为公司接下来要启动的一个项目做技术调研。预计一半结构体数据,一半半结构化数据。系统部署在内网机房。
如果是在部署在公有云上,估计就MySQL+MongoDB了,反正几乎不要运维。
如果在内网机房,怎么着也得分布式数据库。而且估计会拆分为几个子系统,每个子系统有自己独立的数据集群。
如果TiDB集群+MongoDB集群,感觉太复杂。期望一套搞定。
事务操作估计不多,结构化数据塞MongoDB问题也不大。但感觉MongoDB社区跟没有也没差别。
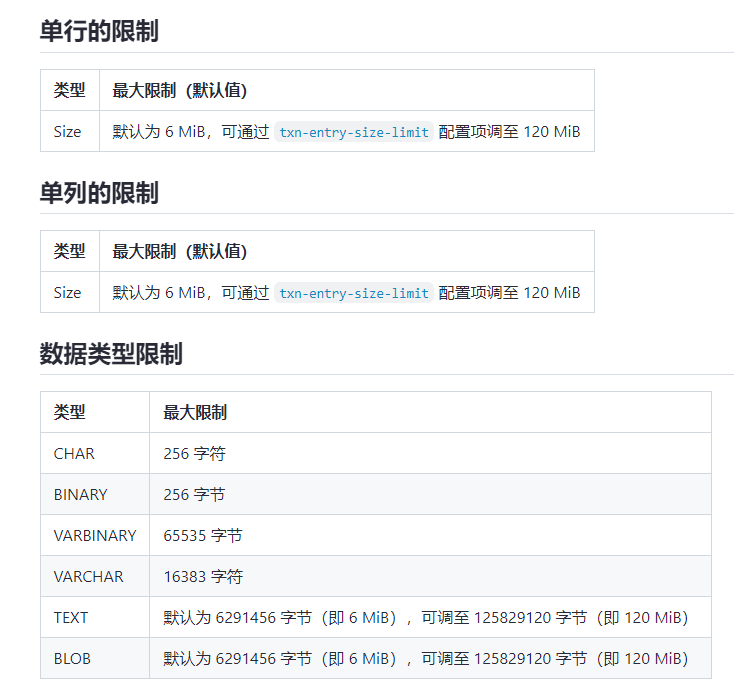
如果TiDB,很担心对半结构化数据的支持。查了文档,TiDB对json有一些简单的支持,貌似还在实验阶段:https://docs.pingcap.com/zh/tidb/dev/data-type-json
所以想寻求下tiDB处理半结构化数据的一些实践经验,和技术选型建议。