:4.19.90-17.ky10.aarch64 、 k8s: v1.24.9 、operator: 1.4.0 、tidb 6.1.2
dyrnq/local-volume-provisioner:v2.5.0 (POD未调整时区)
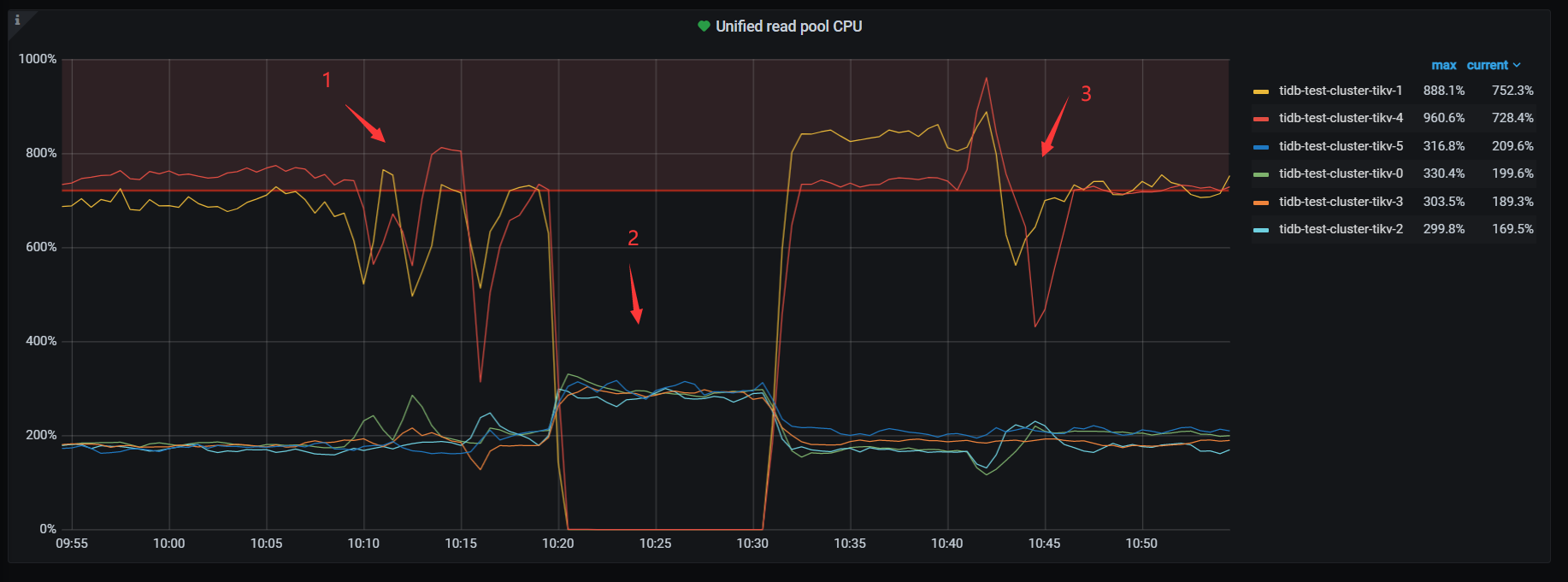
sysbench 初始化10张1亿表 然后64线程oltp_read测试,发现tikv-1、tikv-4存在热点问题。按照截图时间做了如下操作
1 尝试了几次配置shuffle leader调度 , 添加后热点tikv出现短暂下降后又立马回升。
2、对热点tikv添加 evict leader调度 ,热点tikv leader被驱逐后其他tikv利用率增高,删除evict 调度后,热点tikv立马回升到原来的利用率
