【 TiDB 使用环境】生产环境
【 TiDB 版本】v5.4.3
【遇到的问题:问题现象及影响】pd集群一月之内挂掉两次
【资源配置】(128G+40核+2Tnvme) * 5节点
图一:
图二:
图三:

图四:
图五:

图6:

pd_63.log (2.6 KB)
pd_62.log (732.5 KB)
pd_61.log (2.6 KB)
一月之内出现了两次了pd挂掉,整个集群都不能访问。
【 TiDB 使用环境】生产环境
【 TiDB 版本】v5.4.3
【遇到的问题:问题现象及影响】pd集群一月之内挂掉两次
【资源配置】(128G+40核+2Tnvme) * 5节点
图一:
图二:
图三:
图四:
图五:
图6:
pd_63.log (2.6 KB)
pd_62.log (732.5 KB)
pd_61.log (2.6 KB)
一月之内出现了两次了pd挂掉,整个集群都不能访问。
提问者为同事,我补充一下目前观察到的时间线
1) 2023/01/14 00:09:54
pd follower 61 和 63 报警报日志,连续十多次,每秒一次
[2023/01/14 00:09:54.890 +08:00] [WARN] [manager.go:102] ["failed to reload persist options"]
[2023/01/14 00:09:55.890 +08:00] [WARN] [manager.go:102] ["failed to reload persist options"]
[2023/01/14 00:09:56.890 +08:00] [WARN] [manager.go:102] ["failed to reload persist options"]
[2023/01/14 00:09:57.890 +08:00] [WARN] [manager.go:102] ["failed to reload persist options"]
[2023/01/14 00:09:58.890 +08:00] [WARN] [manager.go:102] ["failed to reload persist options"]
[2023/01/14 00:09:59.890 +08:00] [WARN] [manager.go:102] ["failed to reload persist options"]
[2023/01/14 00:10:00.890 +08:00] [WARN] [manager.go:102] ["failed to reload persist options"]
...
2)2023/01/14 00:14:00
pd leader监控 , grpc请求中 wait 和 tso 超10秒,同时tso开始量急剧变为500qps(之前都是0)
部分日志如下:
[2023/01/14 00:11:50.857 +08:00] [INFO] [grpc_service.go:1353] ["update service GC safe point"] [service-id=ticdc] [expire-at=1673712710] [safepoint=438731094848176136]
[2023/01/14 00:12:50.860 +08:00] [INFO] [grpc_service.go:1353] ["update service GC safe point"] [service-id=ticdc] [expire-at=1673712770] [safepoint=438731110589661194]
[2023/01/14 00:13:51.010 +08:00] [INFO] [grpc_service.go:1353] ["update service GC safe point"] [service-id=ticdc] [expire-at=1673712830] [safepoint=438731125492547608]
