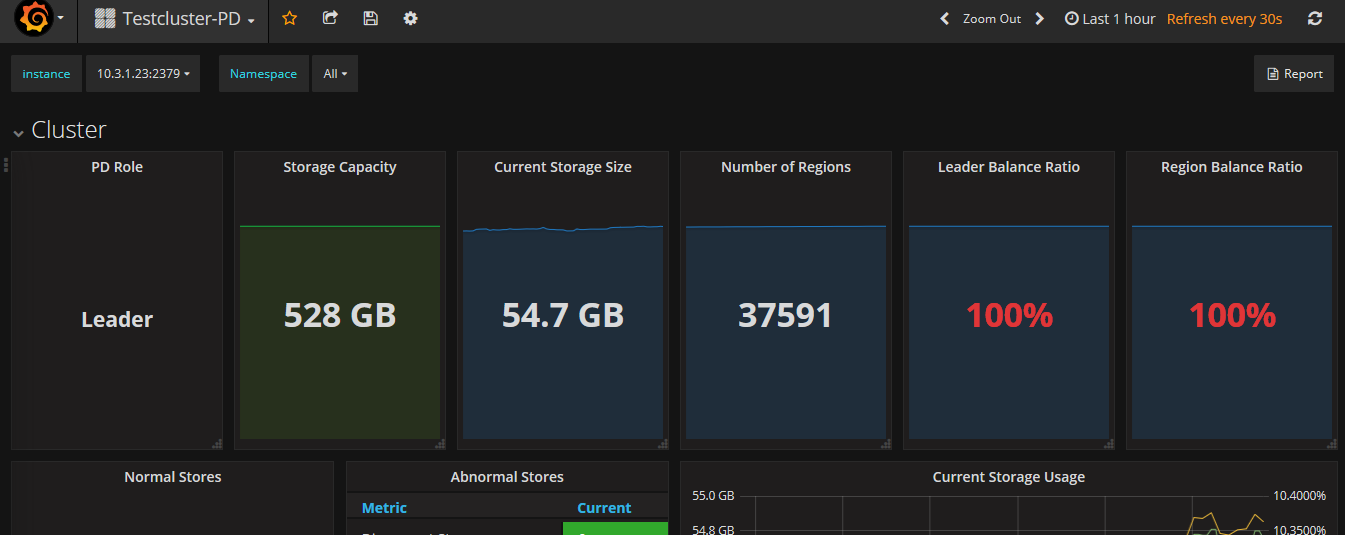
store 信息:
{
"count": 6,
"stores": [
{
"store": {
"id": 5,
"address": "10.3.1.27:20160",
"version": "2.1.15",
"state_name": "Up"
},
"status": {
"capacity": "98 GiB",
"available": "67 GiB",
"leader_count": 9182,
"leader_weight": 1,
"leader_score": 34194,
"leader_size": 34194,
"region_count": 22652,
"region_weight": 1,
"region_score": 90170,
"region_size": 90170,
"start_ts": "2019-11-28T04:31:01+08:00",
"last_heartbeat_ts": "2019-11-28T13:37:20.150941551+08:00",
"uptime": "9h6m19.150941551s"
}
},
{
"store": {
"id": 239050,
"address": "10.3.1.28:20160",
"version": "2.1.15",
"state_name": "Down"
},
"status": {
"leader_weight": 1,
"region_weight": 1,
"start_ts": "1970-01-01T08:00:00+08:00"
}
},
{
"store": {
"id": 246151,
"address": "10.3.1.30:20160",
"version": "2.1.15",
"state_name": "Up"
},
"status": {
"capacity": "98 GiB",
"available": "94 GiB",
"leader_count": 5799,
"leader_weight": 1,
"leader_score": 18488,
"leader_size": 18488,
"region_count": 7356,
"region_weight": 1,
"region_score": 21294,
"region_size": 21294,
"start_ts": "2019-11-28T04:41:52+08:00",
"last_heartbeat_ts": "2019-11-28T13:37:15.531333289+08:00",
"uptime": "8h55m23.531333289s"
}
},
{
"store": {
"id": 246152,
"address": "10.3.1.29:20160",
"version": "2.1.15",
"state_name": "Up"
},
"status": {
"capacity": "98 GiB",
"available": "88 GiB",
"leader_count": 3698,
"leader_weight": 1,
"leader_score": 18460,
"leader_size": 18460,
"region_count": 3811,
"region_weight": 1,
"region_score": 21134,
"region_size": 21134,
"start_ts": "2019-11-28T04:41:52+08:00",
"last_heartbeat_ts": "2019-11-28T13:37:23.564446403+08:00",
"uptime": "8h55m31.564446403s"
}
},
{
"store": {
"id": 1,
"address": "10.3.1.25:20160",
"state": 1,
"version": "2.1.15",
"state_name": "Offline"
},
"status": {
"capacity": "98 GiB",
"available": "82 GiB",
"leader_count": 13831,
"leader_weight": 1,
"leader_score": 32451,
"leader_size": 32451,
"region_count": 24990,
"region_weight": 1,
"region_score": 55995,
"region_size": 55995,
"start_ts": "2019-11-28T04:30:58+08:00",
"last_heartbeat_ts": "2019-11-28T13:37:23.563929082+08:00",
"uptime": "9h6m25.563929082s"
}
},
{
"store": {
"id": 4,
"address": "10.3.1.26:20160",
"state": 1,
"version": "2.1.15",
"state_name": "Offline"
},
"status": {
"capacity": "98 GiB",
"available": "65 GiB",
"leader_count": 5151,
"leader_weight": 1,
"leader_score": 21092,
"leader_size": 21092,
"region_count": 16533,
"region_weight": 1,
"region_score": 60839,
"region_size": 60839,
"start_ts": "2019-11-28T04:31:00+08:00",
"last_heartbeat_ts": "2019-11-28T13:37:23.180811015+08:00",
"uptime": "9h6m23.180811015s"
}
}
]
}