3、对几个热点region做split ,并对一些热点region 做了手动调度,同样出现短暂下降后立马回升。
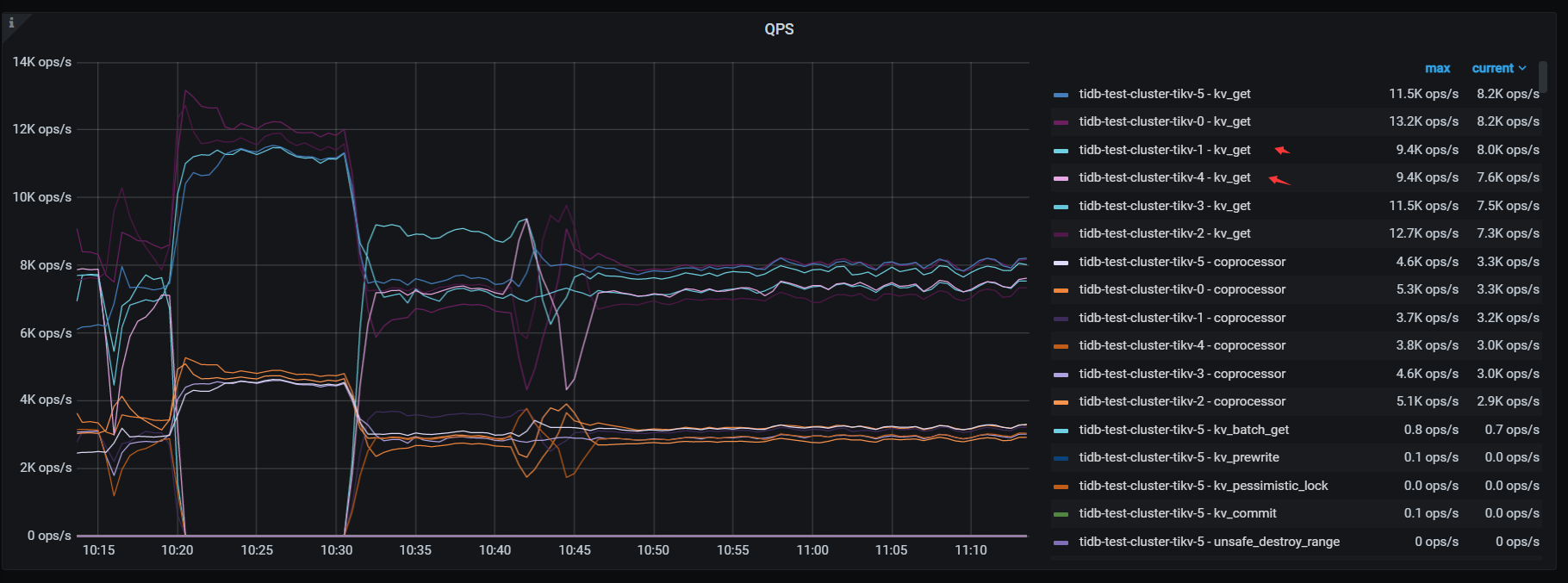
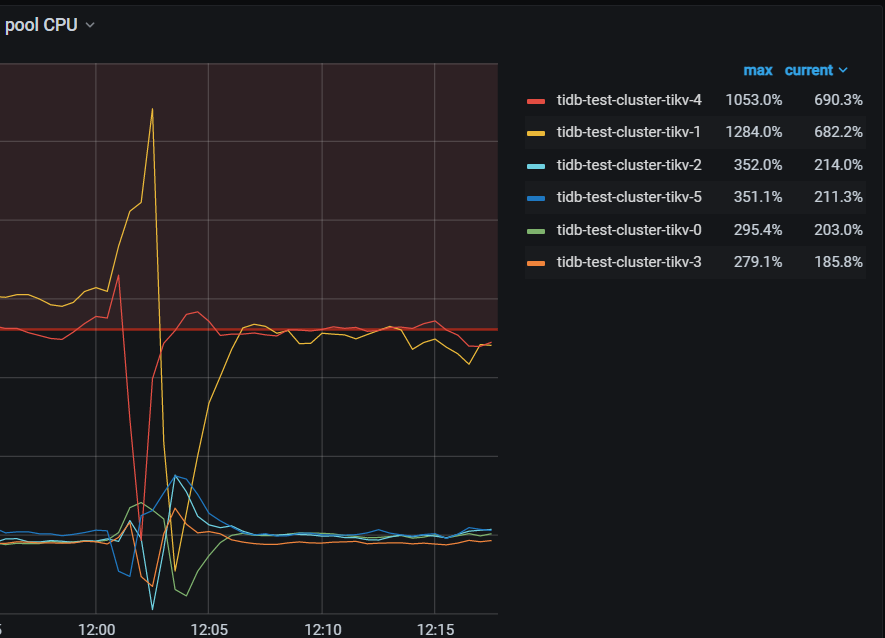
检查tikv QPS ,tikv-1 tikv-4 并不是最高
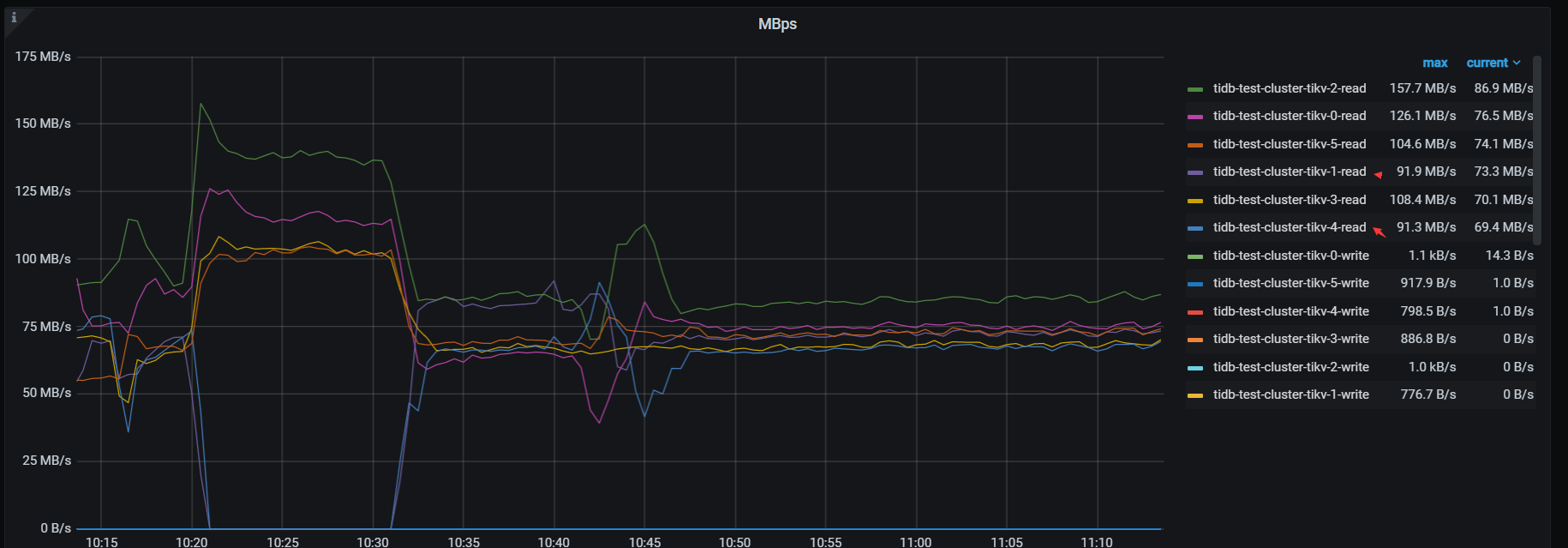
检查tikv 流量,tikv-1 tikv-4 并不是最高
检查热力图 读流量看没有明显的表

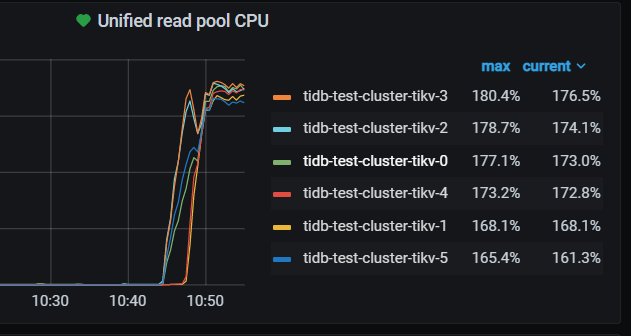
