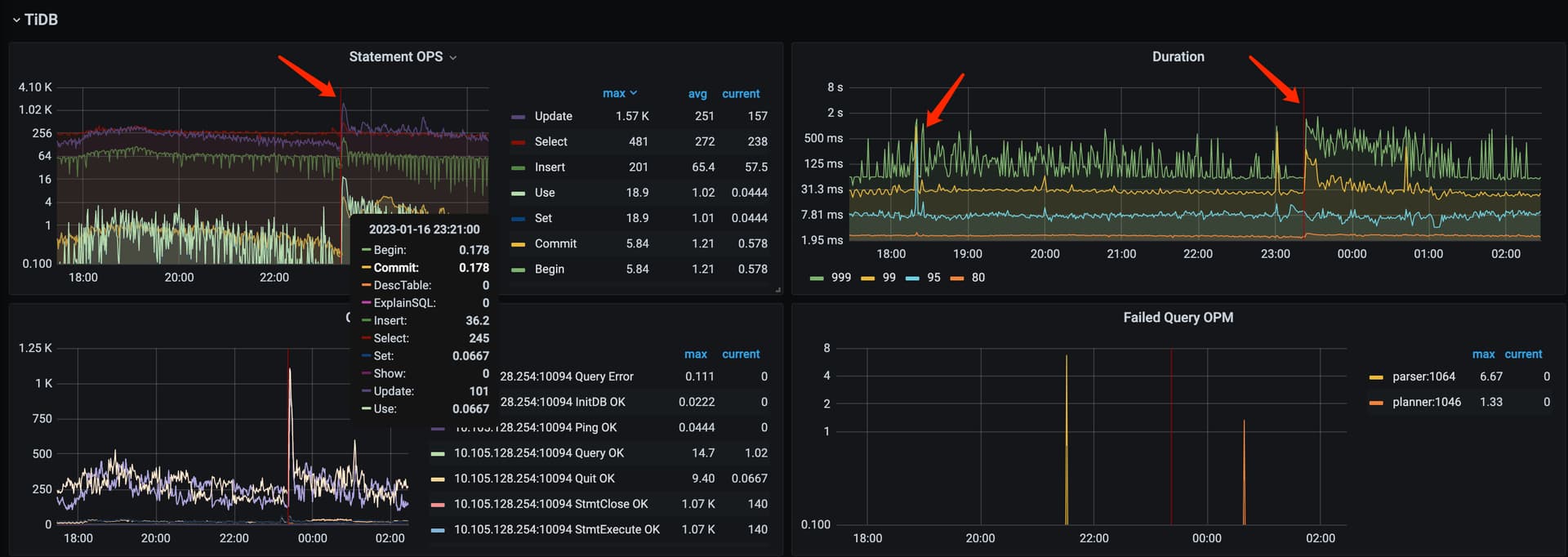
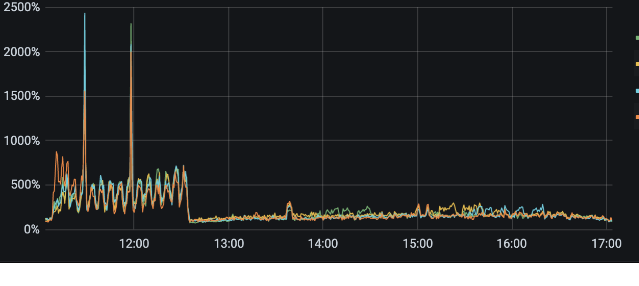
1、OverView 监控

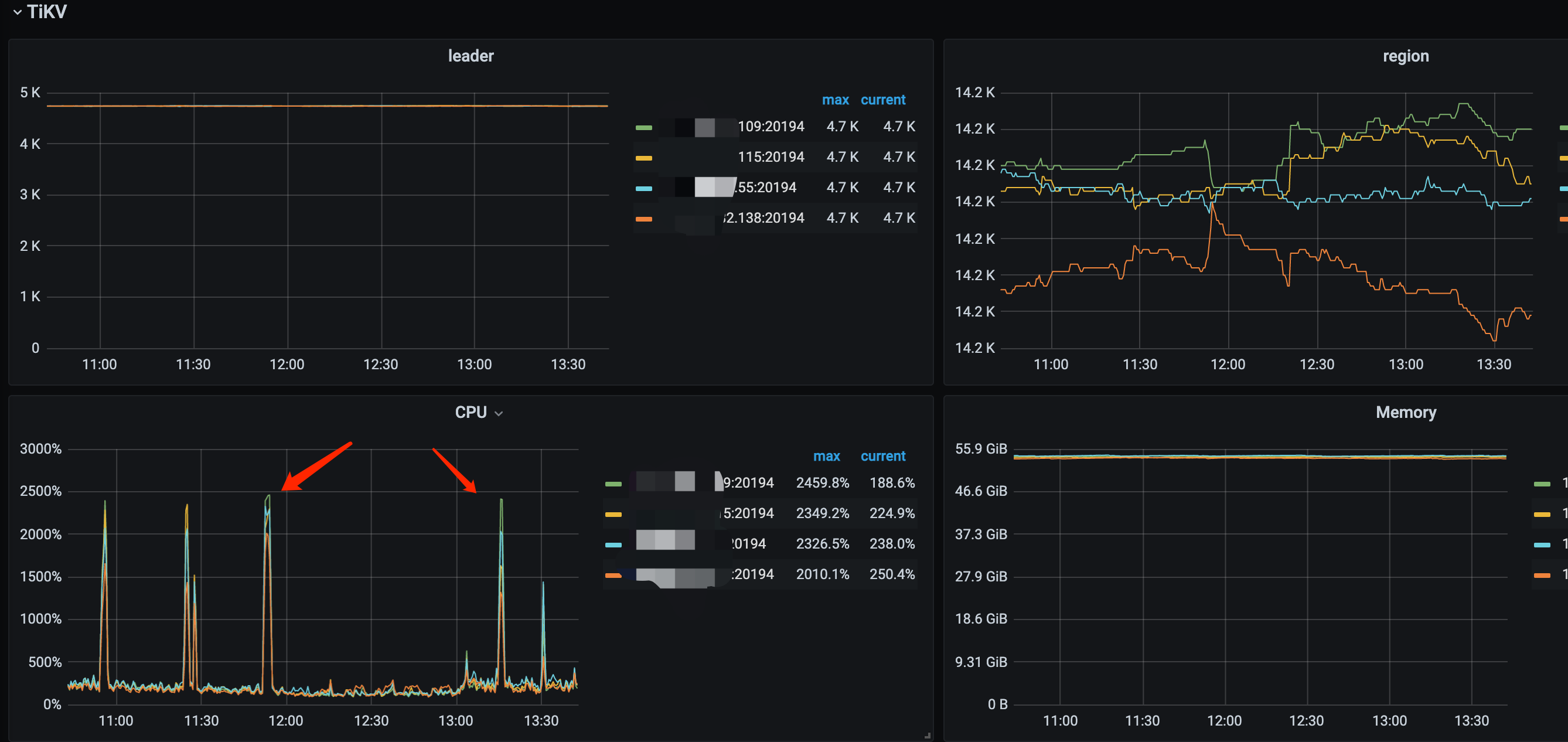

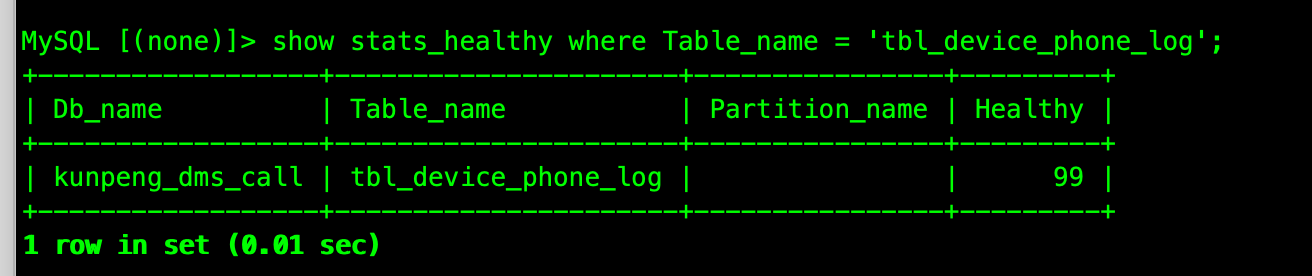
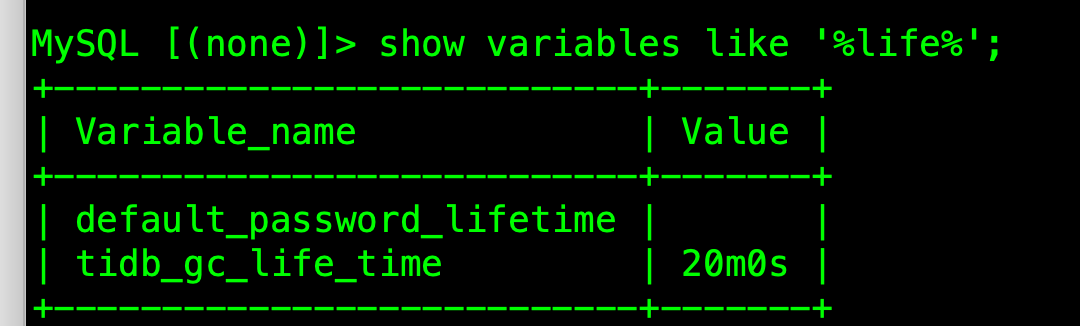
2、之前是gc 保留时间比较长48h, 改成20min 后依然出现抖动的现象
3、慢查询信息
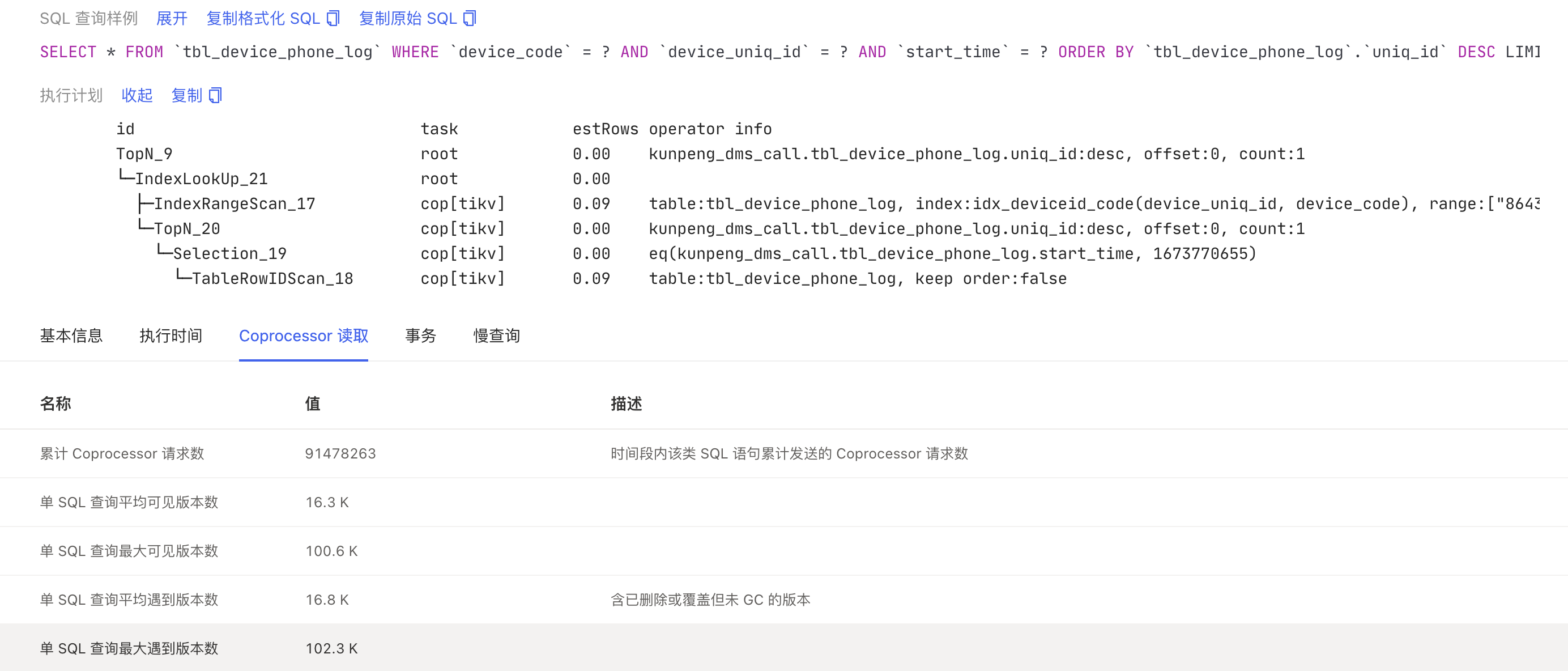
