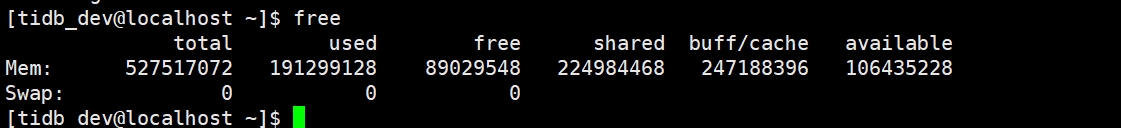【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】
【附件:截图/日志/监控】
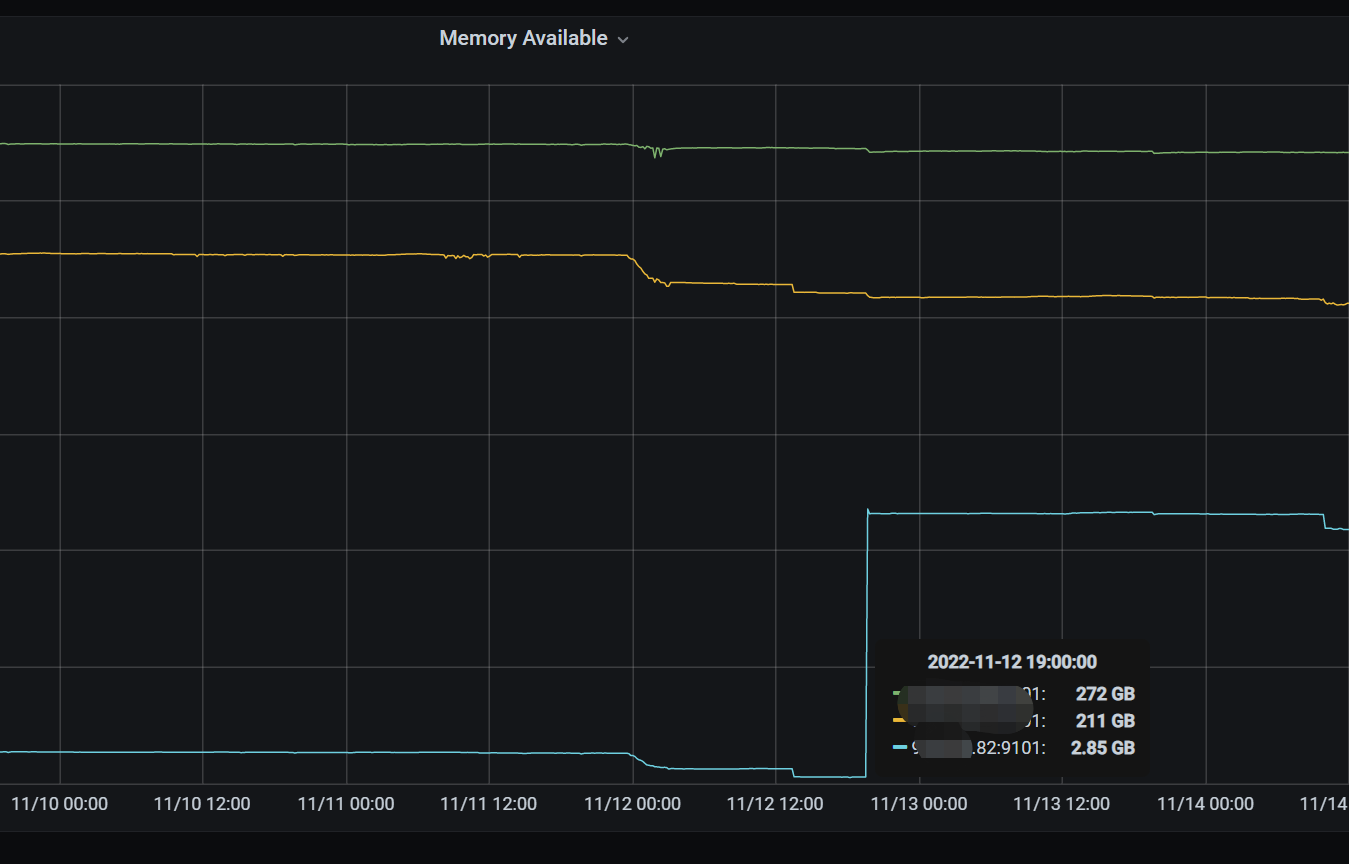
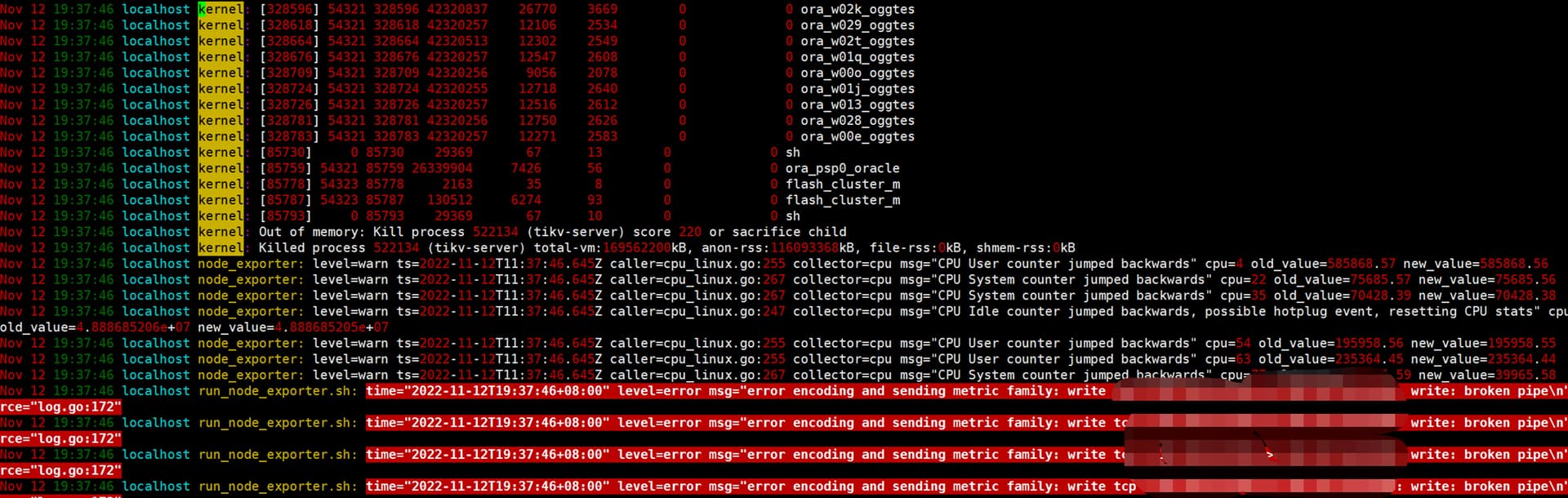
11.12号下午19点左右,tikv节点出现重启现象,查看tikv节点相关日志未发现异常,查看系统日志发现
想问下,这个内存不会自动释放吗?
【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】
【附件:截图/日志/监控】
11.12号下午19点左右,tikv节点出现重启现象,查看tikv节点相关日志未发现异常,查看系统日志发现
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
这两个内容写一下
版本信息:v6.1.1
做过哪些操作:基本没有业务操作,看了一下dashboard 面板出现问题的时间点都是一些内部SQL ,还有监控的SQL
tikv 的内存参数storage.block-cache.capacity 怎么配置的? 机器的内存多少? 是否多实例部署?
先按这排查下
