panbc
(Panbc)
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
panbc
(Panbc)
2
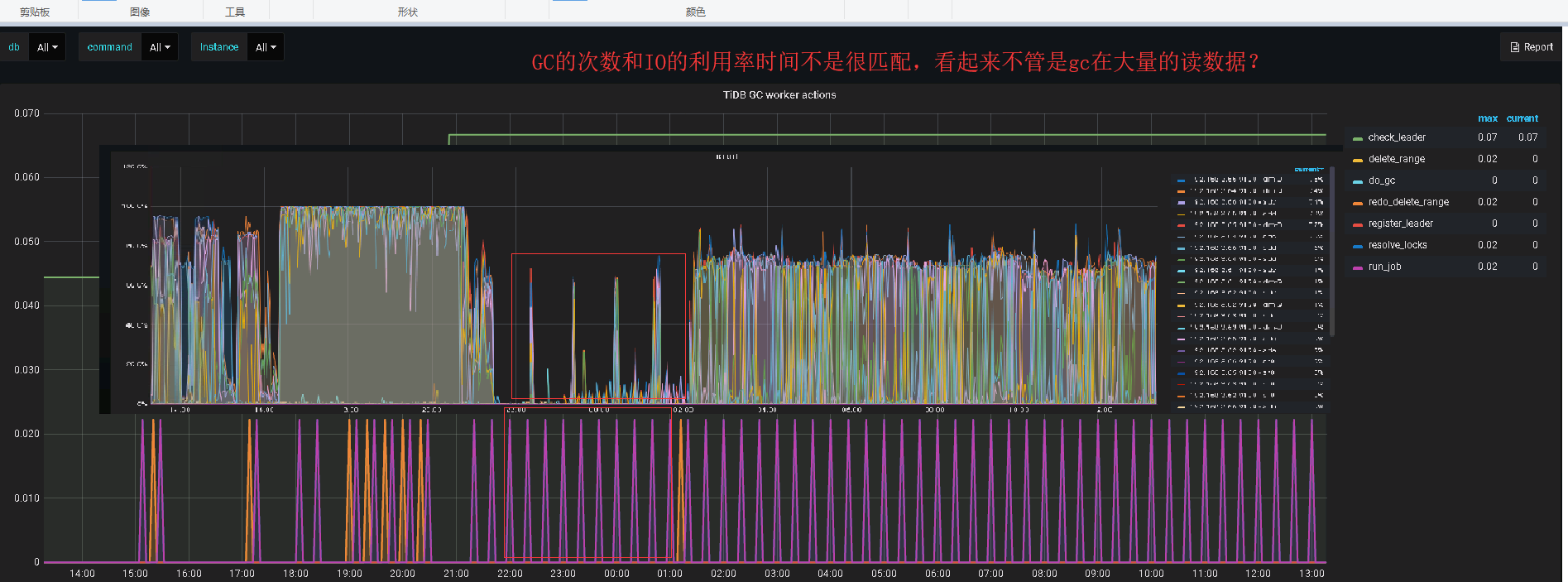
看gc的作用,是在删除旧数据,如果是gc的问题,有没有地方可以看gc的进度,因为这个持续时间很长了
select VARIABLE_NAME, VARIABLE_VALUE from mysql.tidb;
麻烦看下 GC 配置
panbc
(Panbc)
8
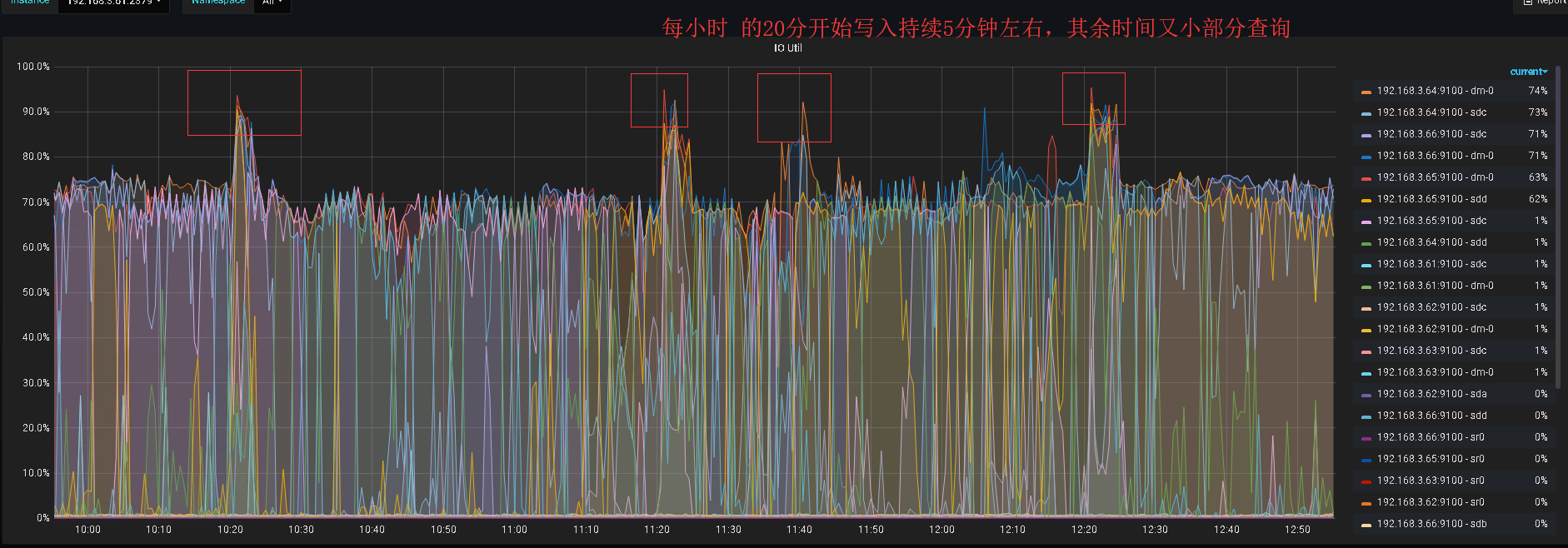
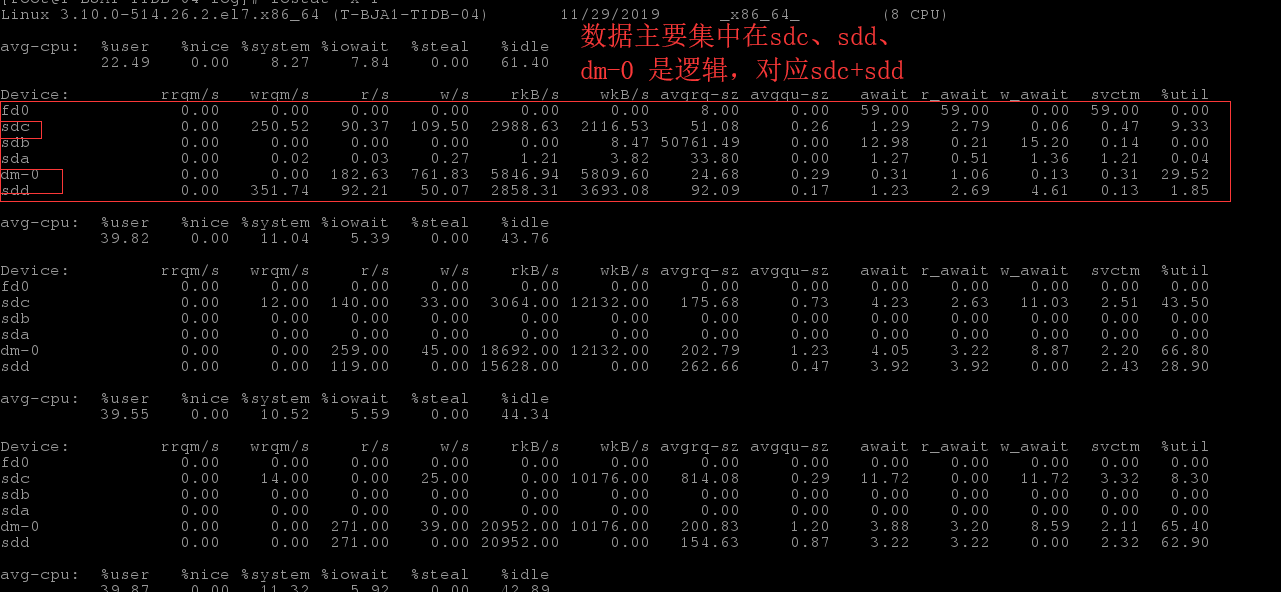
上面抓图的时候,没有大量的读写。io看起来还是很高。
从 iostat 的情况看,sdc 盘的读写压力并不大,但是 util 比较高,看起来不像是 tikv 引起的,建议你这边检查一下磁盘
WentaoJin
(Wentao.Jin)
14
1、gc_worker 3.0 是 分布式gc,按 tikv 节点单独处理自己得 gc,gc 说明你系统内应该有比较多得 truncate 、drop、delete 操作,gc 有默认并发,可以调整,另外 gc life time 调整越大,gc 时间就可以能越长,详情可以参考链接
https://pingcap.com/docs-cn/stable/reference/garbage-collection/configuration/
2、关于 lock 与 gc worker 没关系,其表示存在primary key 冲突