MySQL [INFORMATION_SCHEMA]> select * from CLUSTER_SLOW_QUERY where time >'2023-01-16 14:50:01' and query like 'SELECT * FROM `tbl_device_phone_log`%' limit 1\G
*************************** 1. row ***************************
INSTANCE: 10.105.128.254:10094
Time: 2023-01-16 14:50:01.004791
Txn_start_ts: 438790206288560132
User: kunpengdm_app
Host: 10.108.83.77
Conn_ID: 7677287164388118587
Exec_retry_count: 0
Exec_retry_time: 0
Query_time: 0.883878422
Parse_time: 0
Compile_time: 0.000522455
Rewrite_time: 0.000089441
Preproc_subqueries: 0
Preproc_subqueries_time: 0
Optimize_time: 0.000326578
Wait_TS: 0.000014092
Prewrite_time: 0
Wait_prewrite_binlog_time: 0
Commit_time: 0
Get_commit_ts_time: 0
Commit_backoff_time: 0
Backoff_types:
Resolve_lock_time: 0
Local_latch_wait_time: 0
Write_keys: 0
Write_size: 0
Prewrite_region: 0
Txn_retry: 0
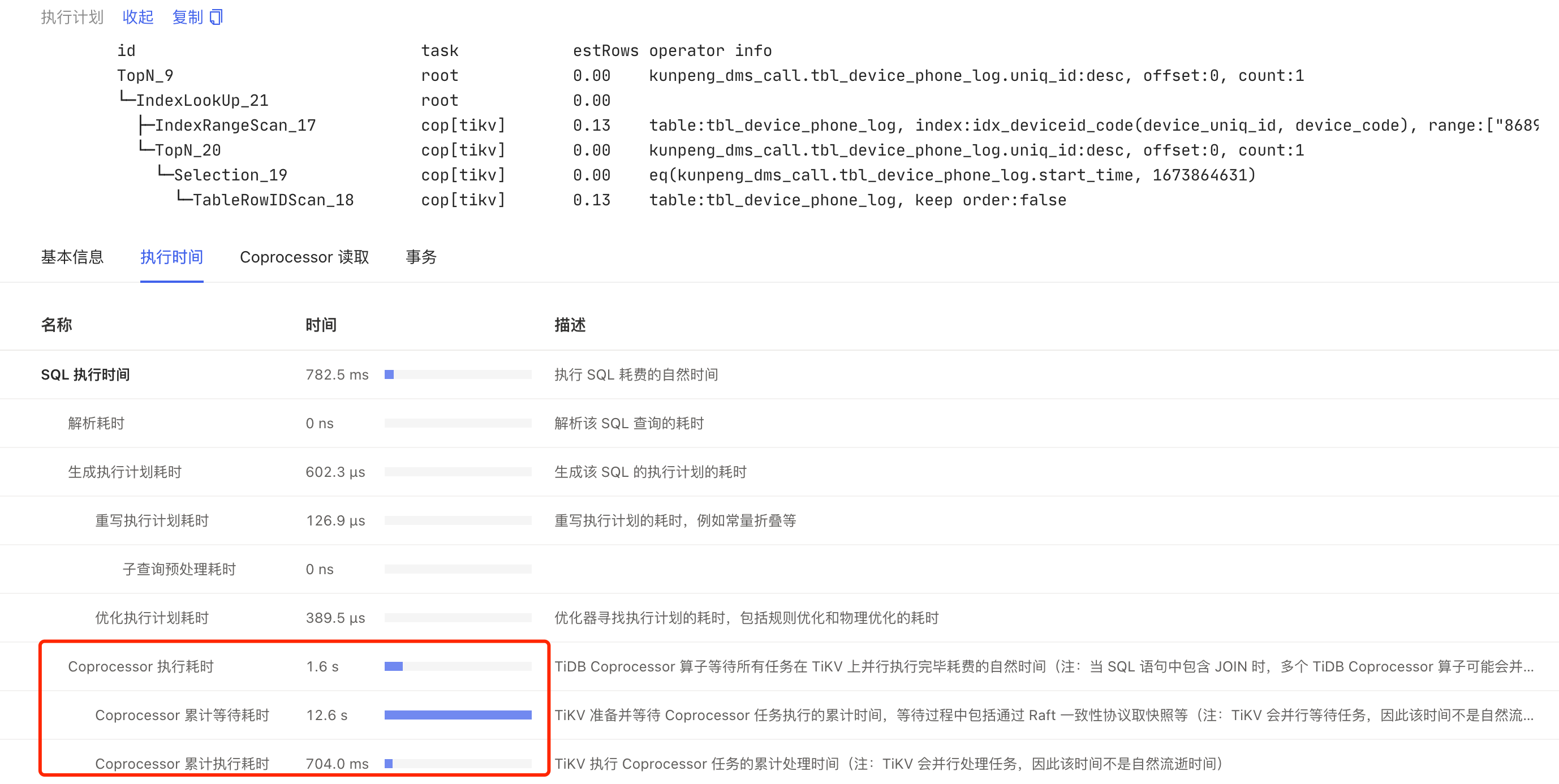
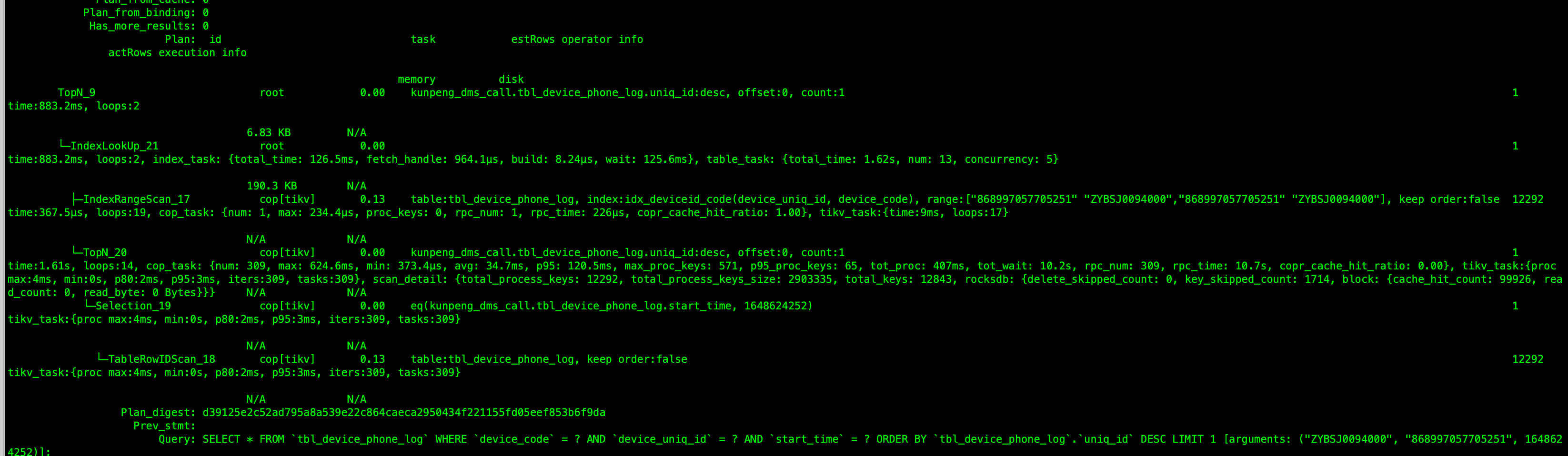
Cop_time: 1.6118884690000002
Process_time: 0.407
Wait_time: 10.181
