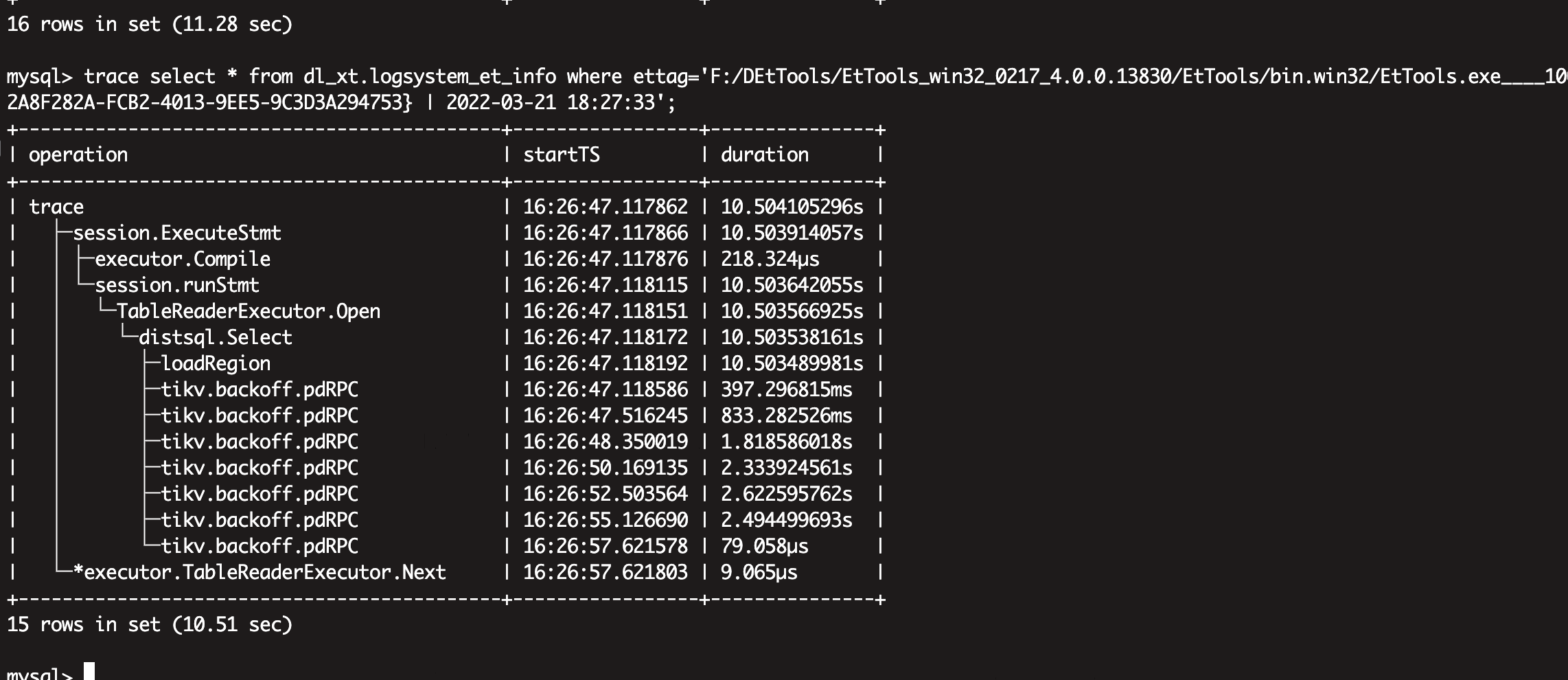
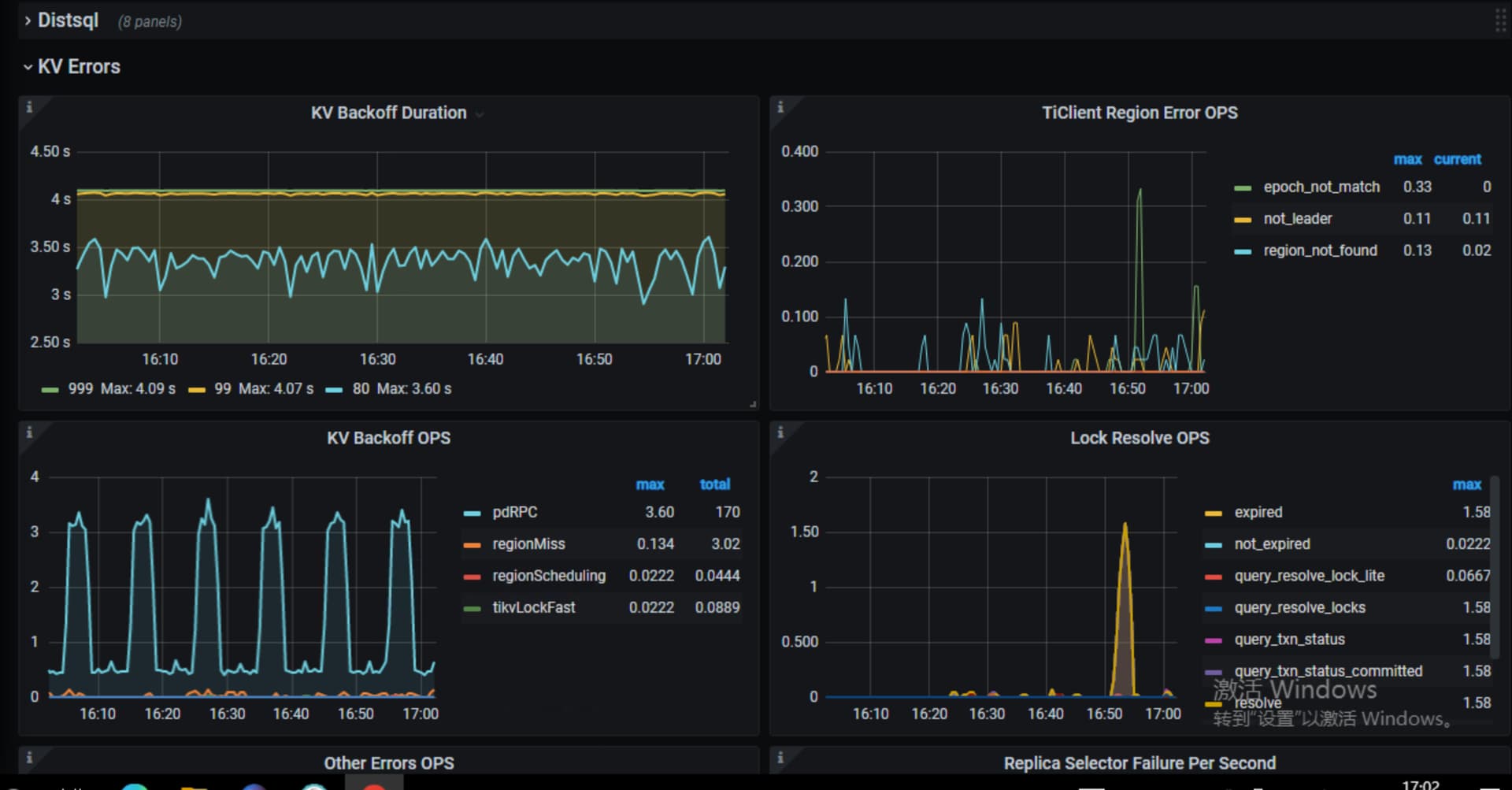
上面我截图 里面 tikv.backoff.pdRPC 延迟很高 这个有啥处理方法没有