[2023/01/14 00:13:54.535 +08:00] [INFO] [periodic.go:135] ["starting auto periodic compaction"] [revision=39749914] [compact-period=1h0m0s]
[2023/01/14 00:13:54.536 +08:00] [INFO] [index.go:189] ["compact tree index"] [revision=39749914]
[2023/01/14 00:13:54.537 +08:00] [INFO] [periodic.go:146] ["completed auto periodic compaction"] [revision=39749914] [compact-period=1h0m0s] [took=1h0m0.004980515s]
[2023/01/14 00:13:55.392 +08:00] [INFO] [kvstore_compaction.go:55] ["finished scheduled compaction"] [compact-revision=39749914] [took=855.063741ms]
[2023/01/14 00:14:51.209 +08:00] [INFO] [grpc_service.go:1353] ["update service GC safe point"] [service-id=ticdc] [expire-at=1673712891] [safepoint=438731142073417748]
[2023/01/14 00:14:55.959 +08:00] [INFO] [grpc_service.go:1353] ["update service GC safe point"] [service-id=gc_worker] [expire-at=9223372036854775807] [safepoint=4387084949
02493184]
[2023/01/14 00:16:38.913 +08:00] [INFO] [grpc_service.go:1287] ["updated gc safe point"] [safe-point=438708494902493184]
[2023/01/14 00:20:22.006 +08:00] [INFO] [operator_controller.go:440] ["add operator"] [region-id=46845377] [operator="\"transfer-hot-read-leader {transfer leader: store 5 t
o 4} (kind:hot-region,leader, region:46845377(20817,41987), createAt:2023-01-14 00:20:22.006599095 +0800 CST m=+2034391.895374284, startAt:0001-01-01 00:00:00 +0000 UTC, cu
rrentStep:0, steps:[transfer leader from store 5 to store 4])\""] [additional-info=]
[2023/01/14 00:20:22.006 +08:00] [INFO] [operator_controller.go:638] ["send schedule command"] [region-id=46845377] [step="transfer leader from store 5 to store 4"] [source
=create]
[2023/01/14 00:20:22.008 +08:00] [INFO] [region.go:549] ["leader changed"] [region-id=46845377] [from=5] [to=4]