检查uinified read pool设置,发现tikv-1 tikv-4的max 为76 其他为12
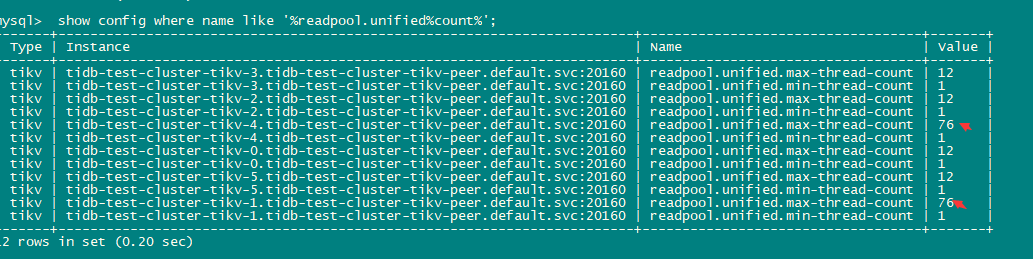
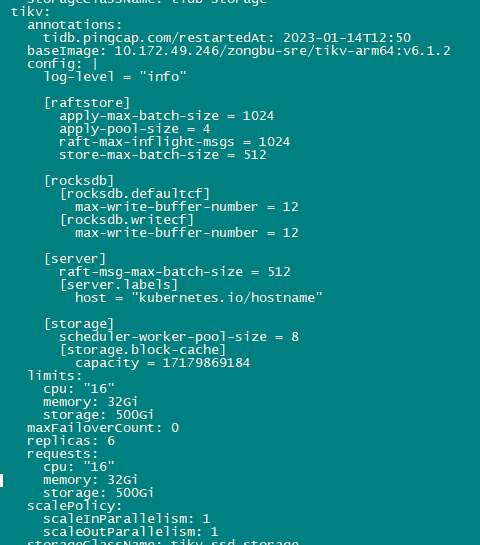
检查cluster设置 为设置unified pool参数 且 pod设置的是16C
调整unified read max thread count 参数为12,重启后无效果
通过pd-ctl store weight 调整热点leader weight 的权重为0 ,有部分leader未迁移(约12%,是当前其他节点的0.08%),有一点点的效果


检查read 的热点region, 看上去2个tikv 似乎并比重并不多,流量也是最低的