貌似tikv和pd的通信问题,看看tikv压力大吗
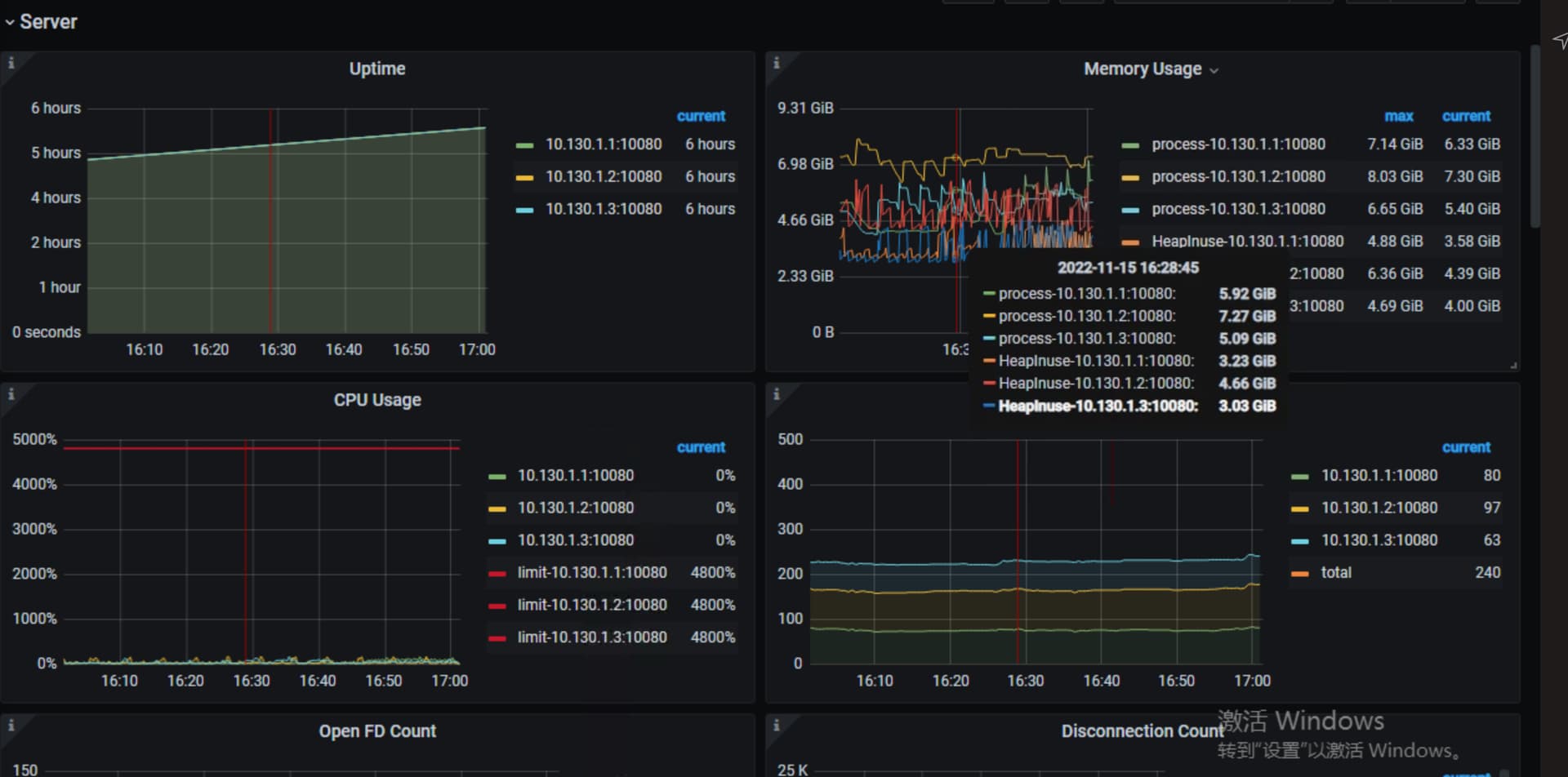
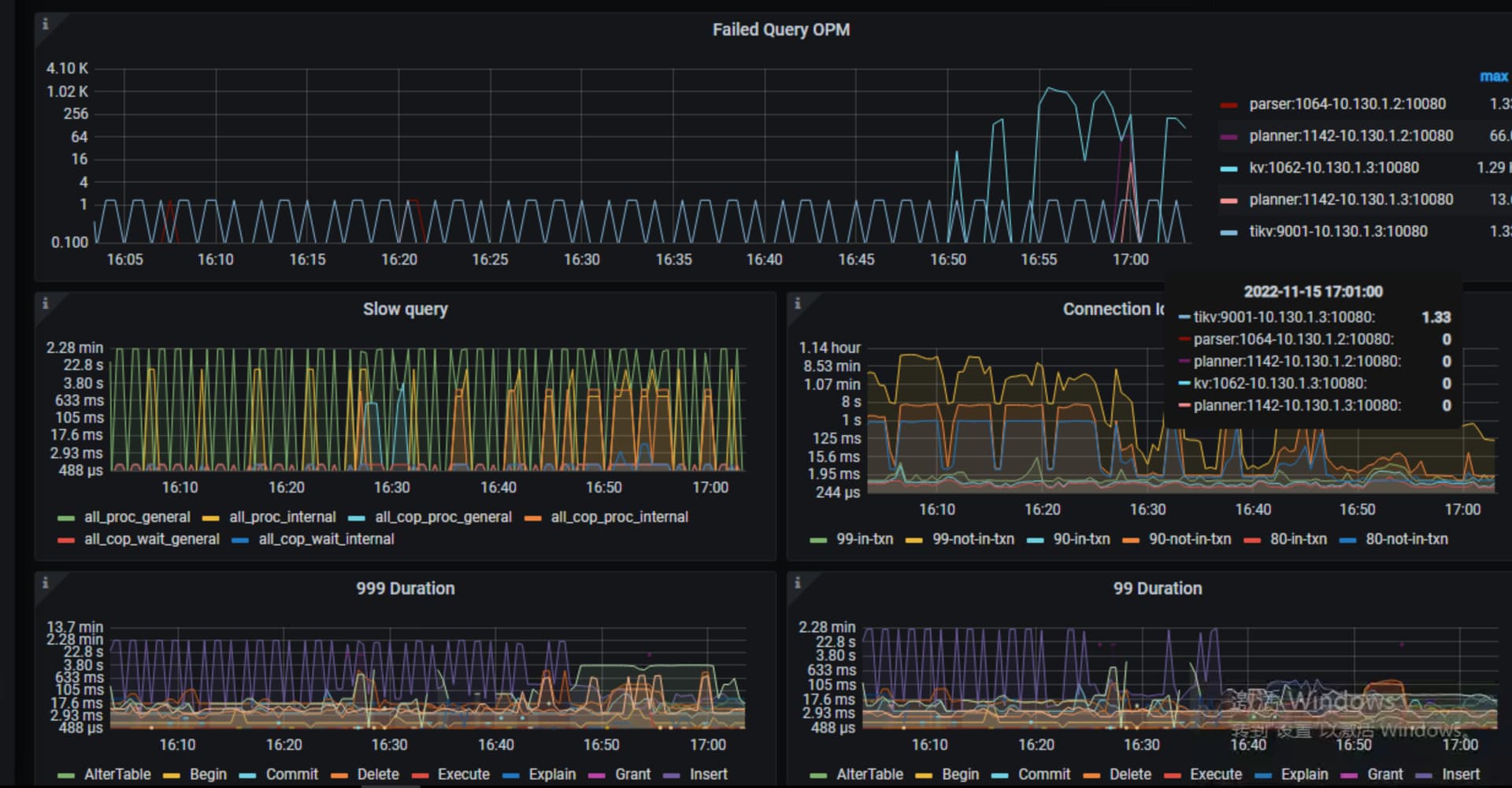