[2023/01/14 00:20:22.008 +08:00] [INFO] [operator_controller.go:555] ["operator finish"] [region-id=46845377] [takes=1.586244ms] [operator="\"transfer-hot-read-leader {tran
sfer leader: store 5 to 4} (kind:hot-region,leader, region:46845377(20817,41987), createAt:2023-01-14 00:20:22.006599095 +0800 CST m=+2034391.895374284, startAt:2023-01-14
00:20:22.006833891 +0800 CST m=+2034391.895609077, currentStep:1, steps:[transfer leader from store 5 to store 4]) finished\""] [additional-info=]
[2023/01/14 00:21:46.234 +08:00] [INFO] [operator_controller.go:440] ["add operator"] [region-id=46975492] [operator="\"transfer-hot-write-leader {transfer leader: store 4
to 7} (kind:hot-region,leader, region:46975492(15735,3806), createAt:2023-01-14 00:21:46.234616792 +0800 CST m=+2034476.123391980, startAt:0001-01-01 00:00:00 +0000 UTC, cu
rrentStep:0, steps:[transfer leader from store 4 to store 7])\""] [additional-info=]
[2023/01/14 00:21:46.234 +08:00] [INFO] [operator_controller.go:638] ["send schedule command"] [region-id=46975492] [step="transfer leader from store 4 to store 7"] [source
=create]
[2023/01/14 00:21:46.237 +08:00] [INFO] [region.go:549] ["leader changed"] [region-id=46975492] [from=4] [to=7]
[2023/01/14 00:21:46.237 +08:00] [INFO] [operator_controller.go:555] ["operator finish"] [region-id=46975492] [takes=2.933989ms] [operator="\"transfer-hot-write-leader {tra
nsfer leader: store 4 to 7} (kind:hot-region,leader, region:46975492(15735,3806), createAt:2023-01-14 00:21:46.234616792 +0800 CST m=+2034476.123391980, startAt:2023-01-14
00:21:46.234828062 +0800 CST m=+2034476.123603264, currentStep:1, steps:[transfer leader from store 4 to store 7]) finished\""] [additional-info=]
[2023/01/14 00:24:55.935 +08:00] [INFO] [grpc_service.go:1353] ["update service GC safe point"] [service-id=gc_worker] [expire-at=9223372036854775807] [safepoint=4387086521
