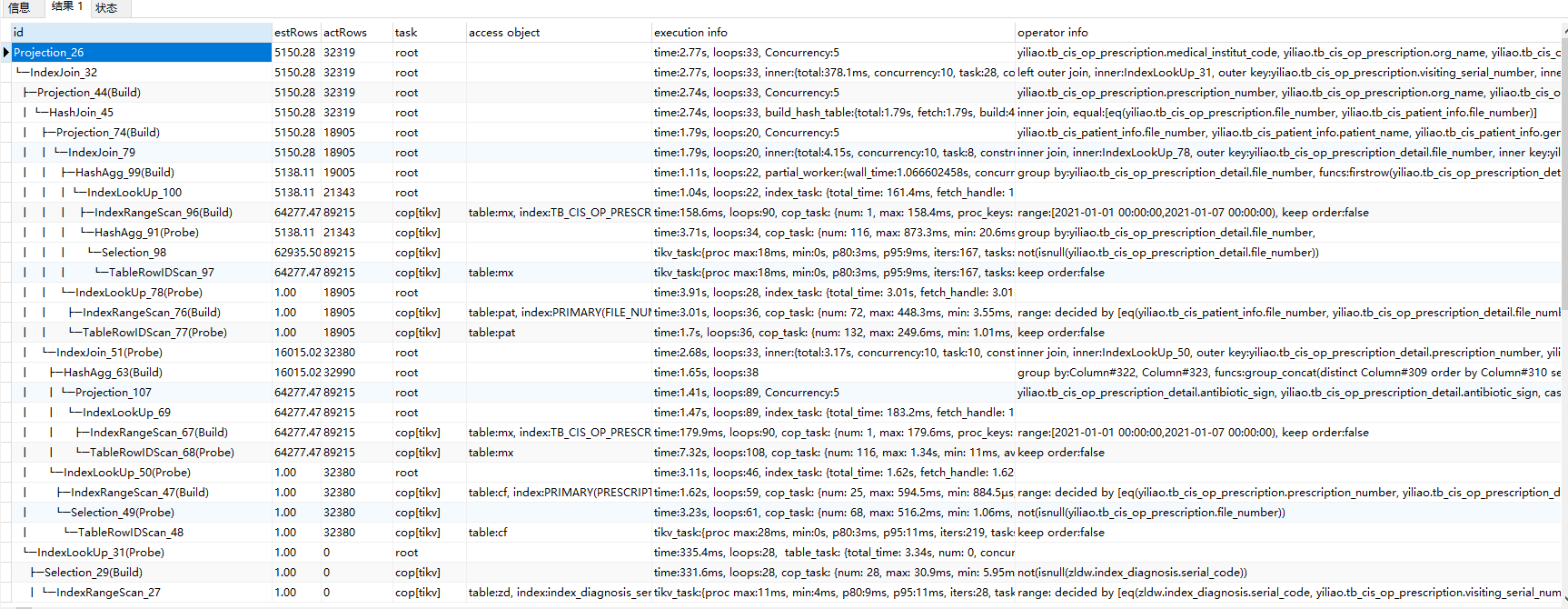
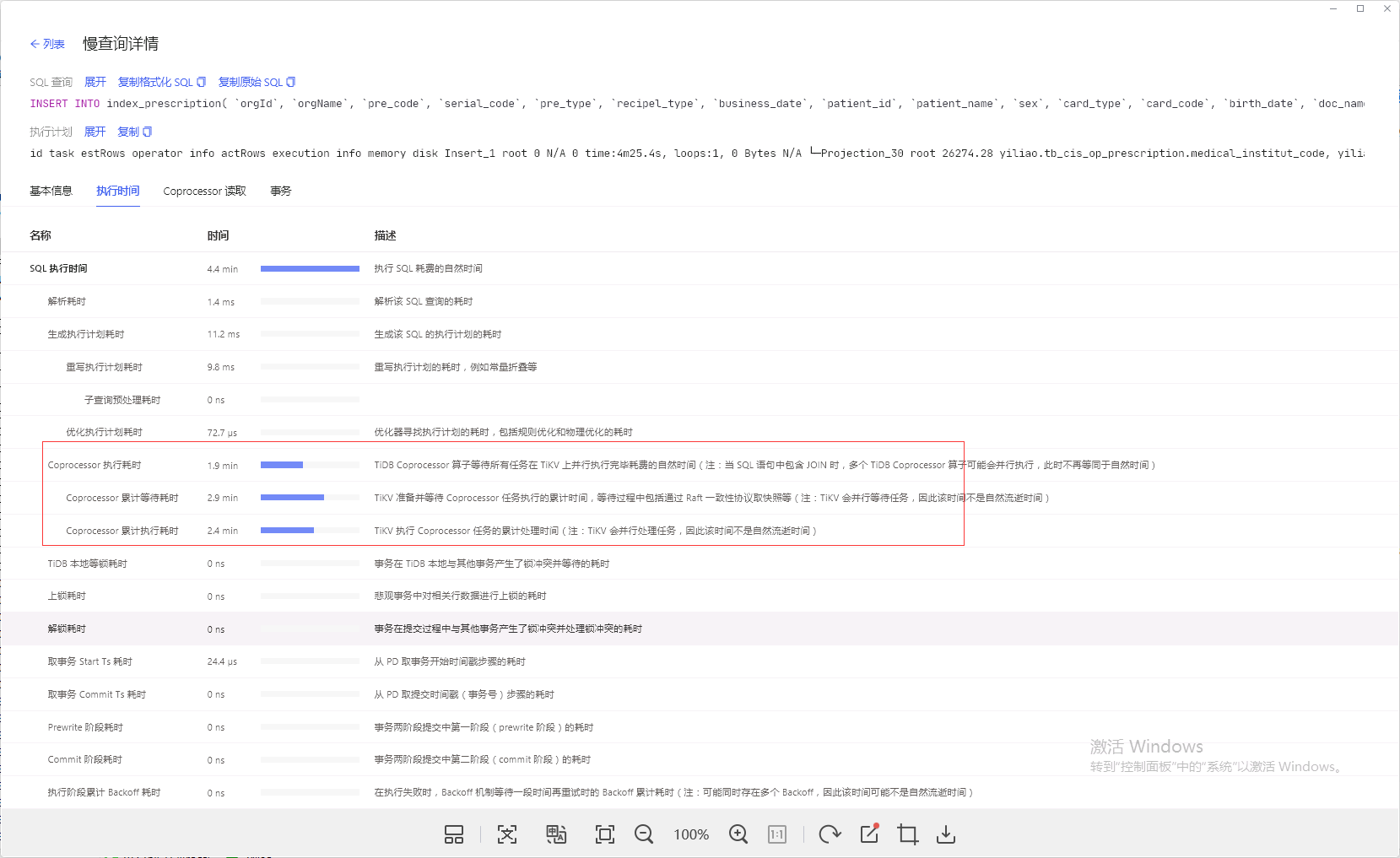
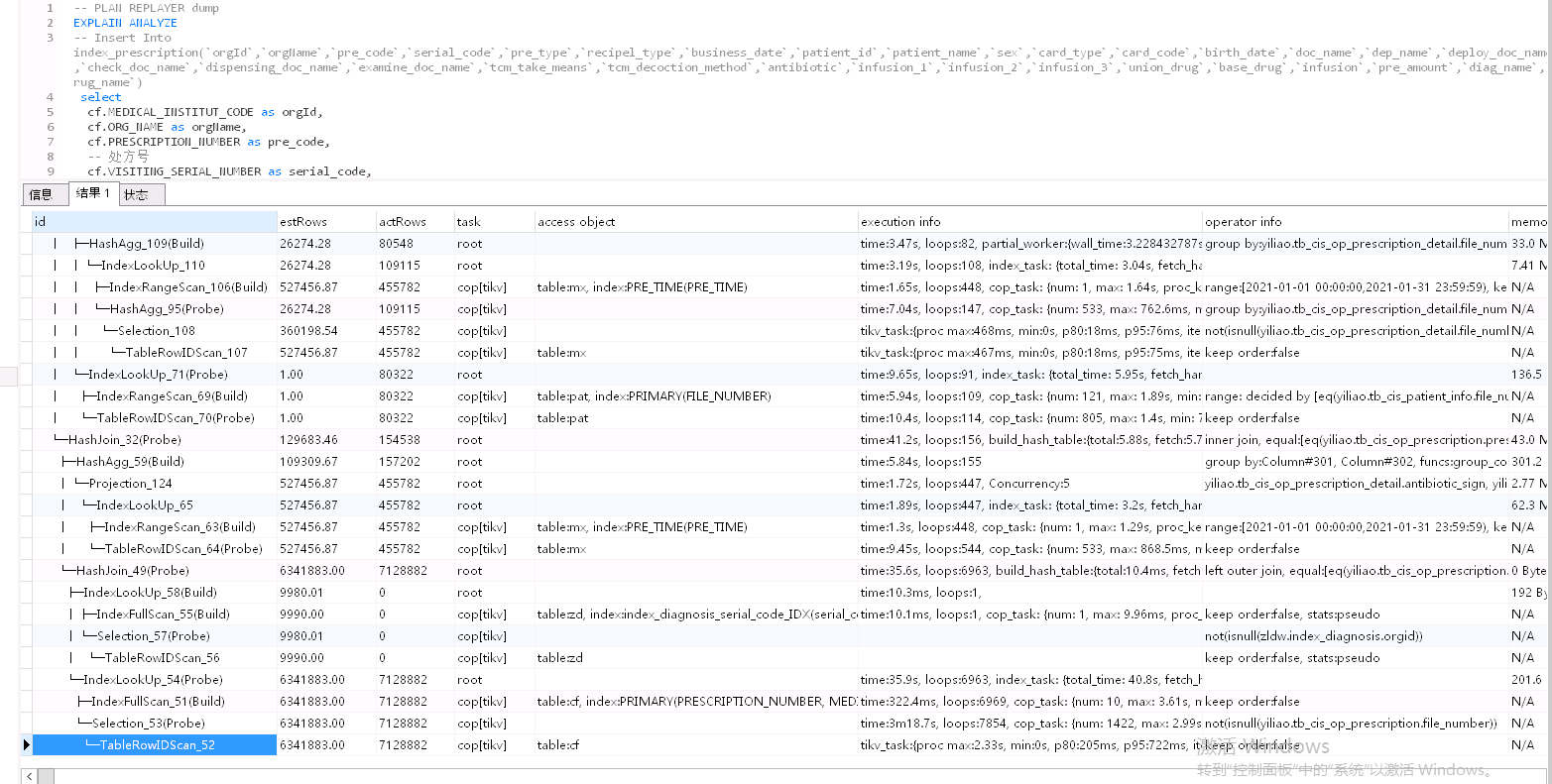
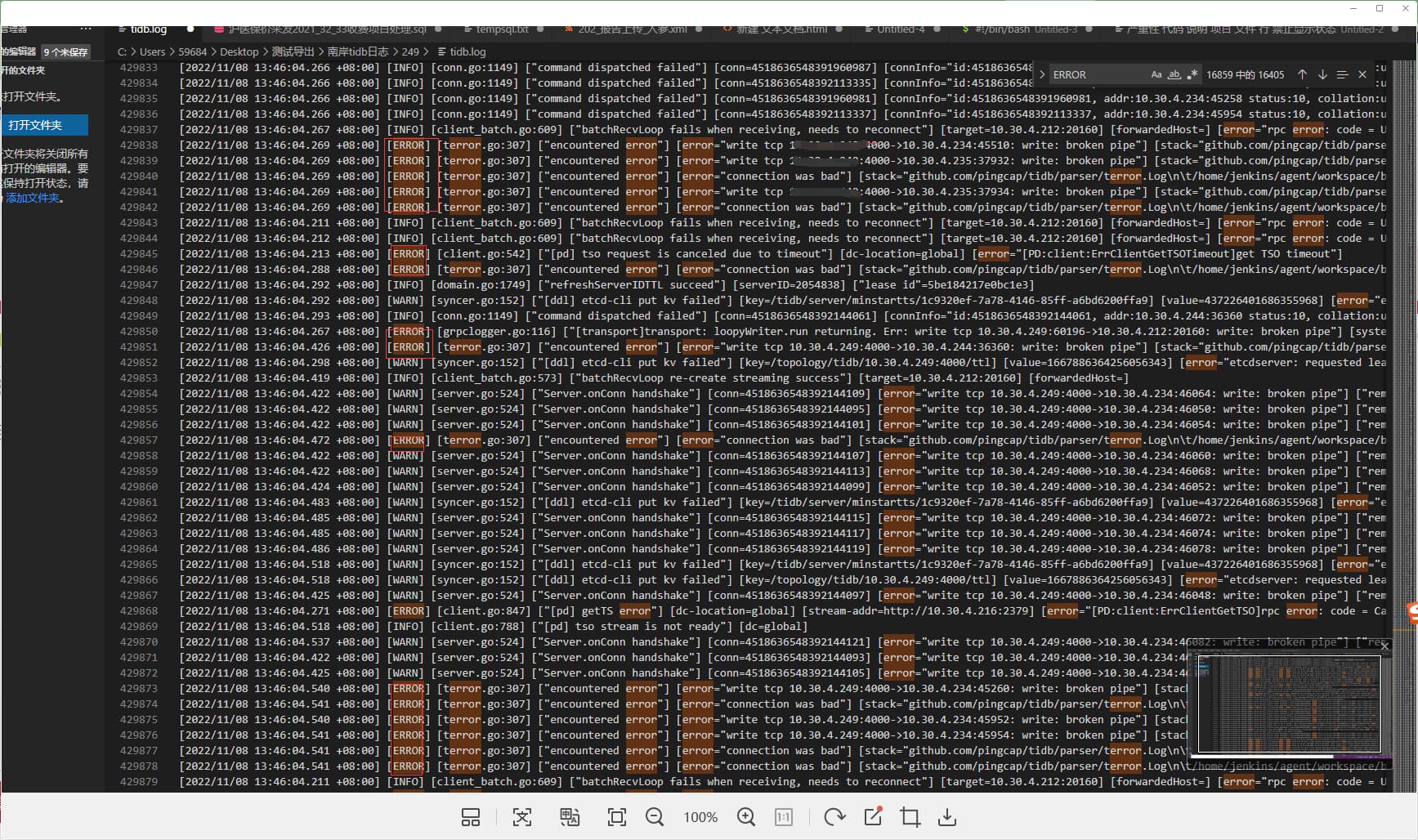
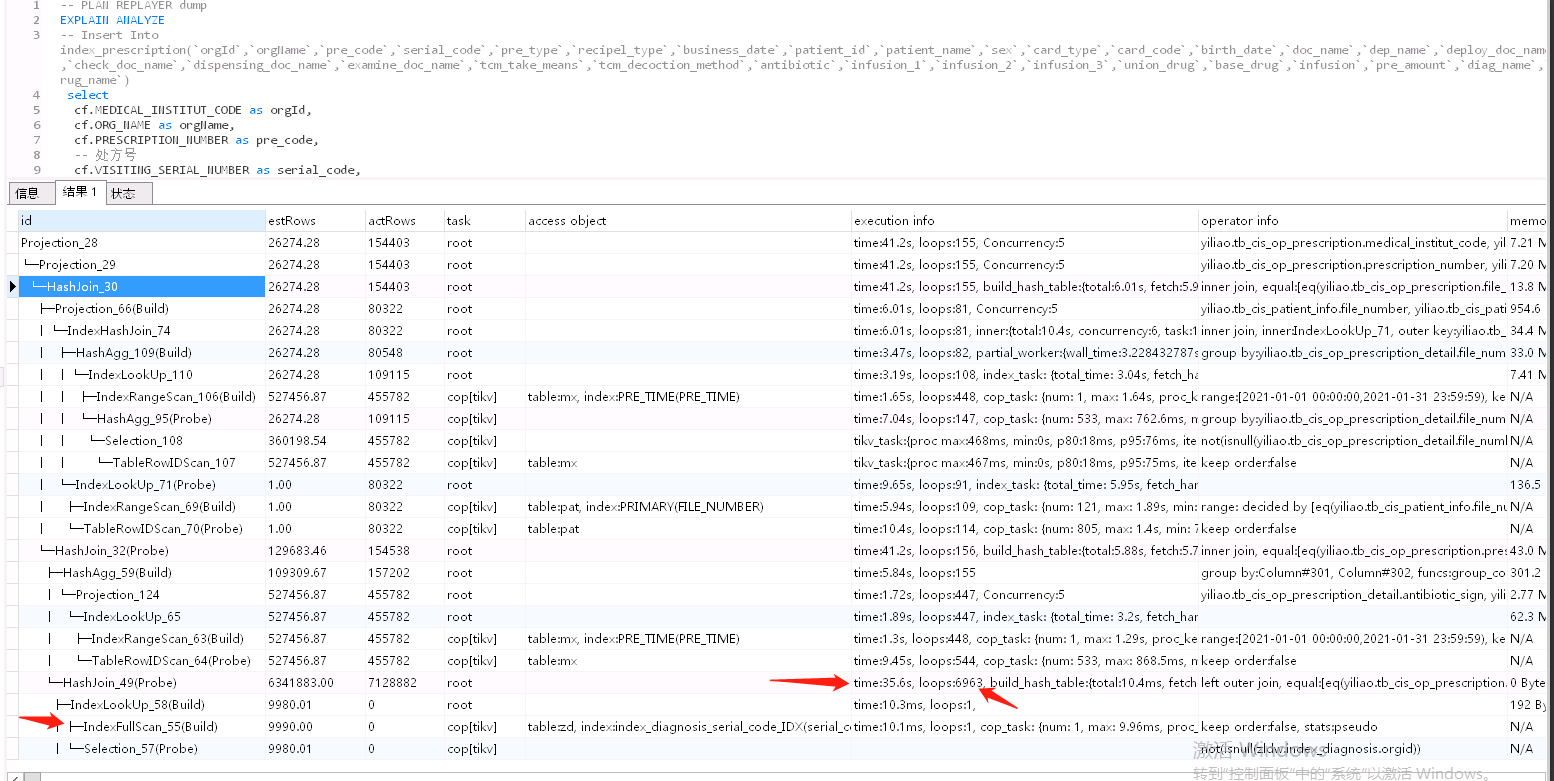
这个sql 有什么优化意见没得,现在卡的要死。
EXPLAIN analyze
select
cf.MEDICAL_INSTITUT_CODE as orgId,
cf.ORG_NAME as orgName,
cf.PRESCRIPTION_NUMBER as pre_code,
-- 处方号
cf.VISITING_SERIAL_NUMBER as serial_code,
-- 门诊号
cf.PRESCRIPTION_PROPERTY as pre_type,
-- 处方类型
ifnull(cf.recipel_type, '1') as recipel_type,
-- 处方种类