多实例部署,每个tikv 的内存设置 storage.block-cache.capacity = (MEM_TOTAL * 0.5 / TiKV 实例数量)
内存设置过大了,非常容易OOM
机器的内存是527517072 集群设置的是214078MiB ,这套集群是3台服务器组成,没台机器部署了一个TIKV 节点,这样说的话 这个内存设置是合理的,只是这3台服务器部署了4套集群,那这样说的话是 527517072 /0.5/4?
tikv 节点的内存设置过大? 但是tikv 日志没有显示oom 只有服务器的操作日志显示出来了OOM 了
就相当于一台服务器部署了4个tikv 的实例了,如果是这样的,tikv的内存的确设置的太大了。 操作系统的日志显示OOM可以确认这点
这个内存不会自动释放吗?
![]() 3台机器四套集群,均衡混布的话,那每台服务器上有4个tikv节点呀,太多了吧。
3台机器四套集群,均衡混布的话,那每台服务器上有4个tikv节点呀,太多了吧。
内存是缓慢释放的,不是立即全部释放
那这样的话 也是分摊内存,存储啥的吧
可是每台服务器上的4个tikv节点因为不是一套集群的,肯定会存在资源争用的问题,资源不足时,linux的机制应该是随机kill ![]()
这个监控应该是服务器内存,不是tidb内存占用。可以看看每个节点的内存占用,看看是什么原因导致的。也可能时遇到了GC的问题