Backoff_time: 0
LockKeys_time: 0
Request_count: 310
Total_keys: 12843
Process_keys: 12292
Rocksdb_delete_skipped_count: 0
Rocksdb_key_skipped_count: 1714
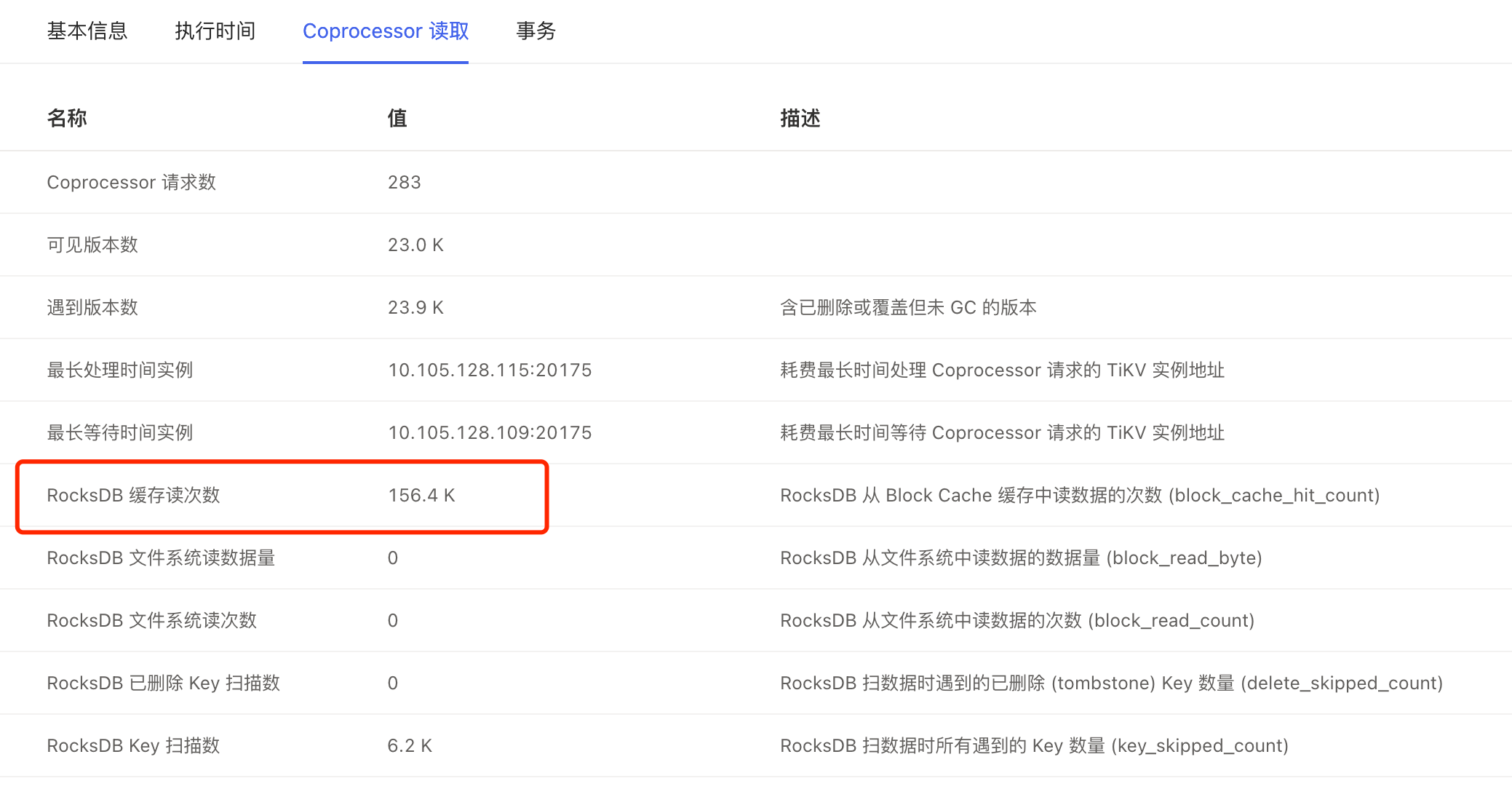
Rocksdb_block_cache_hit_count: 99926
Rocksdb_block_read_count: 0
Rocksdb_block_read_byte: 0
DB: kunpeng_dms_call