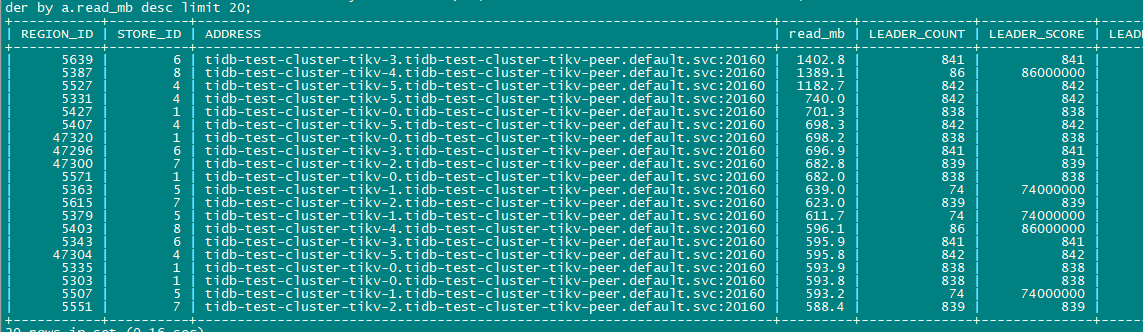
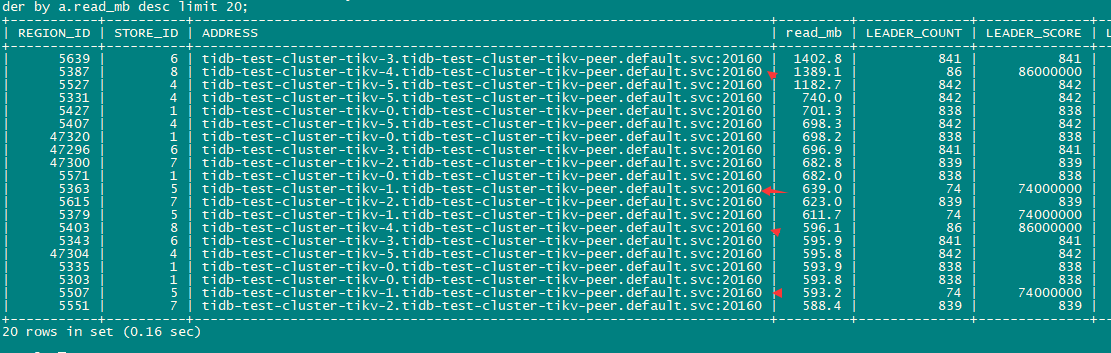
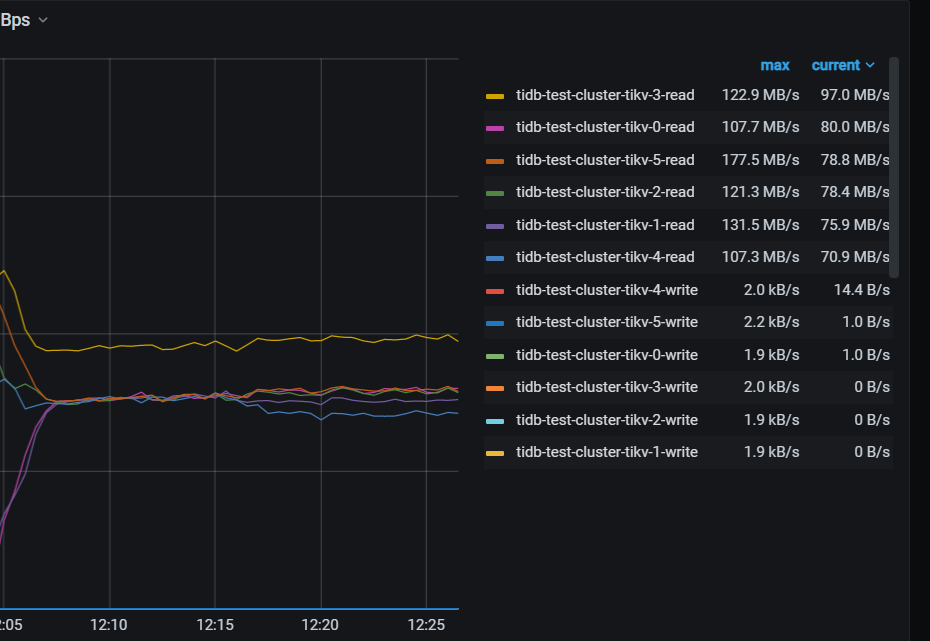
把tikv-4(storeid 8)上的3个top read region 转移到其他store, cpu出现短暂下降后立马又回升。


再次对2个热点tikv 添加evict leader 调度之后删除,保持sotre leader weight 为0 ,删除调度后2个tikv上仅有7个leader ,但2个tikv的CPU利用率 依然很高。

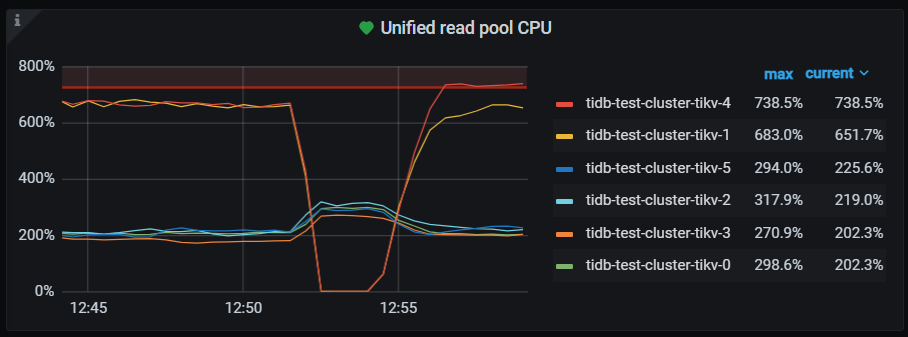
【问题】
1、 tikv-1 tikv-4的配置的readpool.unified.max-thread-count为76 (主机96C 的80%),超出了pod资源设置的16C ,看上去把主机的物理cpu数量作为了cpu count计算,为什么会出现这种情况?
2、 从前面的处理方式 监控数据看 ,尤其第二次evict leader + leader_weight=0 ,readpool.unified 的CPU利用率 是和2个tikv max-thread-count计算出76个来有某种联系,否则这种现象也太过于巧合了。
3、 leader weight 的计算百分比是到多少位?
@yiduoyunQ @neilshen 请2位大佬看看。