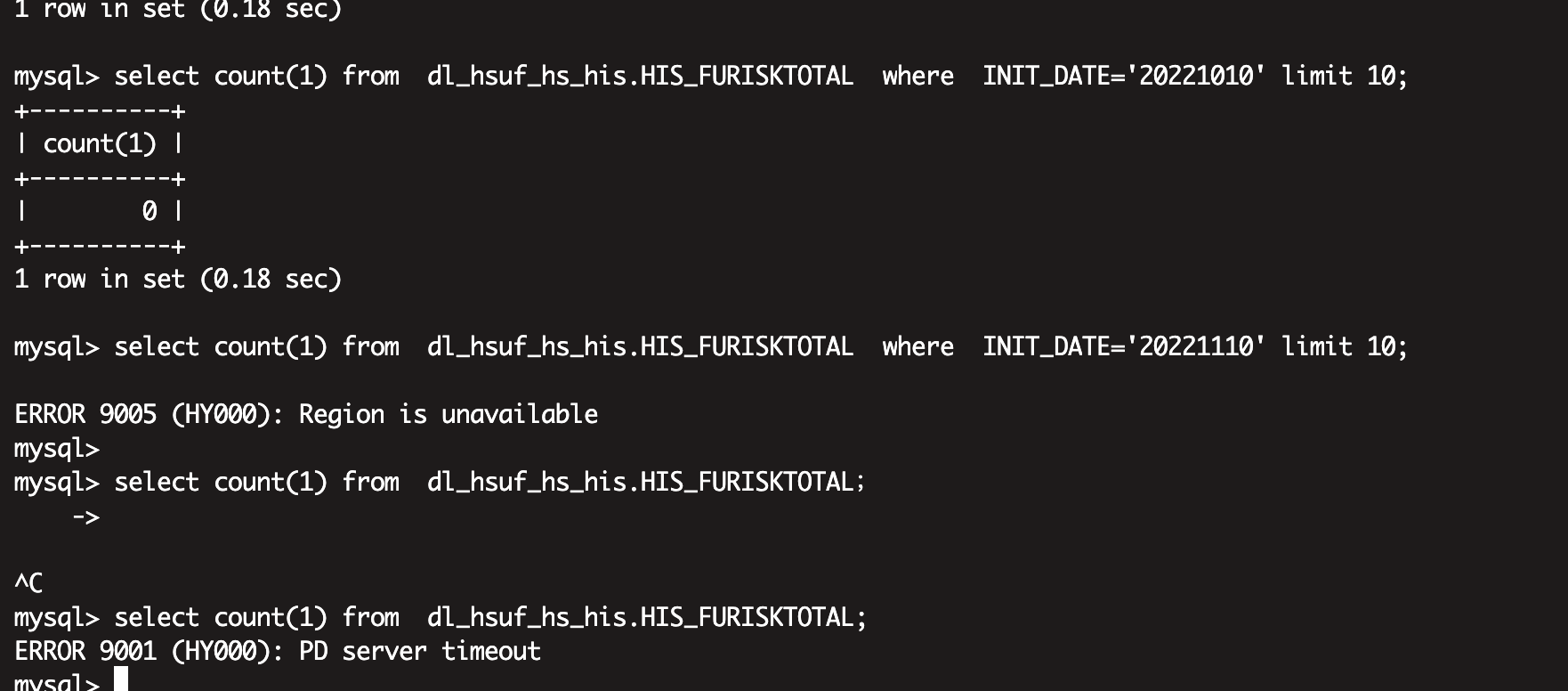
pd 原本是3副本,然后 10.130.1.3 这个节点openssh有问题 ,服务器重装 只能–force 强制删除 ,后面重装服务器后,扩容节点 和 pd-recover,就开始发现pd servers timeout,然后旧的pd 节点我也缩了再扩 也是有问题
drop table 过也是不行
我create table newTable like oldTable ,然后插入新的数据到 newTable 也会出现问题
你重建时 alloc-id 设置的是否有问题?