89155328]
[2023/01/14 00:26:38.864 +08:00] [INFO] [grpc_service.go:1287] ["updated gc safe point"] [safe-point=438708652189155328]
[2023/01/14 00:34:55.959 +08:00] [INFO] [grpc_service.go:1353] ["update service GC safe point"] [service-id=gc_worker] [expire-at=9223372036854775807] [safepoint=4387088094
75293184]
[2023/01/14 00:36:38.860 +08:00] [INFO] [grpc_service.go:1287] ["updated gc safe point"] [safe-point=438708809475293184]
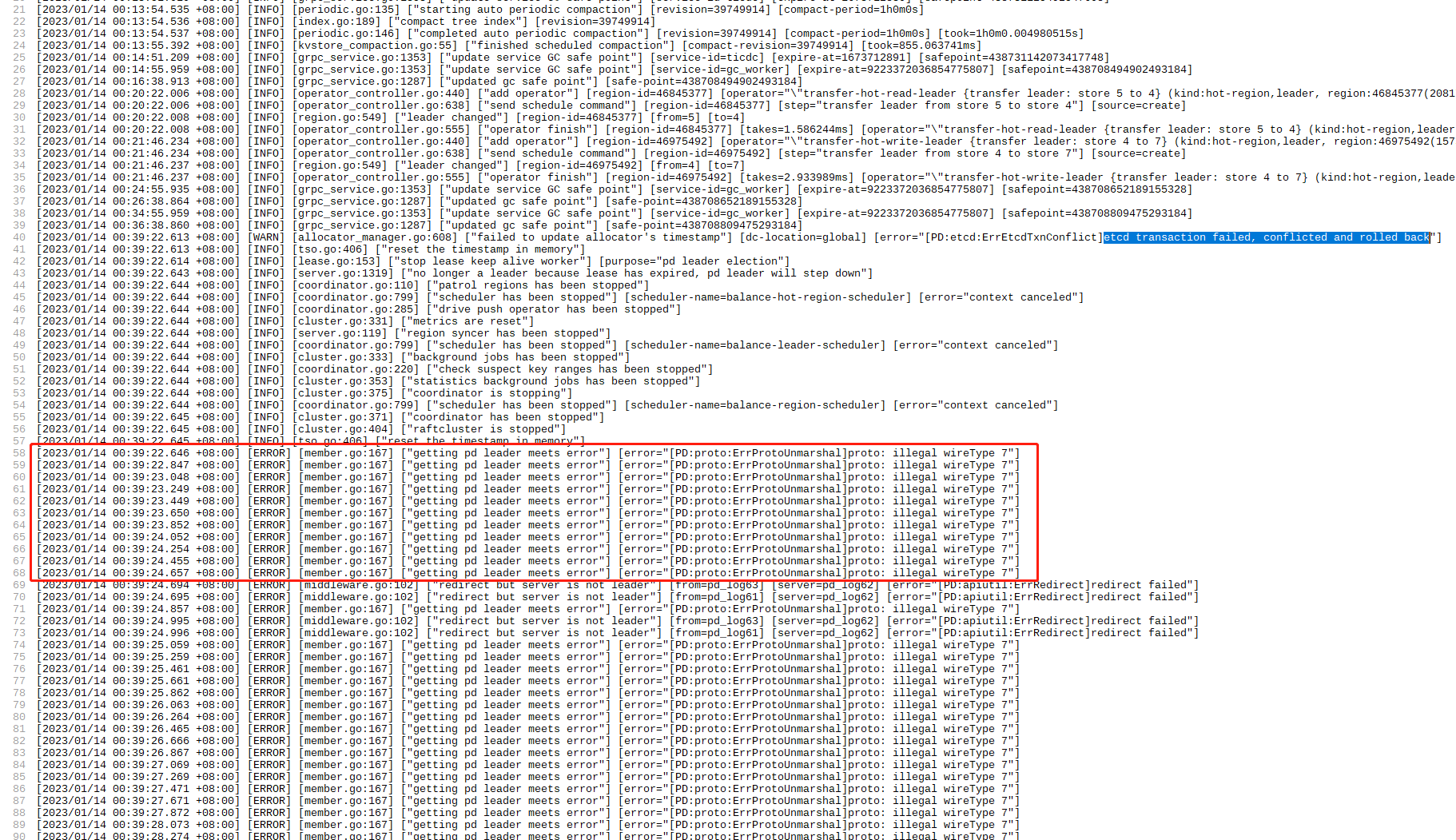
[2023/01/14 00:39:22.613 +08:00] [WARN] [allocator_manager.go:608] ["failed to update allocator's timestamp"] [dc-location=global] [error="[PD:etcd:ErrEtcdTxnConflict]etcd
transaction failed, conflicted and rolled back"]
[2023/01/14 00:39:22.613 +08:00] [INFO] [tso.go:406] ["reset the timestamp in memory"]
[2023/01/14 00:39:22.614 +08:00] [INFO] [lease.go:153] ["stop lease keep alive worker"] [purpose="pd leader election"]
[2023/01/14 00:39:22.643 +08:00] [INFO] [server.go:1319] ["no longer a leader because lease has expired, pd leader will step down"]
[2023/01/14 00:39:22.644 +08:00] [INFO] [coordinator.go:110] ["patrol regions has been stopped"]
[2023/01/14 00:39:22.644 +08:00] [INFO] [coordinator.go:799] ["scheduler has been stopped"] [scheduler-name=balance-hot-region-scheduler] [error="context canceled"]
[2023/01/14 00:39:22.644 +08:00] [INFO] [coordinator.go:285] ["drive push operator has been stopped"]
[2023/01/14 00:39:22.644 +08:00] [INFO] [cluster.go:331] ["metrics are reset"]
[2023/01/14 00:39:22.644 +08:00] [INFO] [server.go:119] ["region syncer has been stopped"]
[2023/01/14 00:39:22.644 +08:00] [INFO] [coordinator.go:799] ["scheduler has been stopped"] [scheduler-name=balance-leader-scheduler] [error="context canceled"]
