gejibin
(Gejibin)
1
【 TiDB 版本】v5.4.0
从TiDB备份恢复到新建的TiDB实例时,tikv恢复完后(tiflash没有同步完,仍然在同步数据中),业务开始进行写入操作(通过engine设置关闭了tiflash的查询操作),tiflash继续同步,TiFlash 同步到1.4T左右(数据没有同步完)时,有2个tiflash节点频繁发生OOM重启,每运行4分钟左右就OOM。设置如下参数不起作用,还是不断OOM:
cop_pool_size
batch_cop_pool_size
max_memory_usage
max_memory_usage_for_all_queries
tiflash-log.zip (4.0 MB)
Aric
(Jansu Dev)
2
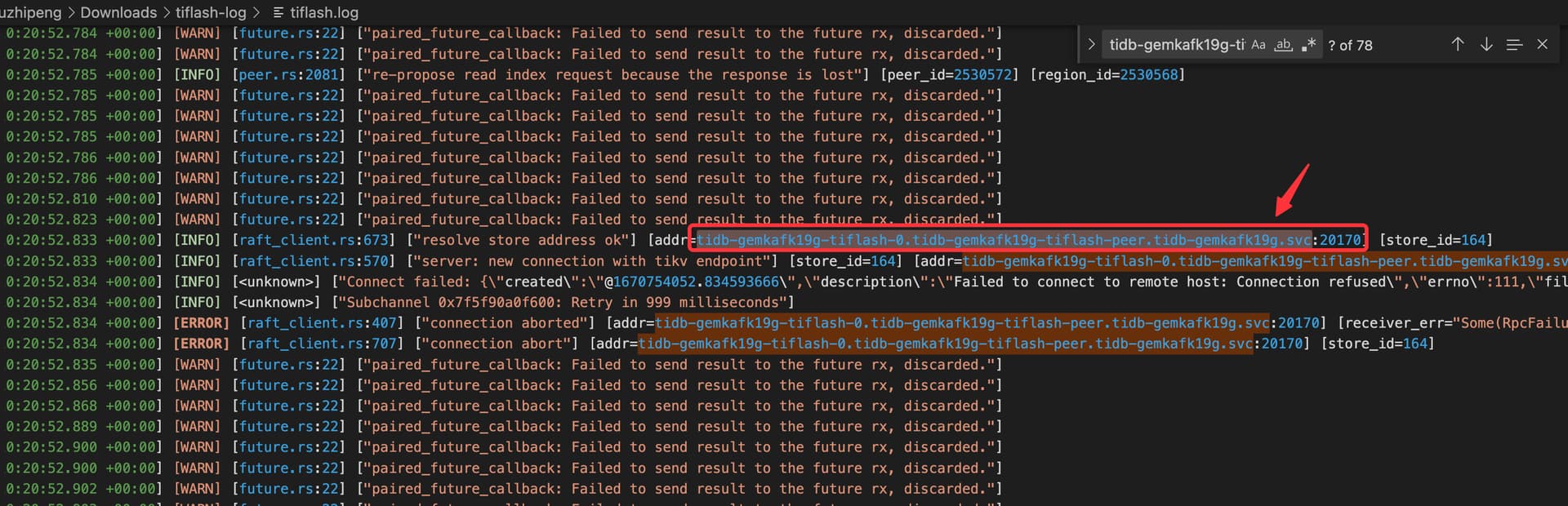
目前从日志能看出,tidb-gemkafk19g-tiflash-0.tidb-gemkafk19g-tiflash-peer.tidb-gemkafk19g.svc 总是连接不上,然后 channel 中会积压 raft 信息,导致不断打日志。 得查下为什么连接不上。
flow-PingCAP 方便看看吗?
@flow-PingCAP
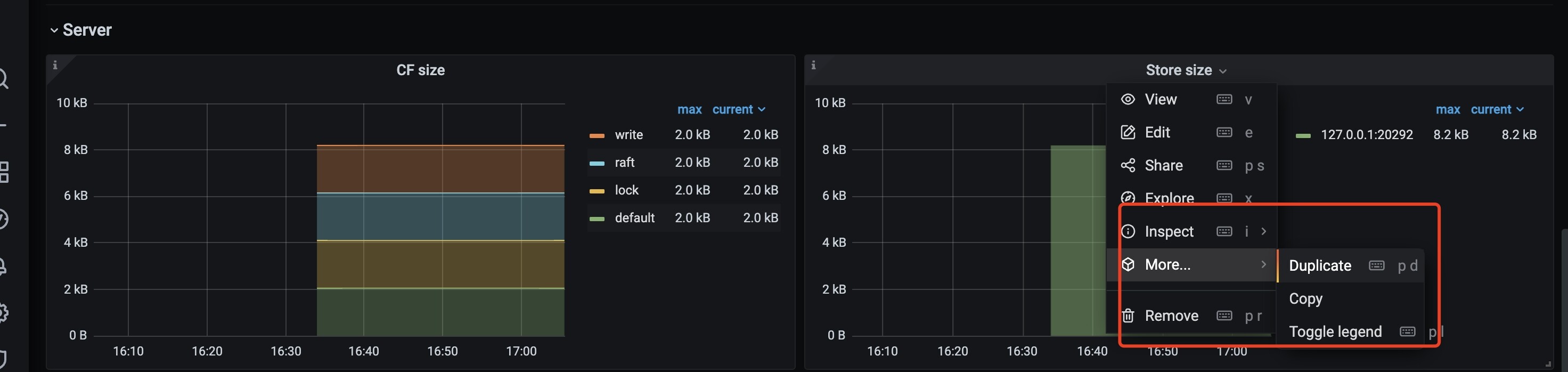
看一下 grafana 监控,贴一下下面两个指标。或者上传一份 clinic 信息吧: https://docs.pingcap.com/zh/tidb/dev/quick-start-with-clinic
-
TiFlash-Proxy-Details / Server / Store size 上涨
-
raftstore-entry-cache 内存使用上涨。需要手动在 Grafana 的 TiFlash-Proxy-Details 监控中添加一个监控项:
Metrics:
tiflash_proxy_tikv_server_mem_trace_sum{k8s_cluster=“$k8s_cluster”, tidb_cluster=“$tidb_cluster”, instance=~“$instance”, name=~“raftstore-.*”}
Legend:
{{instance}}-{{name}}
查了一下相关记录,常见的导致重启 OOM 的问题,在 5.4.3 之后被修复,可以尝试单独升级一下 TiFlash 版本。
https://github.com/pingcap/tiflash/issues/4728#issuecomment-1258948453
一般来说小版本都是 bugfix 版本,所以单独升级 TiFlash 问题不大。不过为了安全起见,确认可以解决问题之后,建议整体升级一下 TiDB 到 5.4.3
system
(system)
关闭
6
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。