看下tikv-detail 那个监控页面 先主要看下thread cpu ,flow control ,raft propose,rockdb kv。另外看下exporter监控中tikv的情况
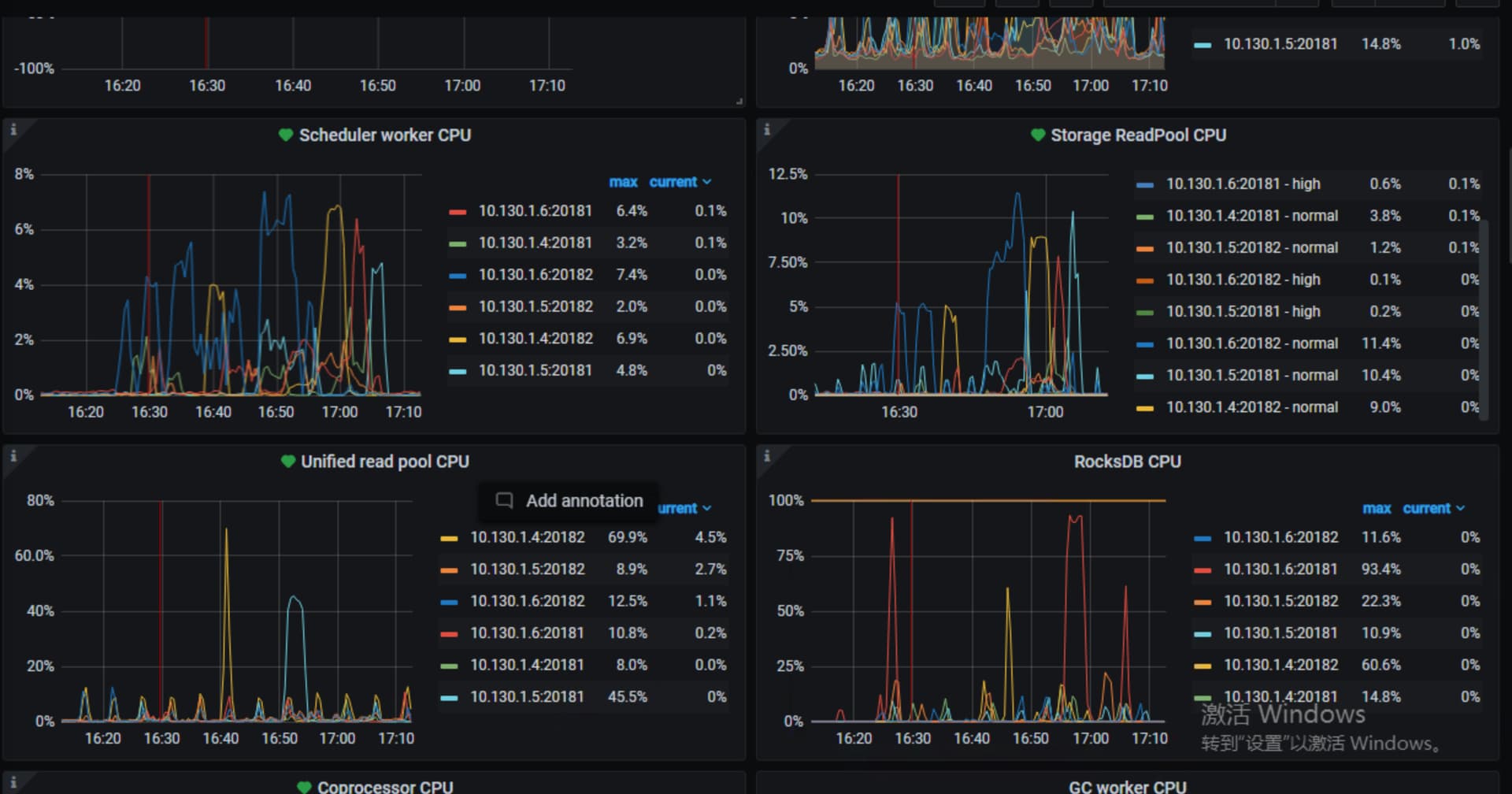
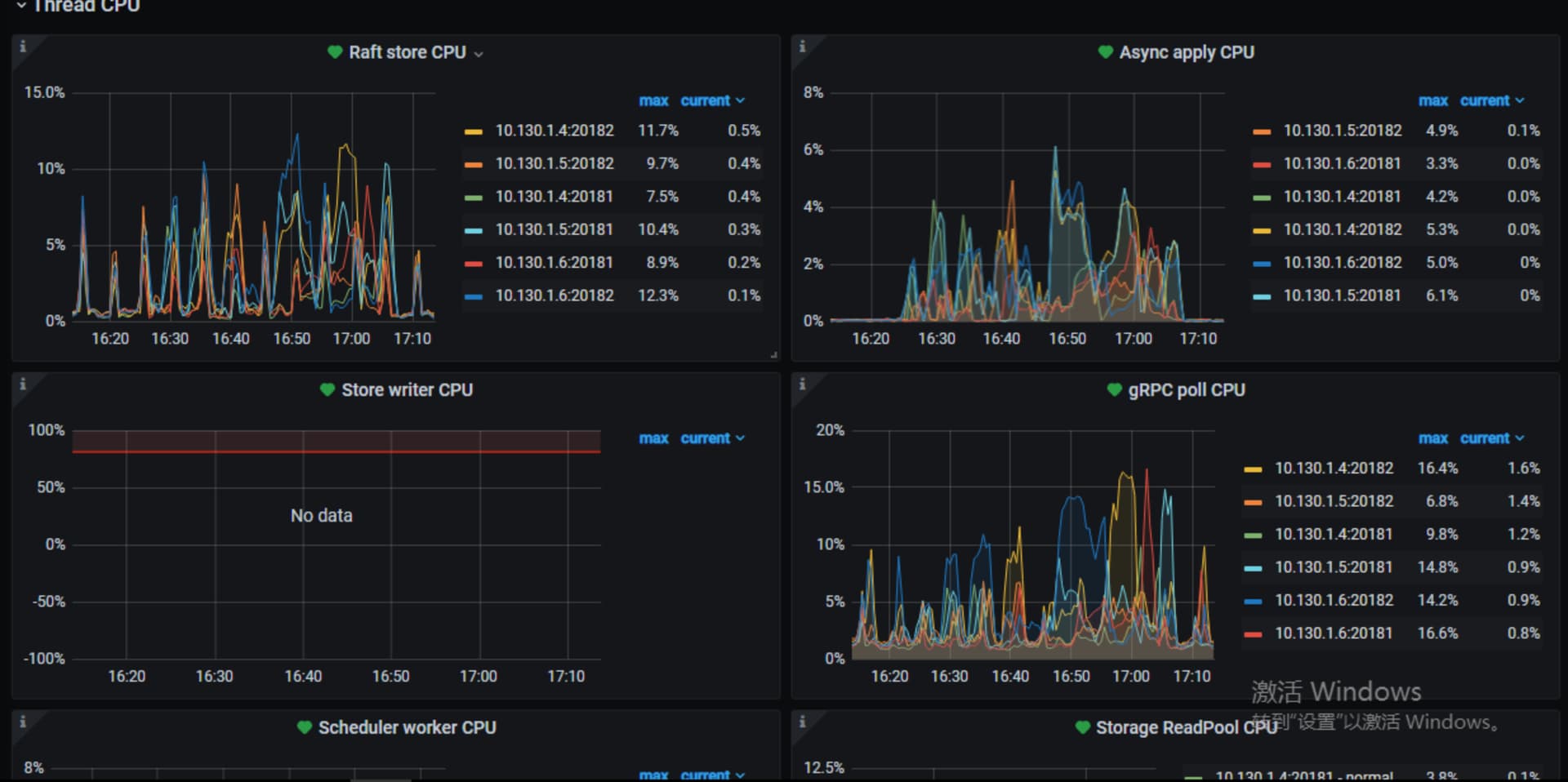
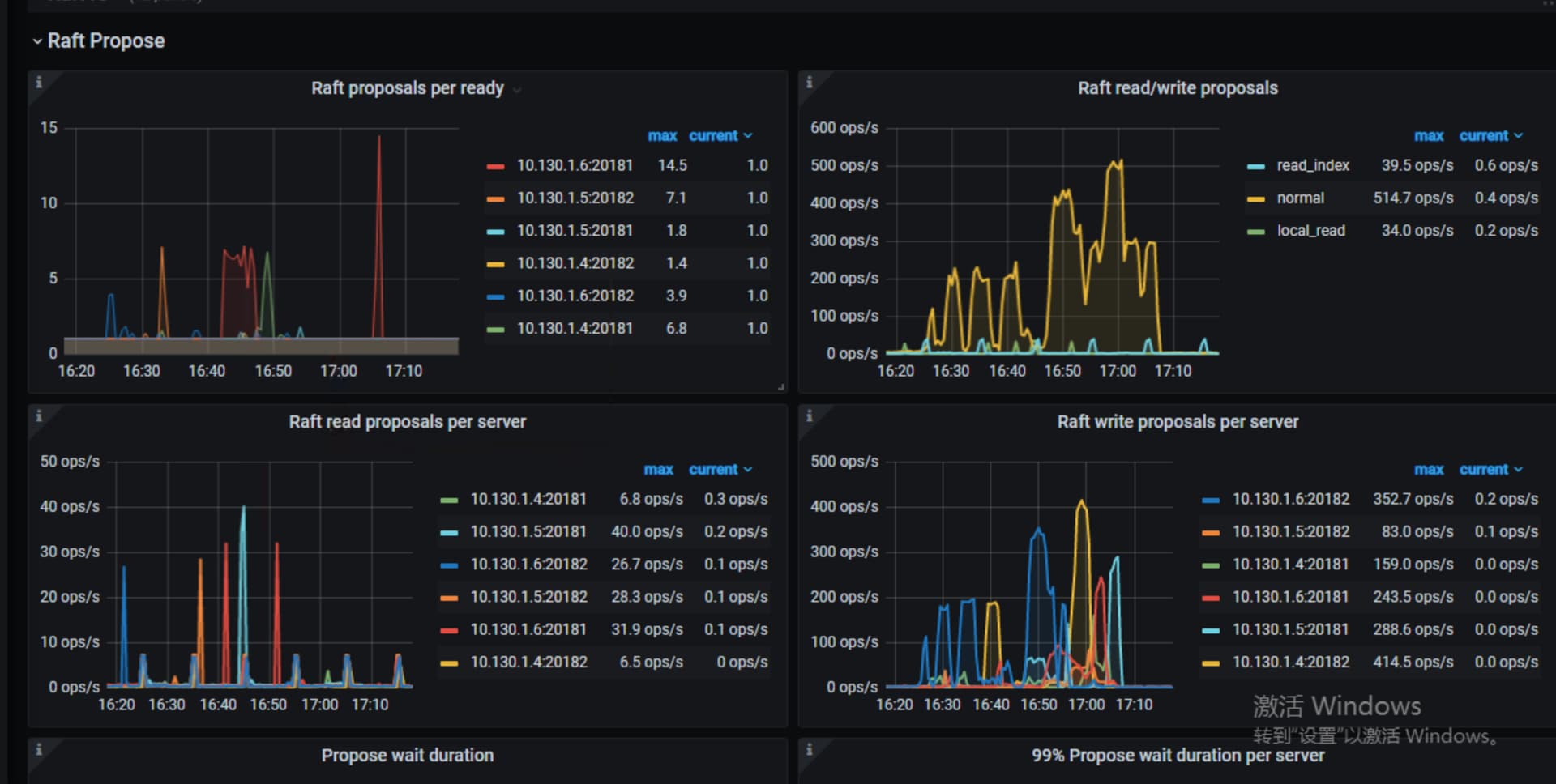