Index_names: [tbl_device_phone_log:idx_deviceid_code]
Is_internal: 0
Digest: 3c45957328e5e5c016cb360b20cbab5d94376adcd0bac898eff708c220567f2a
Stats: tbl_device_phone_log:438789586999574542
Cop_proc_avg: 0.001312903
Cop_proc_p90: 0.002
Cop_proc_max: 0.004
Cop_proc_addr: 10.105.128.115:20175
Cop_wait_avg: 0.032841935
Cop_wait_p90: 0.116
Cop_wait_max: 0.622
Cop_wait_addr: 10.105.128.115:20175
Mem_max: 194849
Disk_max: 0
KV_total: 10.704811784
PD_total: 0.000005371
Backoff_total: 0
Write_sql_response_total: 0.000003124
Result_rows: 1
Backoff_Detail:
Prepared: 1
Succ: 1
IsExplicitTxn: 0
IsWriteCacheTable: 0
Plan_from_cache: 0
Plan_from_binding: 0
Has_more_results: 0
Plan 截图
tikv-details 监控: coprocessor 部分异常
tidb-kunpeng_dms-TiKV-Details_2023-01-16T08_03_13.545Z.json (30.5 MB)
dashboard 截图
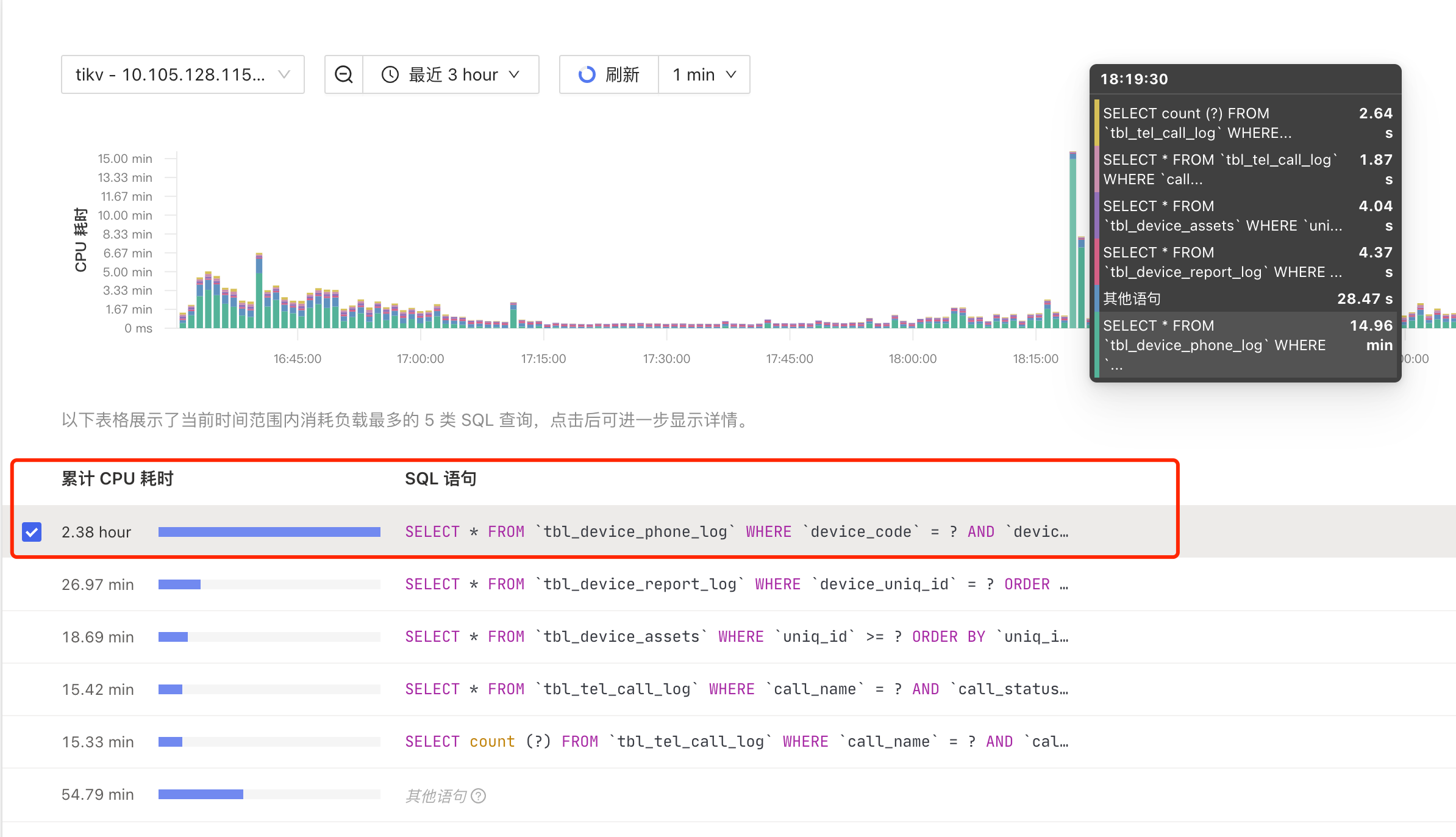
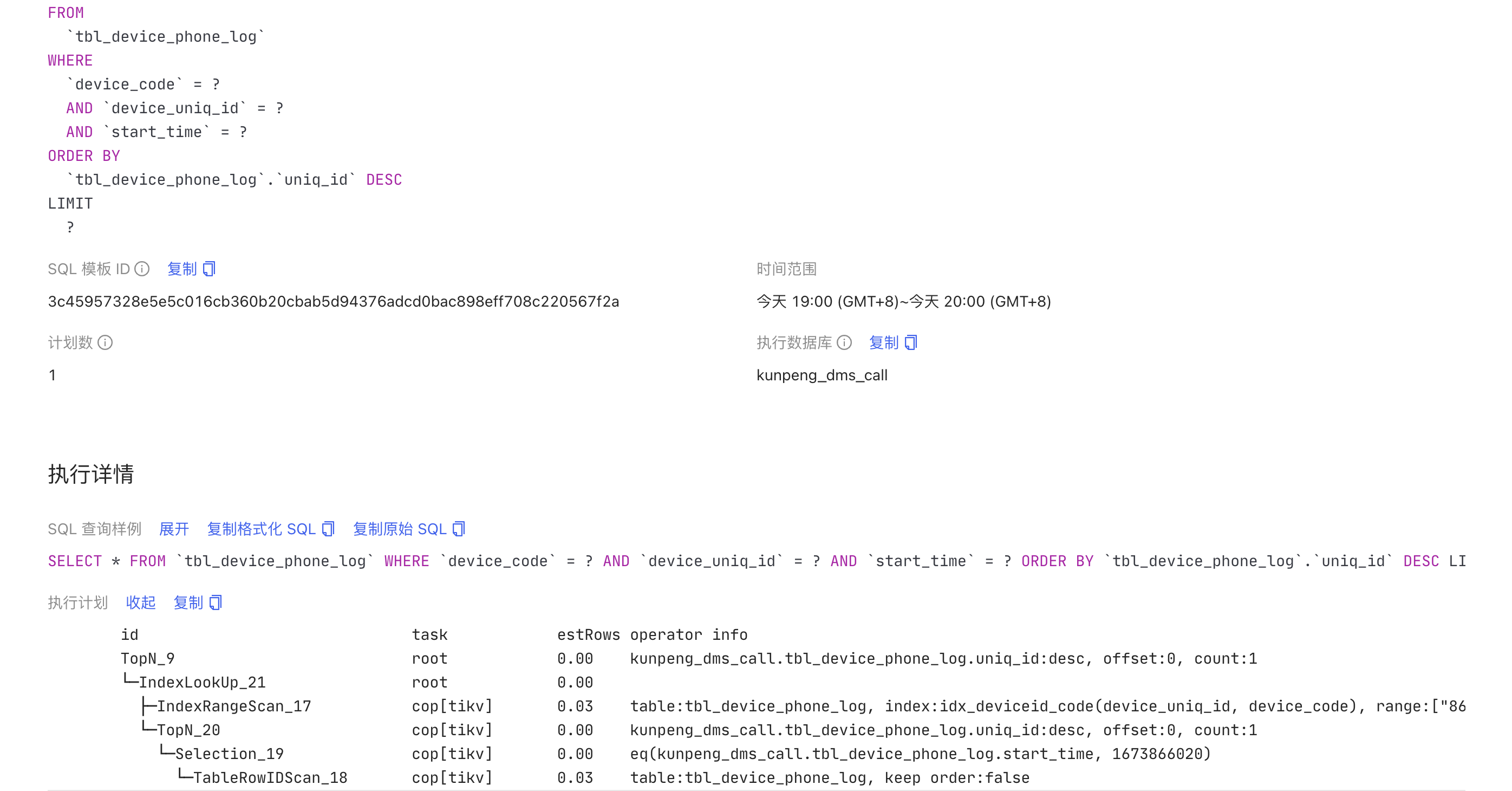
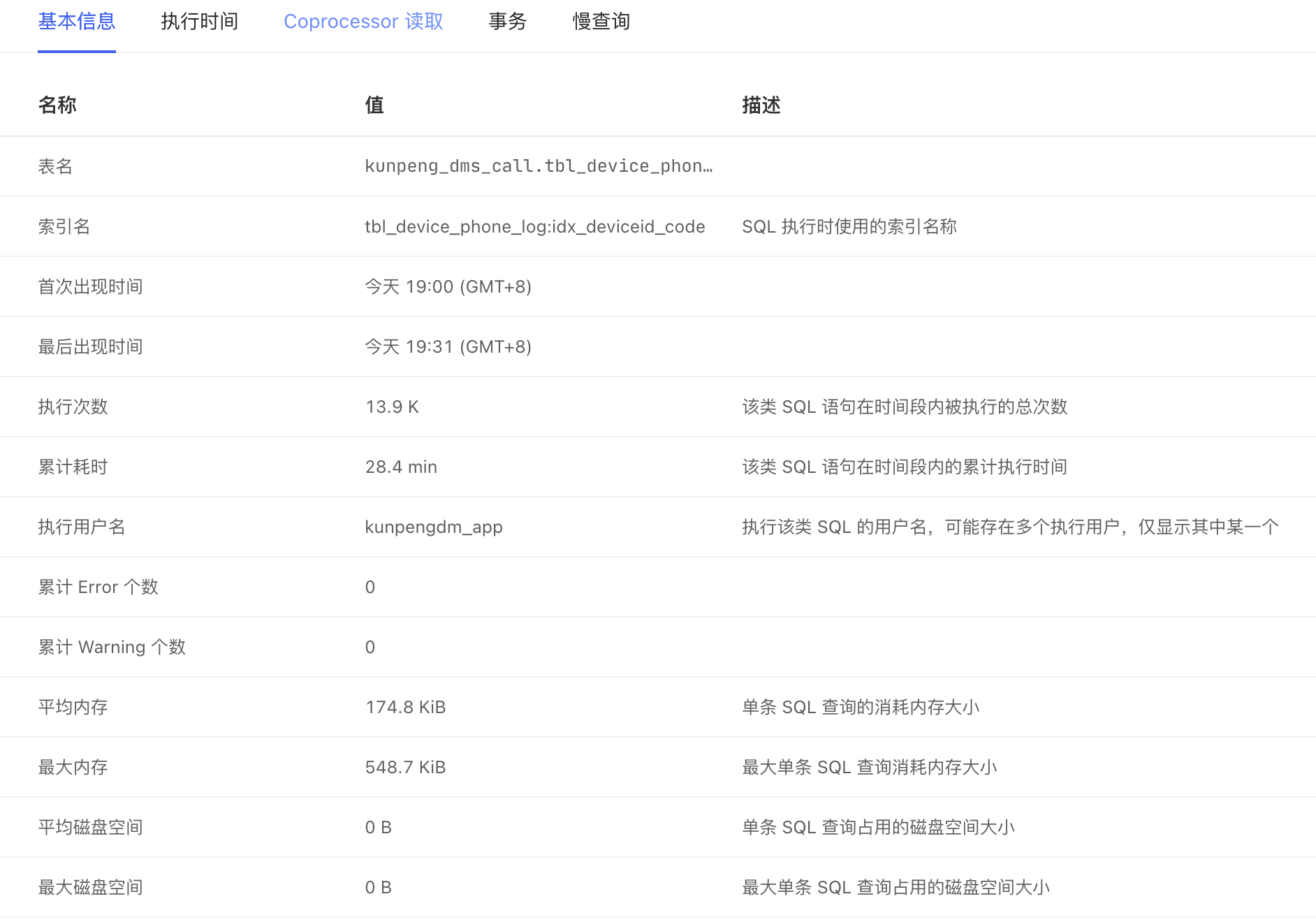
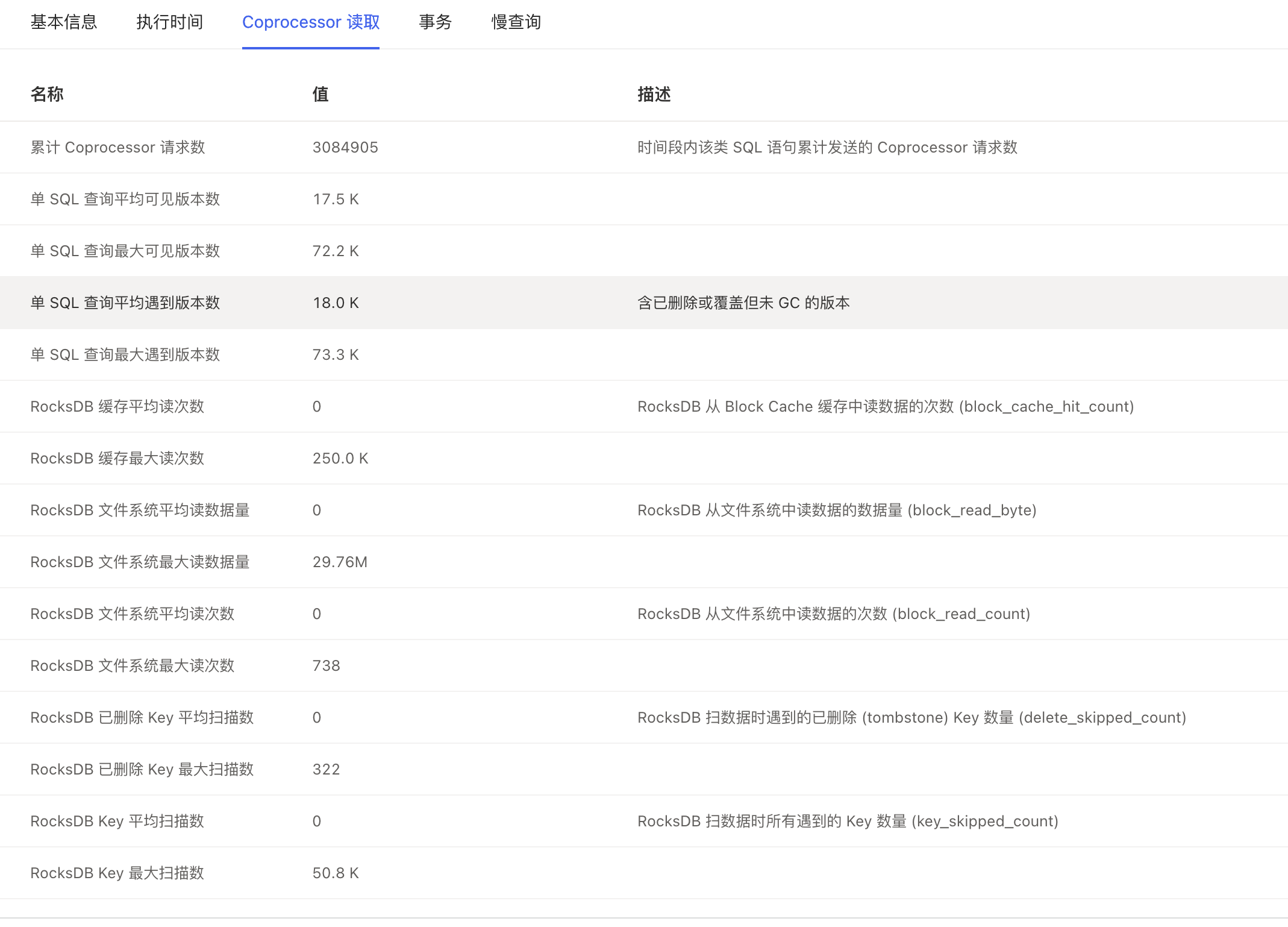
如何解读这种现象,以及如何处理?