如果是单节点就很好理解,事务有多大,内存就有多大的占用,可能有一些优化的方式,会采用磁盘做了临时存储,用内存来进行局部回放进行处理。
但是分布式的,就存在多个节点,每个节点上都会分派一部分数据,然后数据又不是严格按照最佳的结构来的匹配,肯定会有放大的情况
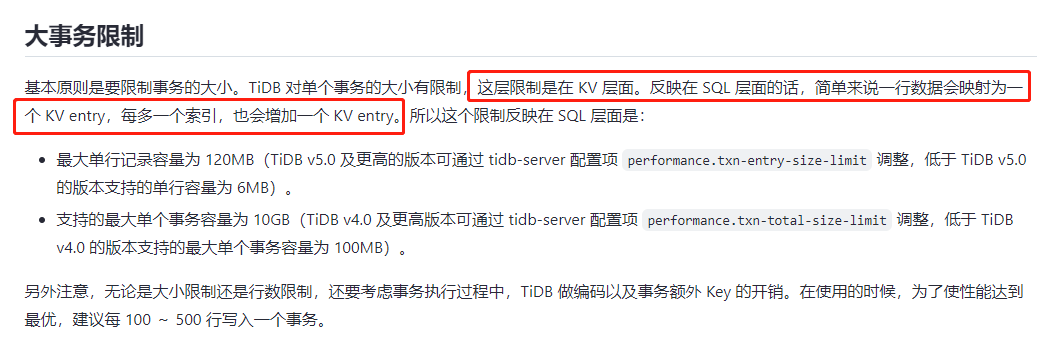
参考官方的解释:
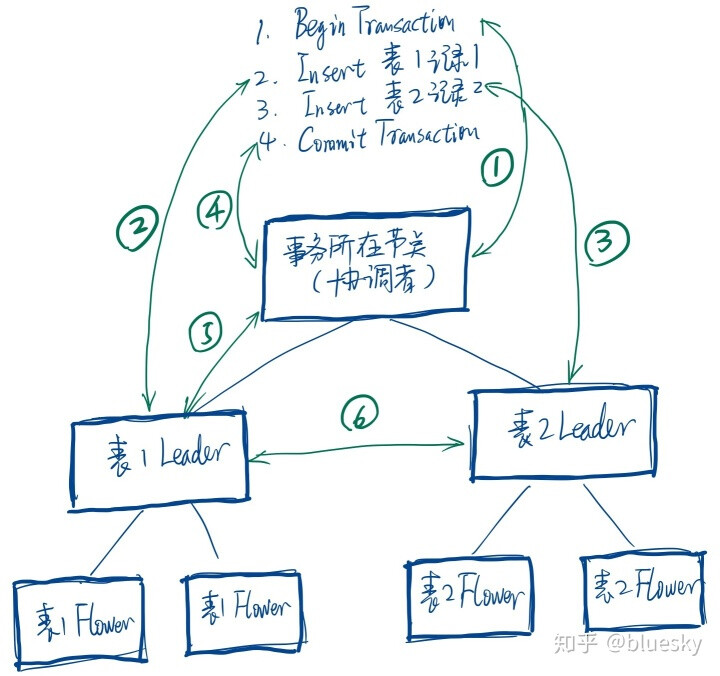
别人画的一张草图,借用一下
主要来表达二阶段提交中需要的多次协调,每次协调都需要保存状态,因为要保证一致性。如果提交成功,就一起写入。如果提交失败,就完全撤回。这个协调的过程,就需要内存来存放很多信息了