我那时候在日志查到 alloc-id 是8002 然后我就设置8002
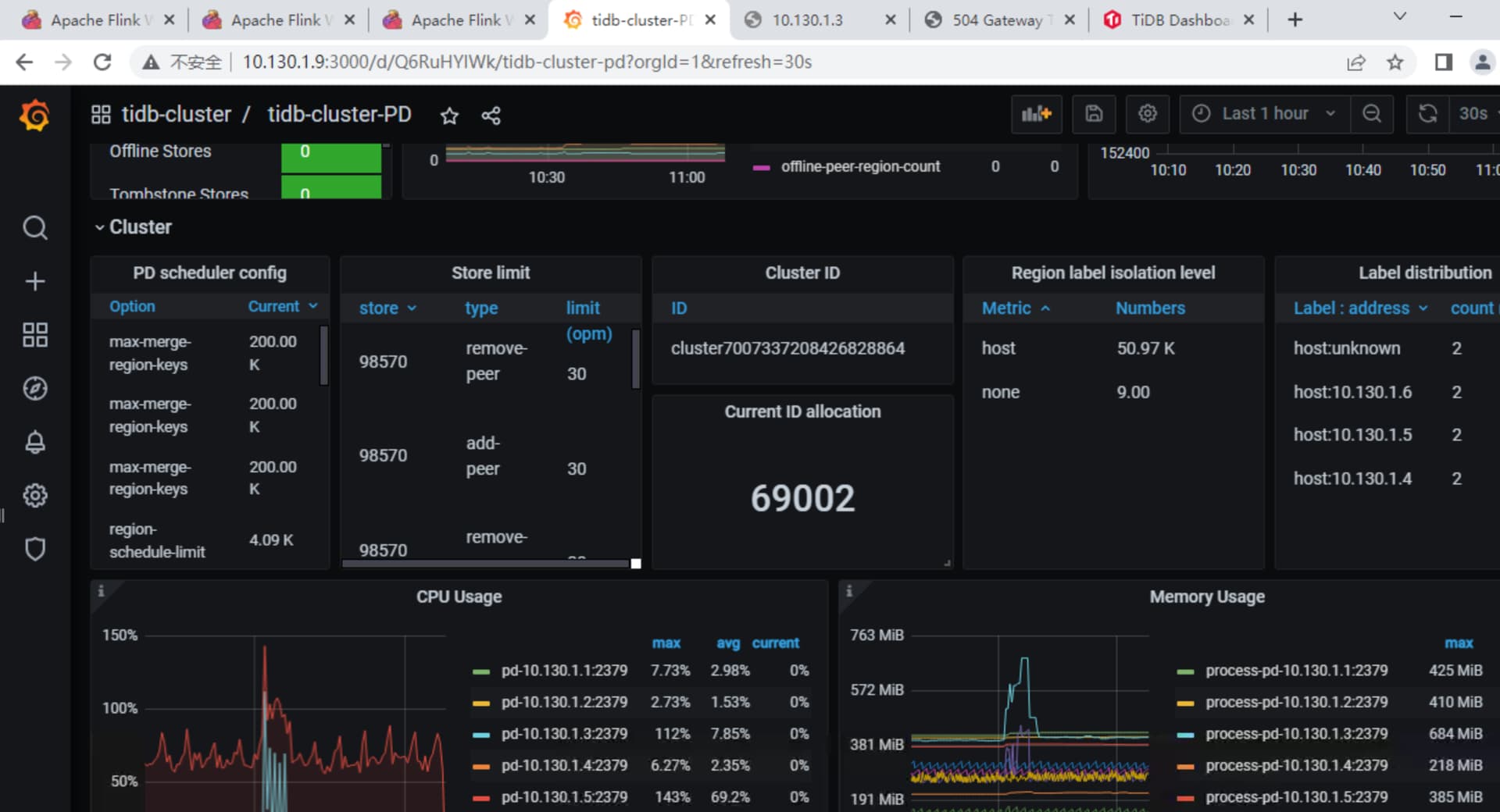
看下现在监控 pd Current ID allocation 是多少
或者查询之前的日志。每个都查一下。找最大的
按理。建新表 插入数据查询应该没问题的吧
alloc-id 是分配给table 或者index的id. 如果你重建的时候设置的不对,肯定又问题
按理是这样 是不是不能用 create table xxx like xx 建?
你可以尝试新建一张表 insert into 回去。
我试试手动建一张表看看
把tikv的日志发一下
昨天的可以吗 ,还是要现在的
scale-in --force吗, 你试试把这个再次scale-in了 不要–force
所有节点重新处理一次吗
刚才的
试过 不行
看你描述整个过程是用的scale in/out来处理的所有的pd是吧?只有1.3是force的,只缩这个试试,