又仔细看了下,应该还是有 txnLockFast
-
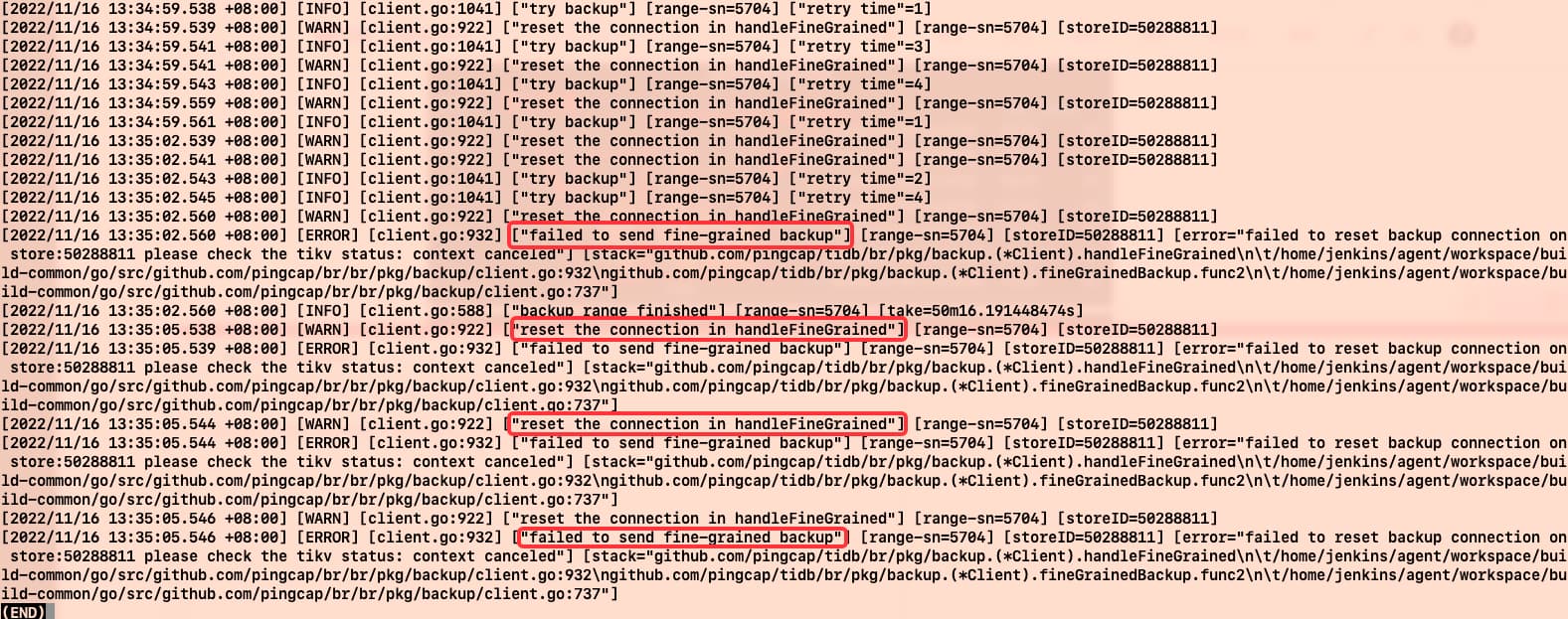
这 4 条 failed to send fine-grained backup 下面的 4 个 goroutine 报出来的,是备份崩溃的一个中间流程。
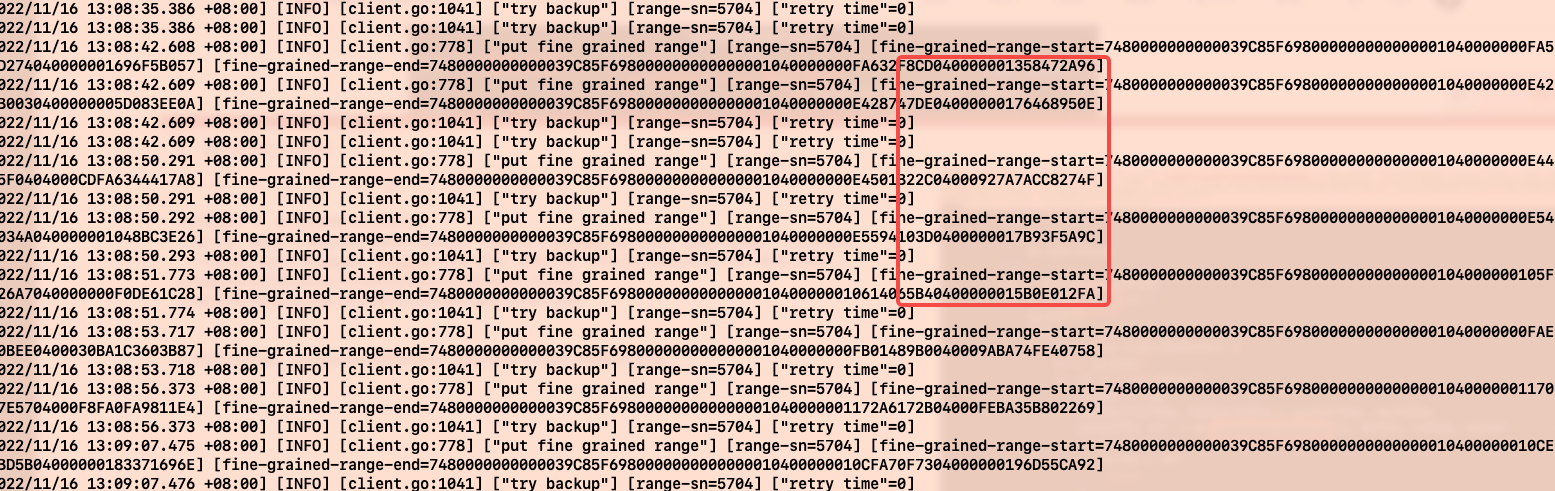
cat full_20221116.log|grep “range-sn=5704”|less 得到下图。5704 就代表第 5704 个表(包含 index …)
-
为什么会崩溃,fine-grained 是语句 tikv 的反馈 rangeTree 重拾请求,这第 5704 个 table 中剩余的 range。可以看到 range 一直在变。
-
看了下这个时间点附近没有网络问题,ping and tcp_retrans …,所以应该还是解锁超时。