cf.PRE_TIME as business_date,
cf.FILE_NUMBER as patient_id,
-- 病人id
br.patient_name,
-- 病人姓名
br.GENDER_CODE as sex,
-- 性别代码
br.ID_TYPE as card_type,
-- 证件类型
br.ID_NUMBER as card_code,
-- 证件号码
br.BIRTH_DATE as birth_date,
-- 出生日期
cf.PRE_DOCTOR_NAME as doc_name,
-- 开方医生,
cf.VISIT_DEP_NAME as dep_name,
-- 开方科室
cf.DEPLOY_PHARMACIST_NAME as deploy_doc_name,
-- 调配药师
cf.CHECK_PHARMACIST_NAME as check_doc_name,
-- 核对药师
cf.ISSUE_PHARMACIST_NAME as dispensing_doc_name,
-- 发药药师
cf.PRE_CHECK_DOC_CODE as examine_doc_name,
-- 审核药师
cf.tcm_take_means,
-- 中医服法
cf.tcm_decoction_method,
-- 中药煎煮法代码
antibiotic,
infusion_1,
infusion_2,
infusion_3,
union_drug,
base_drug,
infusion,
pre_amount,
-- max(zd.diag_name) as diag_name, -- 诊断名称
zd.diag_name as diag_name,
mx.drug_name
from
yiliao.TB_CIS_OP_PRESCRIPTION cf use INDEX(PRIMARY)
inner join
(
select
/*+ AGG_TO_COP() */
mx.PRESCRIPTION_NUMBER,
mx.MEDICAL_INSTITUT_CODE,
GROUP_CONCAT(distinct mx.ANTIBIOTIC_SIGN order by mx.ANTIBIOTIC_SIGN) as antibiotic,
-- 抗生素标志