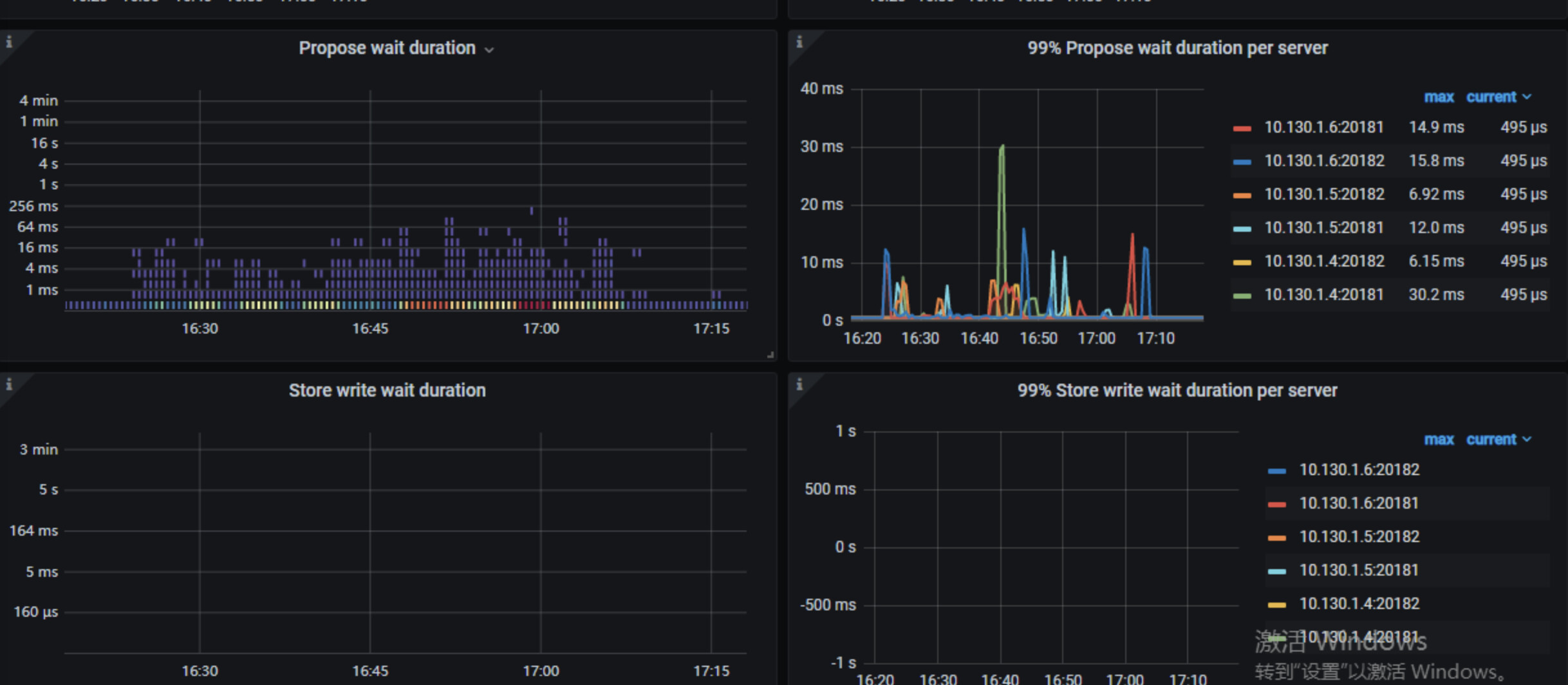
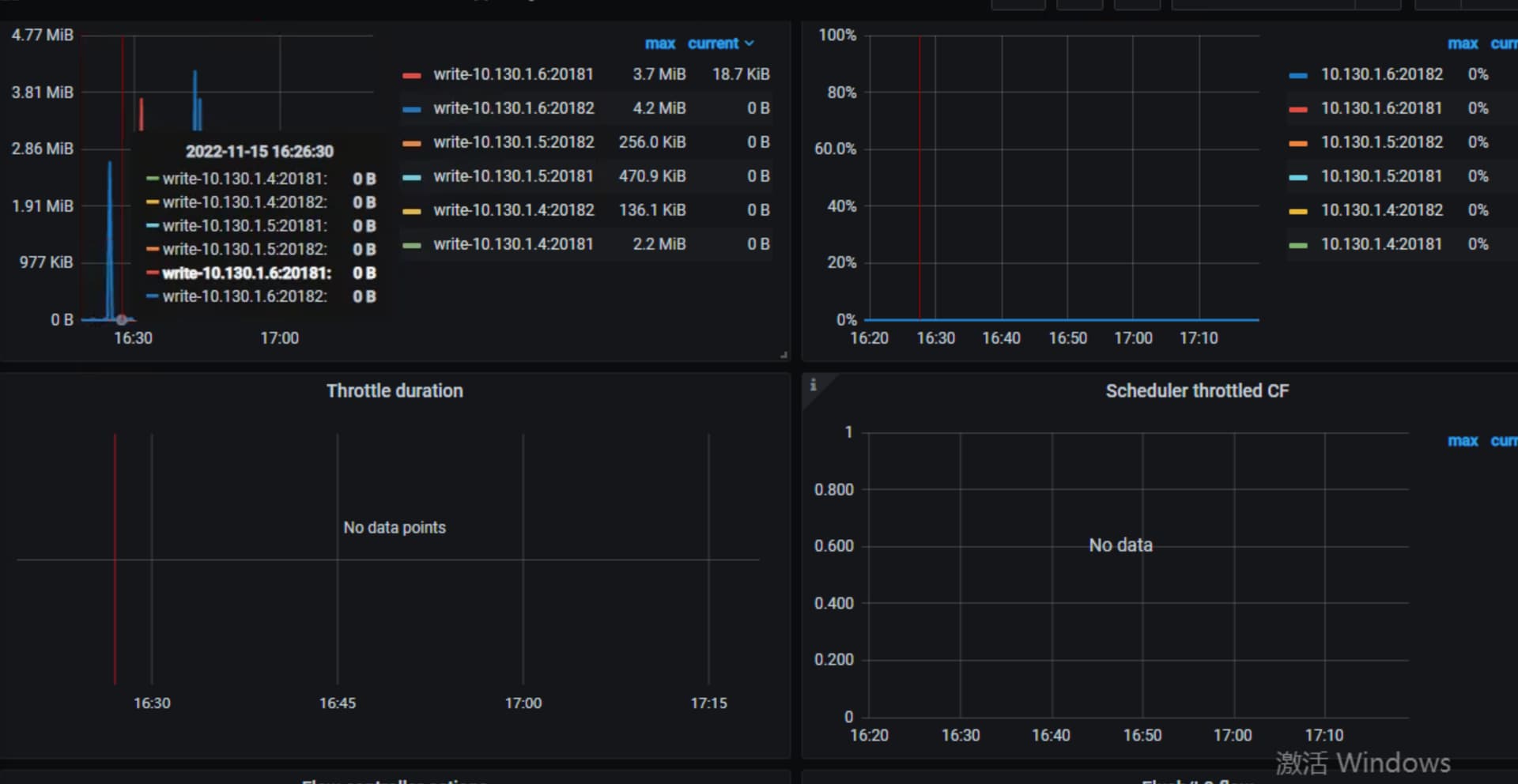