[2023/01/14 00:39:22.644 +08:00] [INFO] [cluster.go:333] ["background jobs has been stopped"]
[2023/01/14 00:39:22.644 +08:00] [INFO] [coordinator.go:220] ["check suspect key ranges has been stopped"]
[2023/01/14 00:39:22.644 +08:00] [INFO] [cluster.go:353] ["statistics background jobs has been stopped"]
[2023/01/14 00:39:22.644 +08:00] [INFO] [cluster.go:375] ["coordinator is stopping"]
[2023/01/14 00:39:22.644 +08:00] [INFO] [coordinator.go:799] ["scheduler has been stopped"] [scheduler-name=balance-region-scheduler] [error="context canceled"]
[2023/01/14 00:39:22.645 +08:00] [INFO] [cluster.go:371] ["coordinator has been stopped"]
[2023/01/14 00:39:22.645 +08:00] [INFO] [cluster.go:404] ["raftcluster is stopped"]
[2023/01/14 00:39:22.645 +08:00] [INFO] [tso.go:406] ["reset the timestamp in memory"]
[2023/01/14 00:39:22.646 +08:00] [ERROR] [member.go:167] ["getting pd leader meets error"] [error="[PD:proto:ErrProtoUnmarshal]proto: illegal wireType 7"]
[2023/01/14 00:39:22.847 +08:00] [ERROR] [member.go:167] ["getting pd leader meets error"] [error="[PD:proto:ErrProtoUnmarshal]proto: illegal wireType 7"]
[2023/01/14 00:39:23.048 +08:00] [ERROR] [member.go:167] ["getting pd leader meets error"] [error="[PD:proto:ErrProtoUnmarshal]proto: illegal wireType 7"]
[2023/01/14 00:39:23.249 +08:00] [ERROR] [member.go:167] ["getting pd leader meets error"] [error="[PD:proto:ErrProtoUnmarshal]proto: illegal wireType 7"]
[2023/01/14 00:39:23.449 +08:00] [ERROR] [member.go:167] ["getting pd leader meets error"] [error="[PD:proto:ErrProtoUnmarshal]proto: illegal wireType 7"]
从提交的日志看来是 PD 的集群完全断连了,基本上就可以确认为 分布式无效了…
然后排查的话,应该有几个方向:
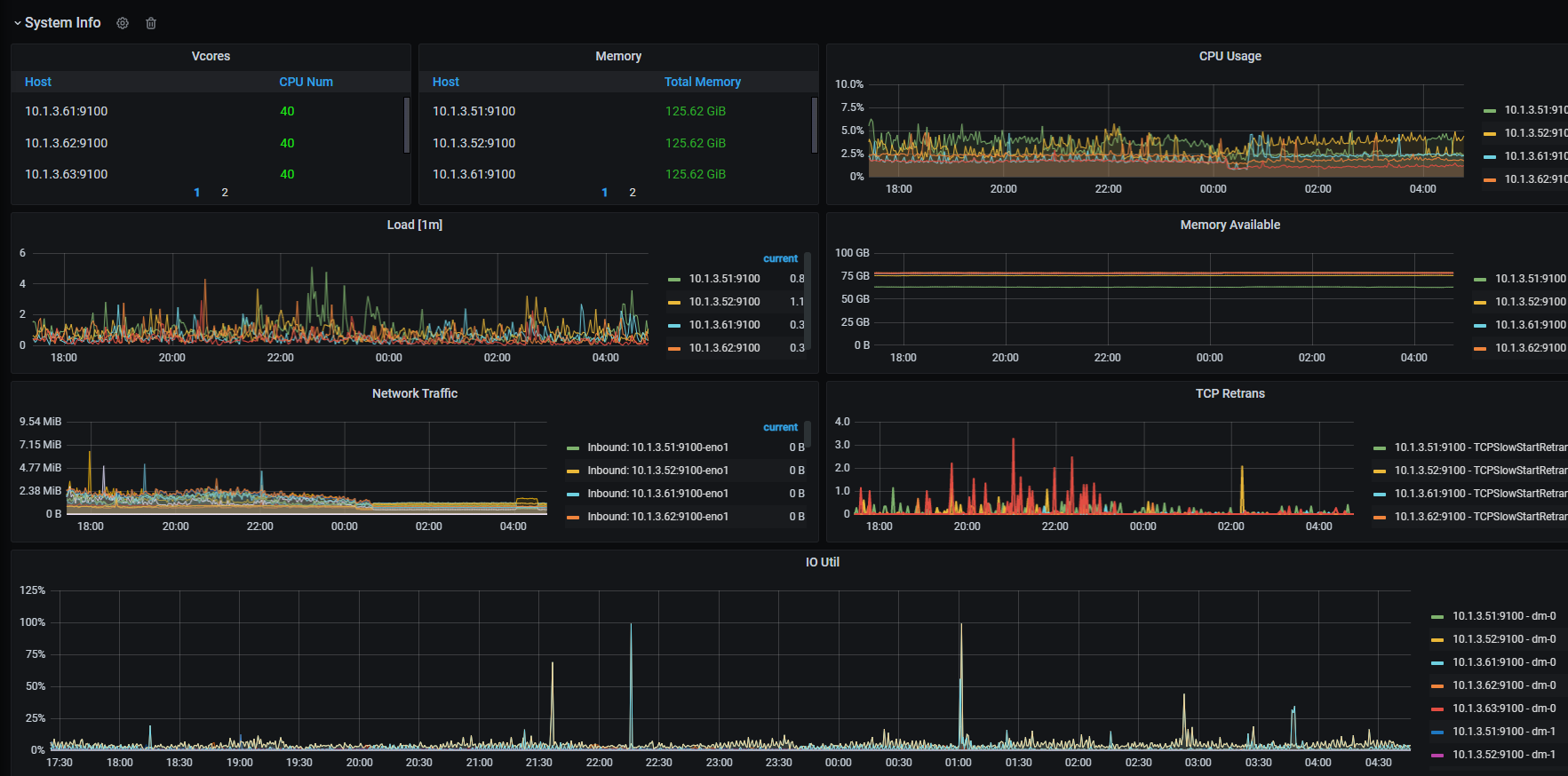
资源的IO 瓶颈,比如 cpu,内存,磁盘 (图中已经描述了cpu 和内存无瓶颈,可以查下磁盘的 IO)
网络瓶颈 (群集配置已经有描述,但是集群节点之间给的网络带宽是多少?)