max(case when mx.ANTIBIOTIC_SIGN = '1' then 1 else 0 end) as infusion_1,
-- 非限制使用的抗生素
max(case when mx.ANTIBIOTIC_SIGN = '2' then 1 else 0 end) as infusion_2,
-- 限制使用的抗生素
max(case when mx.ANTIBIOTIC_SIGN = '3' then 1 else 0 end) as infusion_3,
-- 特殊使用的抗生素
count(case when mx.ANTIBIOTIC_SIGN != '0' then mx.id else null end) as union_drug,
-- 联合用药
GROUP_CONCAT(distinct ifnull(mx.DRUG_BASE_ATTR_CODE, '1') order by mx.DRUG_BASE_ATTR_CODE) as base_drug,
-- 药物基药属性
max(case when mx.DRUG_USE_MEANS_CODE = '404' then 1 else 0 end) as infusion,
-- 是否输液处方
sum(mx.DRUG_AMOUNT) as pre_amount,
-- 处方金额
GROUP_CONCAT(distinct mx.ITEM_NAME) as drug_name
-- 药品名称集合
from
yiliao.TB_CIS_OP_PRESCRIPTION_DETAIL mx
where
mx.PRE_TIME >= '2021-01-01 00:00:00'
and mx.PRE_TIME <'2021-01-07 00:00:00'
group by
mx.MEDICAL_INSTITUT_CODE,
mx.PRESCRIPTION_NUMBER
) mx
on
cf.PRESCRIPTION_NUMBER = mx.PRESCRIPTION_NUMBER
and cf.MEDICAL_INSTITUT_CODE = mx.MEDICAL_INSTITUT_CODE
inner join
(
select /*+ AGG_TO_COP() */
pat.FILE_NUMBER,
pat.patient_name,
-- 病人姓名
pat.GENDER_CODE ,
-- 性别代码
pat.ID_TYPE ,
-- 证件类型
pat.ID_NUMBER ,
-- 证件号码
date(pat.BIRTH_DATE) as BIRTH_DATE
-- 出生日期
from
yiliao.TB_CIS_PATIENT_INFO pat
##use index(PRIMARY)
where
FILE_NUMBER in (
select
FILE_NUMBER
from
yiliao.TB_CIS_OP_PRESCRIPTION_DETAIL mx
where
mx.PRE_TIME >= '2021-01-01 00:00:00'
and mx.PRE_TIME <'2021-01-07 00:00:00'
)
)
br on
cf.FILE_NUMBER = br.FILE_NUMBER
left join index_diagnosis zd USE index(index_diagnosis_serial_code_IDX) on
cf.MEDICAL_INSTITUT_CODE = zd.orgid
and cf.VISITING_SERIAL_NUMBER = zd.serial_code