然后这个重拾时间是写死的,想硬绕应该是没有办法。backupFineGrainedMaxBackoff = 80000 backupRetryTimes = 5 -
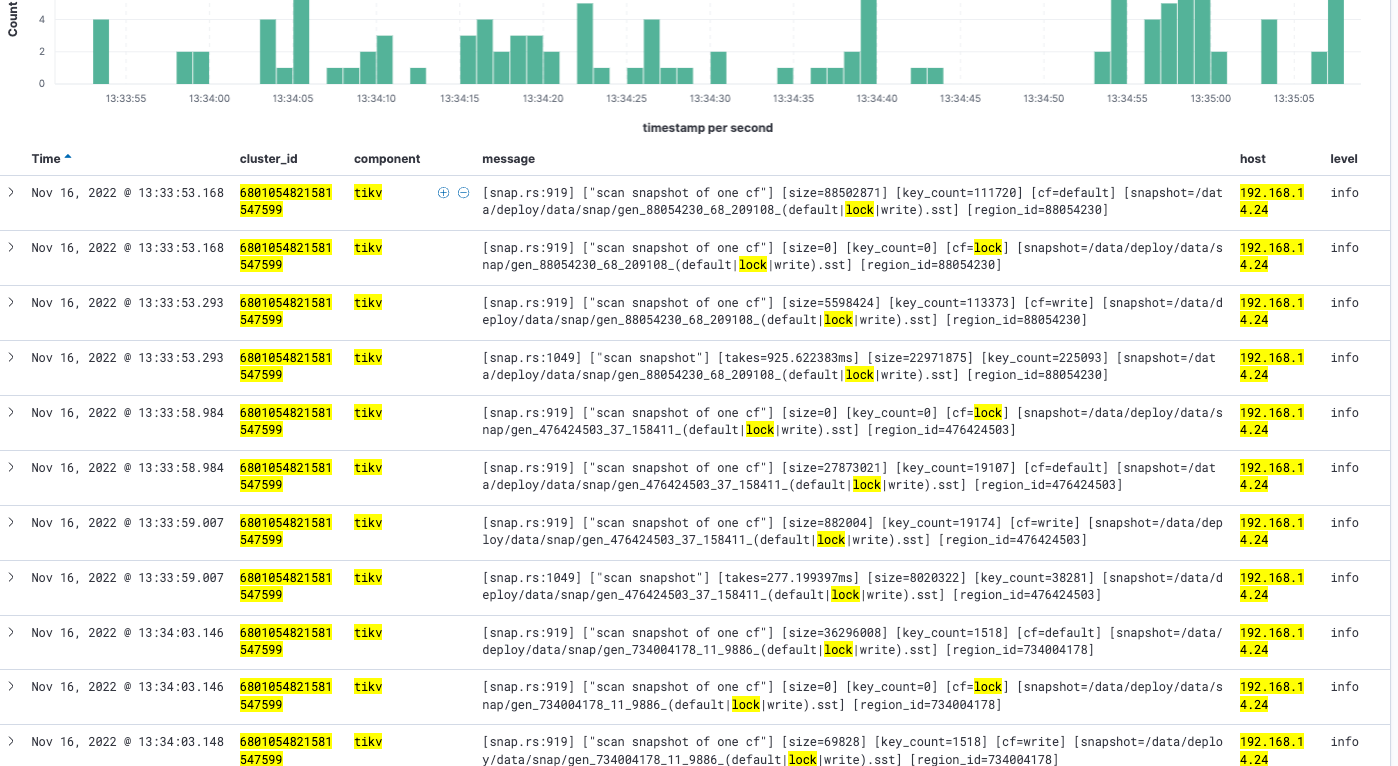
为什么在日志中搜不到,读写冲突的报错在 tikv 侧会不会暴出来,我不太确定🤔。在 tidb 侧会暴,但 BR 不请求 TiDB。
-
不过一个解决思路是,2022/11/16 13:35:05.546 前推 80s ,然后去 slow_log 中看下,然后直到 2022/11/16 13:35:05.546 还没有 commit 的 txn。并且那个 txn 中涉及的表又是 5704 这 range-sn 解出来的 table-name。 如果幸运,能找到,然下那是什么业务,然后错峰备份。