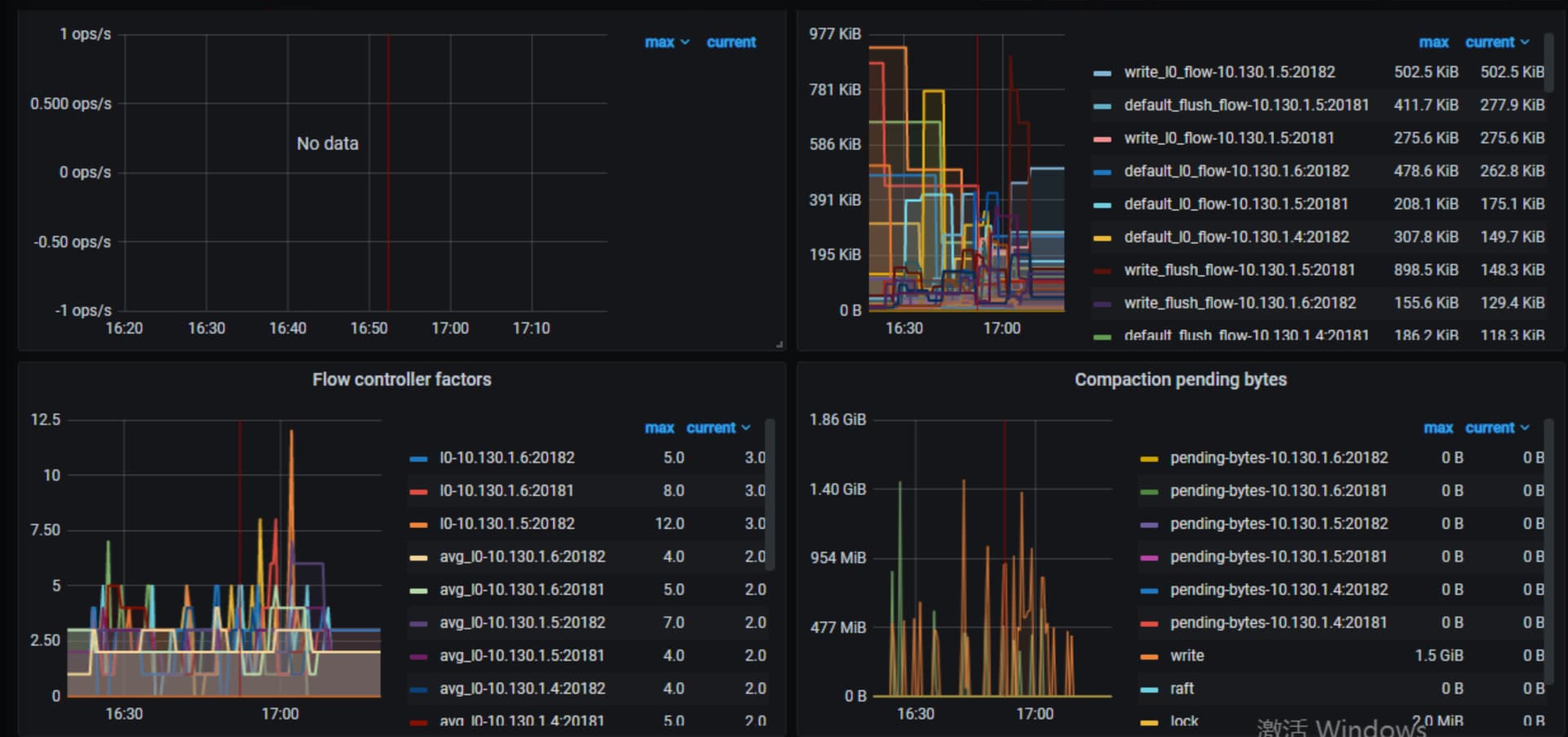
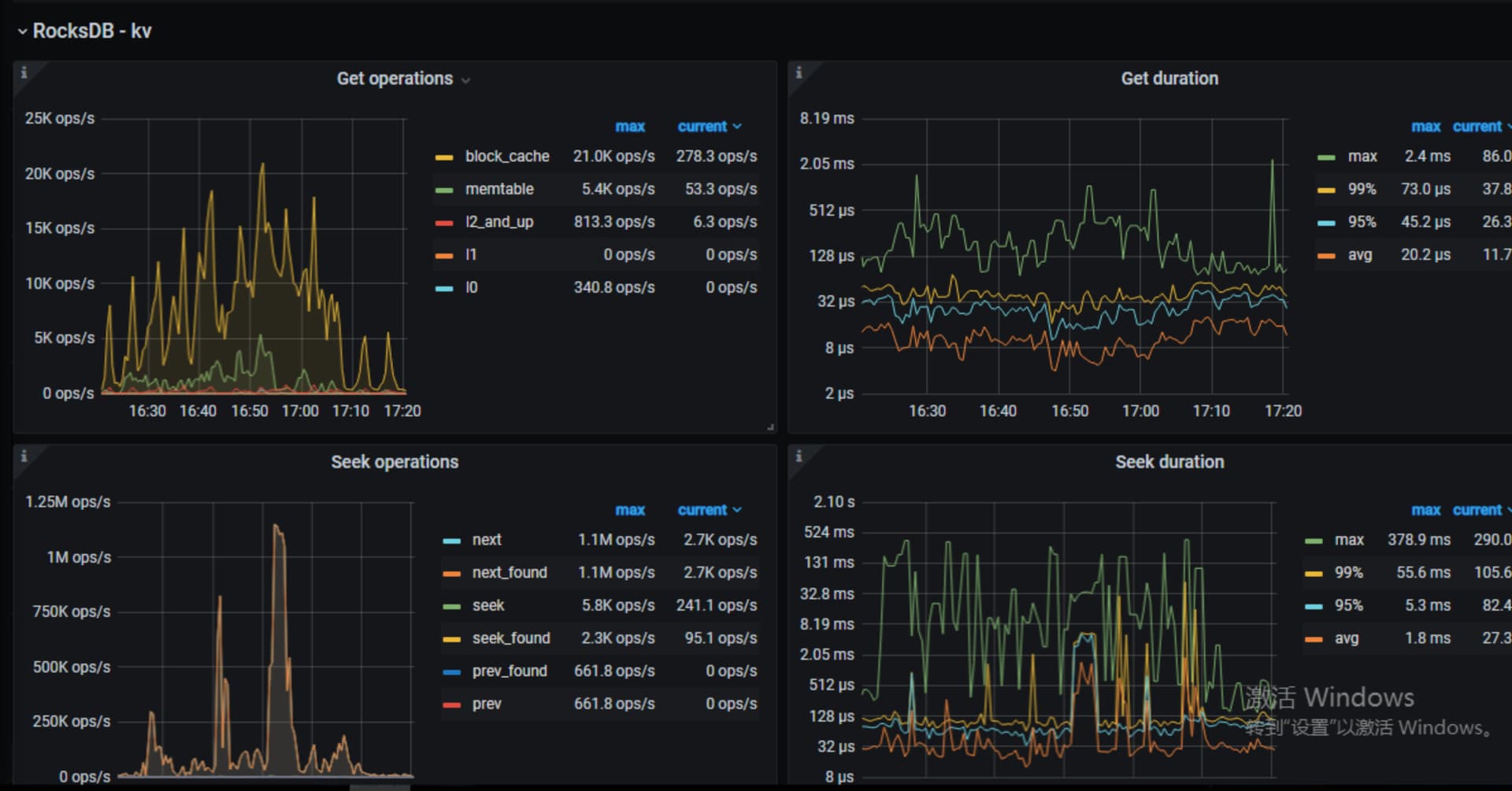
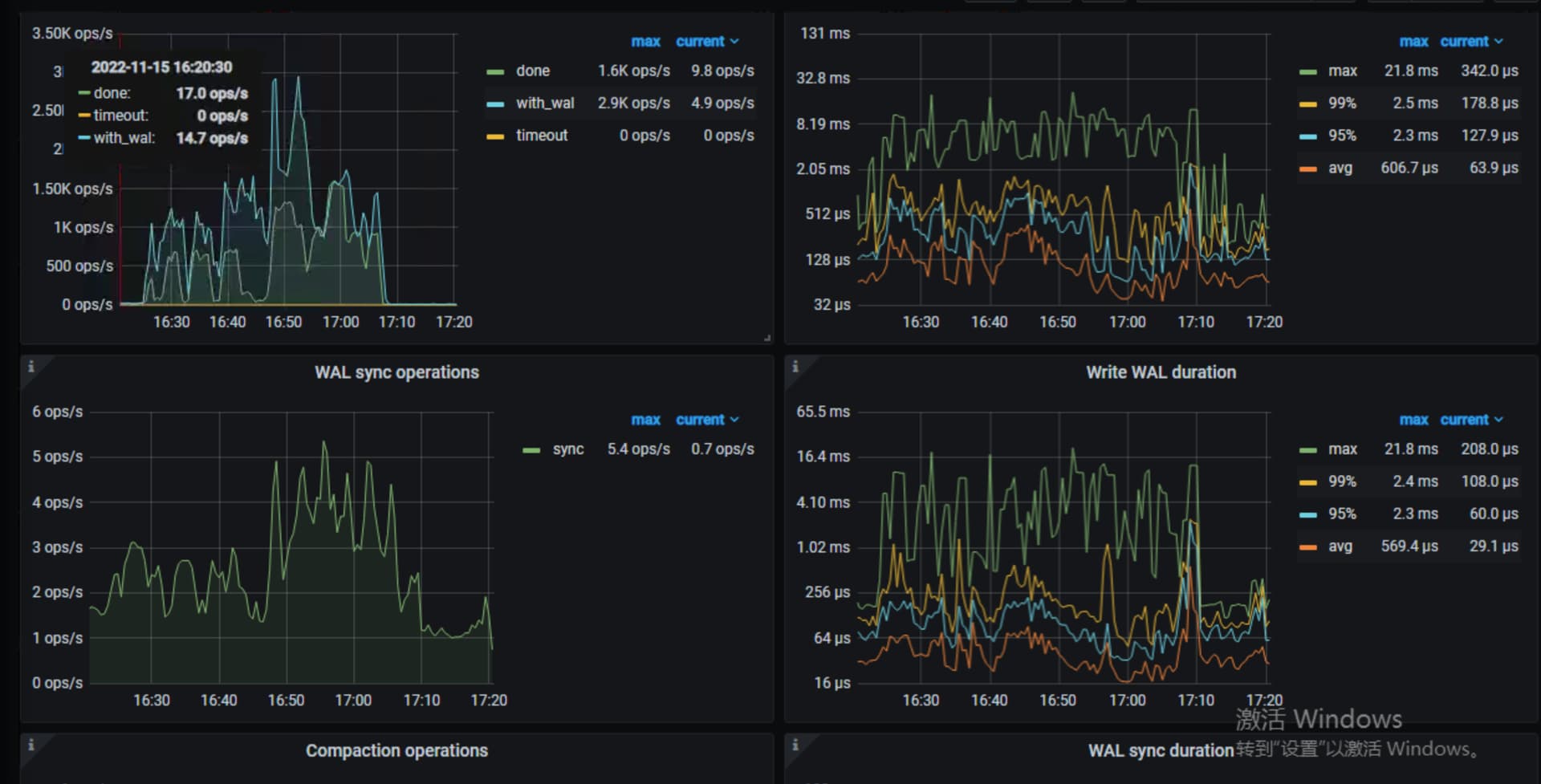