panbc
(Panbc)
15
是的,最近在大量删除数据,单表数据量已经达到了70亿,有些历史数据不需要了,需要删除,现在每天新进数据1500万,后台在不停的删除数据,但是目前感觉现在gc 删除很慢,一直在gc worker。
1.有什么办法可以加快删除速度吗
2.从哪里可以查看删除的进度吗。
根据你的描述,在该问题发生之前,删除了大量的数据,所以前台没什么读写流量,后台还是一直在 GC 工作,导致 IO 资源占用较高。
如何加快 GC 速度,目前有如下方法:
4.3.11 对数据做删除操作之后,空间回收比较慢,如何处理?
可以设置并行 GC,加快对空间的回收速度。默认并发为 1,最大可调整为 tikv 实例数量的 50%。可使用 update mysql.tidb set VARIABLE_VALUE="3" where VARIABLE_NAME="tikv_gc_concurrency"; 命令来调整。
请根据当前集群资源适当调整。
panbc
(Panbc)
18
现在安装了3个 tikv的实例,是不是就没有办法调整了?
如果资源没有空闲的话,调整参数效果也不大了。
后面可以考虑扩容 tikv
panbc
(Panbc)
20
看了官网的一些帮助,可以借助分区表,例如 我吧历史数据按照年度进行分区,删除的时候 业务是可以按照年度进行删除的。这个地方有2个疑问
1.对于单表达到70亿的情况下按照业务时间(年月日),增加分区线上会不会有什么影响?
原来没有分区。不清楚这种对历史数据增加分区,后台进行了什么操作
2.如果增加分区之后,是否可以按照分区表进行删除,这样就可以直接删除文件,提升删除数据的速度?