节点之间网络的延迟 (通过 ganafa 观测 PD 节点的 gRPC 相关的网络信息)
我会优先考虑网络断连了…
参考提供的日志,从 39分开始起 就无 leader了…
[2023/01/14 00:39:24.694 +08:00] [ERROR] [middleware.go:102]
["redirect but server is not leader"]
[from=pd_log63] [server=pd_log62]
[error="[PD:apiutil:ErrRedirect]redirect failed"]
[2023/01/14 00:39:24.695 +08:00] [ERROR] [middleware.go:102]
["redirect but server is not leader"]
[from=pd_log61] [server=pd_log62]
[error="[PD:apiutil:ErrRedirect]redirect failed"]
以上可以清楚的看到 所有的 PD 完全断链了…
另外请考虑 ETCD 的默认配置:
etcd 默认超时时间是 7 秒(5 秒磁盘 IO 延时 +2*1 秒竞选超时
时间),如果一个请求超时未返回结果,则可能会出现你熟悉的 etcdserver: request timed out 错误。
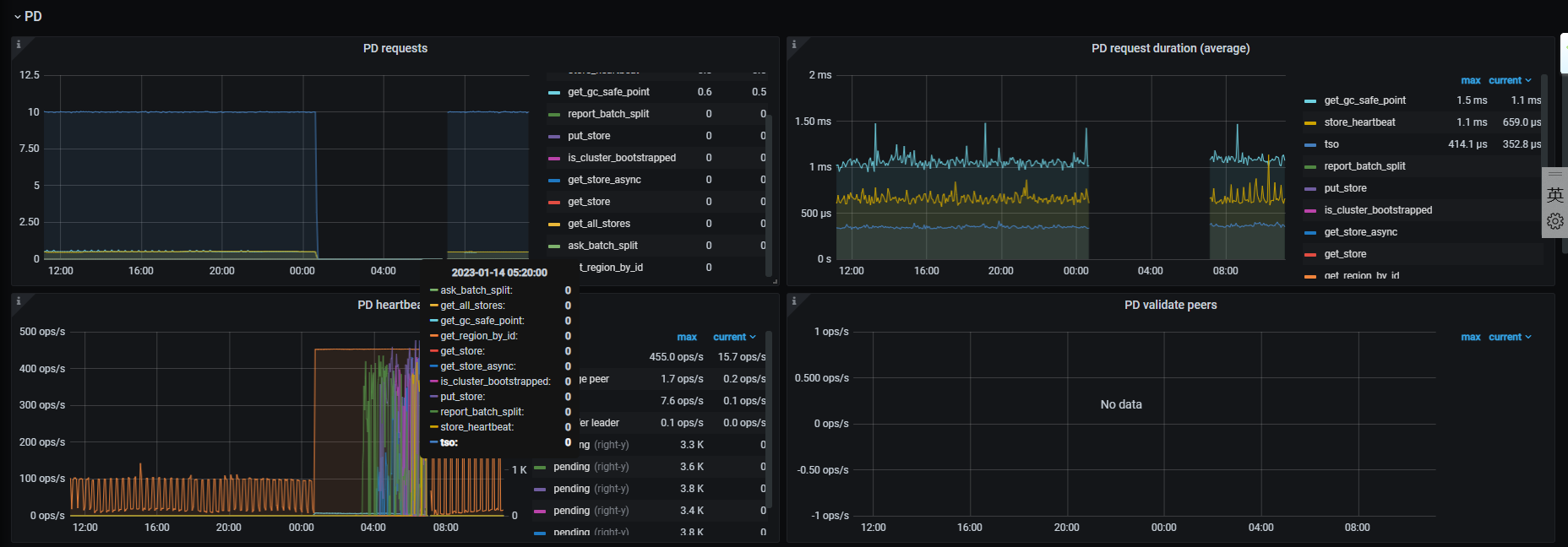
查看tso慢查询原因 表妹文章,也没有说的Tso慢请求,有的只是无法连接pd,导致请求数陡降为0。
另外确认这个时期,网络确实没有问题,只是0:15的时候Tcp连接数降了(ticdc先行挂掉了?)
但是从tidb pd 的请求上看,一直到0:39,都是有在处理tso请求的。
没大脑的支持,其他的组件可能都会出毛病了 ![]()
这个和最后的结果是一致的…
ticdc 也需要 PD 来支持的,比如版本信息记录,TSO的生产…