上面这些看着都没问题,tikv到pd的网络情况呢
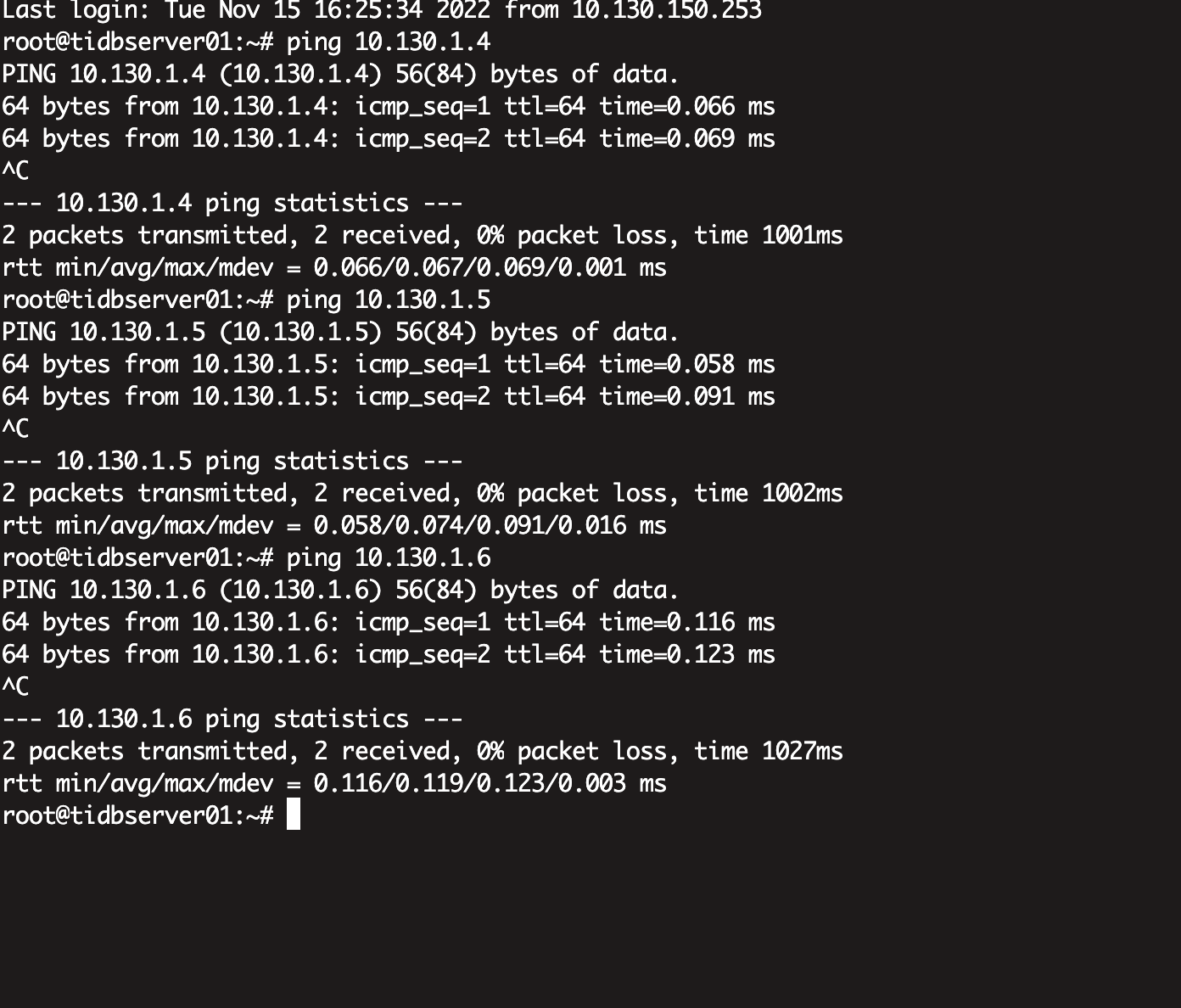
之前pd 集群重搭后就出现这样的报错 ,但是一直想不出来哪里出现问题 region?
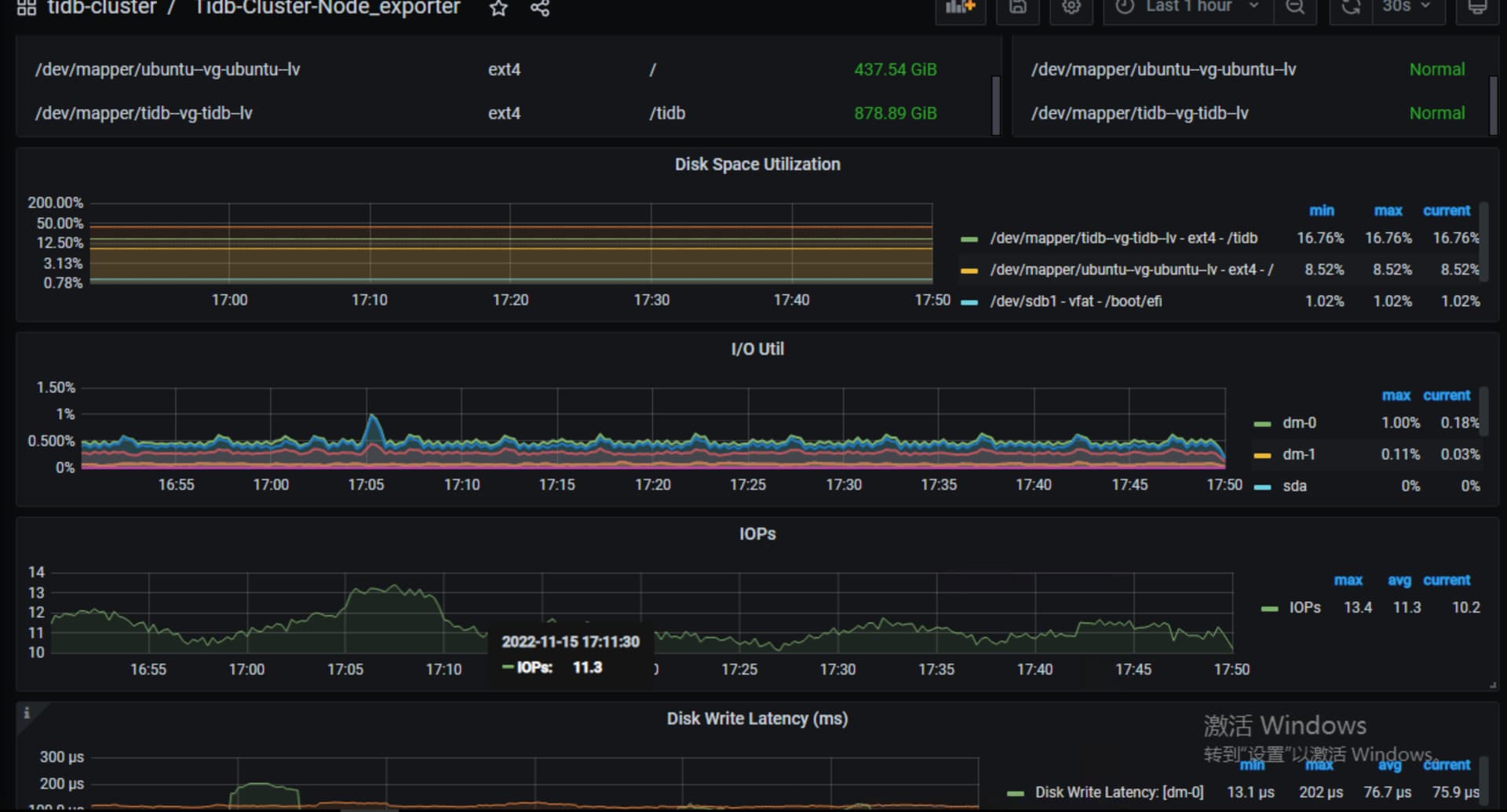
前面node exporter 中pd leader datadir的磁盘性能怎么样
[2022/11/15 08:16:12.103 +08:00] [WARN] [cluster_util.go:315] [“failed to reach the peer URL”] [address=http://10.130.1.3:2380/version] [remote-member-id=217a0d02d7810cc9] [error=“Get "http://10.130.1.3:2380/version\”: dial tcp 10.130.1.3:2380: connect: connection refused"]
[2022/11/15 08:16:12.104 +08:00] [WARN] [cluster_util.go:168] [“failed to get version”] [remote-member-id=217a0d02d7810cc9] [error=“Get "http://10.130.1.3:2380/version\”: dial tcp 10.130.1.3:2380: connect: connection refused"]
[2022/11/15 08:38:58.356 +08:00] [WARN] [probing_status.go:70] [“prober detected unhealthy status”] [round-tripper-name=ROUND_TRIPPER_SNAPSHOT] [remote-peer-id=217a0d02d7810cc9] [rtt=515.015µs] [error=“dial tcp 10.130.1.3:2380: connect: connection refused”]
[2022/11/15 08:38:58.377 +08:00] [WARN] [probing_status.go:70] [“prober detected unhealthy status”] [round-tripper-name=ROUND_TRIPPER_RAFT_MESSAGE] [remote-peer-id=217a0d02d7810cc9] [rtt=770.328µs] [error=“dial tcp 10.130.1.3:2380: connect: connection refused”]
有些这些报错,下午的时候比较少,看着像pd 网络问题,
那是我关闭pd节点做测试 所以有这个问题,后面我启动回来了
查了下 我有38 个 Down 的 Region 会不会这个有问题影响到了
Pending Peer 有9000+
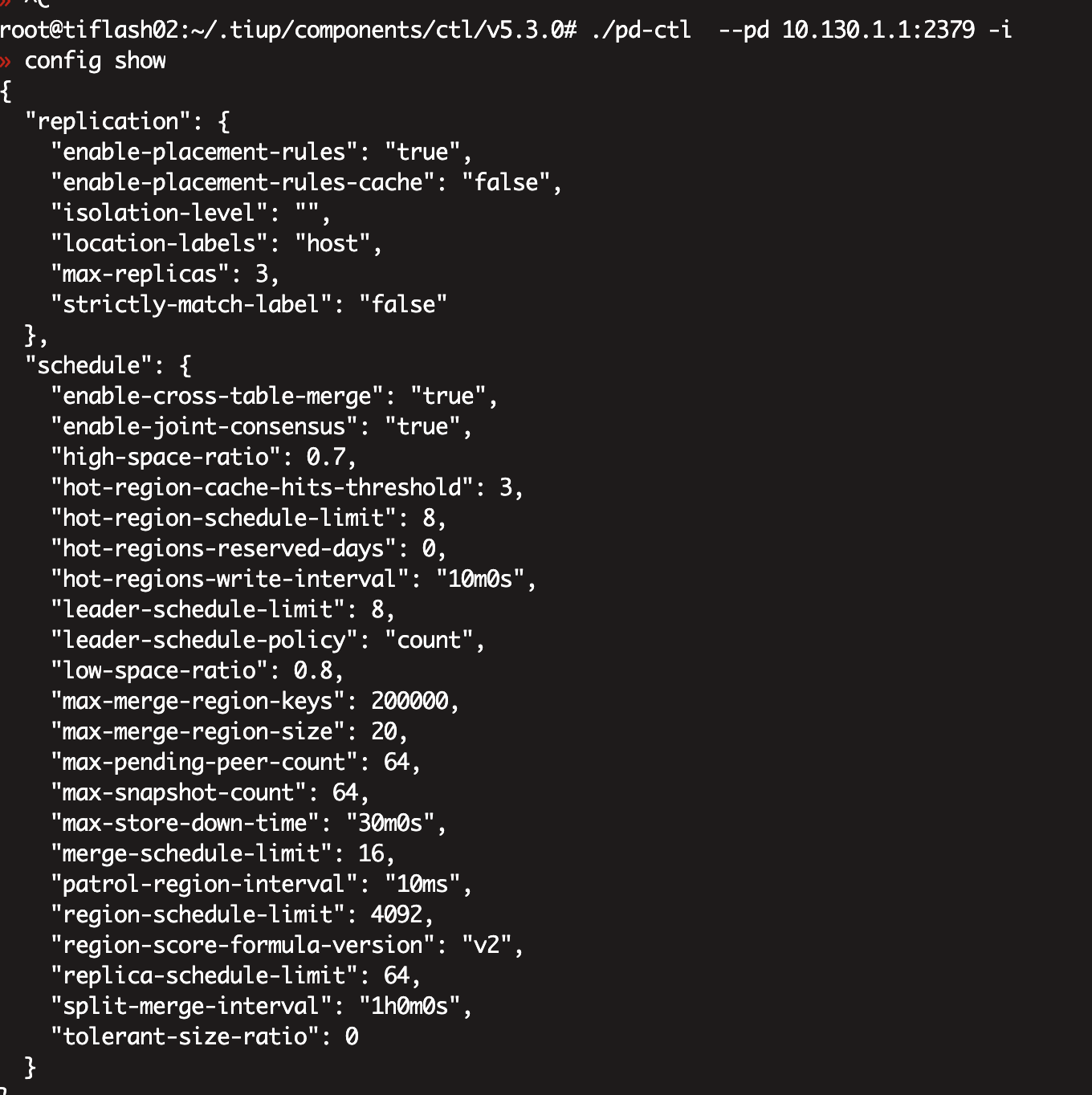
pd-ctl config show ,pd-ctl scheduler show看下 ,PD的监控贴下