【 TiDB 使用环境】测试
【 TiDB 版本】v6.1.0
【复现路径】
【遇到的问题:问题现象及影响】
执行 SELECT COUNT(*) FROM dx_hash_map 超过系统默认的1min 之后直接lost connection to mysql
相当于是oom
【资源配置】
tidb、pd 3台一起部署 16核 16g
tikv 3台独立 16核32g
结合 该专栏 专栏 - tidb server的oom问题优化探索 | TiDB 社区 进行了 调整
还是出现oom
在tidblog中的oom错误
按照专栏里面有个问题是 如果超过了设定的内存 会走disk 但是查看也没有

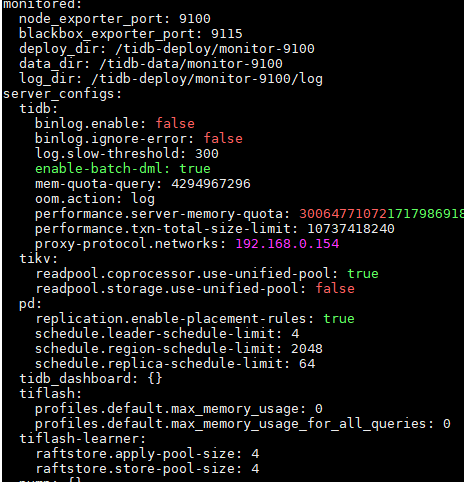
集群tidb的配置
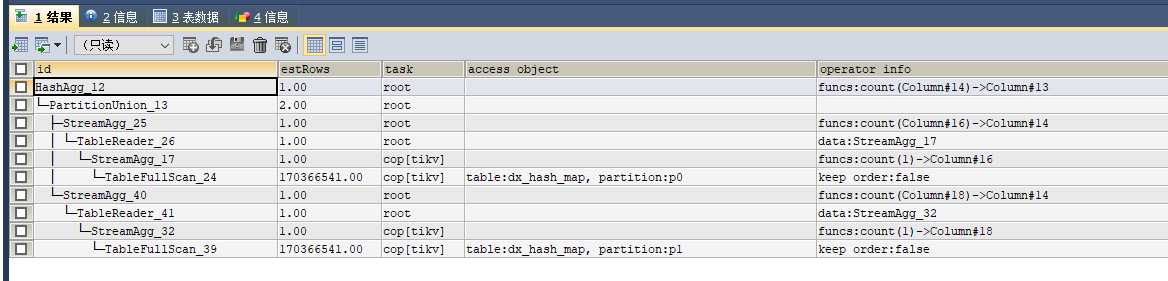
执行计划
WalterWj
(王军 - PingCAP)
4
感觉不是这个 SQL 导致的,日志中 expensive SQL 只是说这个 SQL 扫的数据很多。
你这个 SQL count 从执行计划上是 tikv 做的,还有 OOM 是指什么 OOM ,tikv 还是 tidb ,还是 tiflash。我看日志中有 hint 走 tiflash engine
WalterWj
(王军 - PingCAP)
5
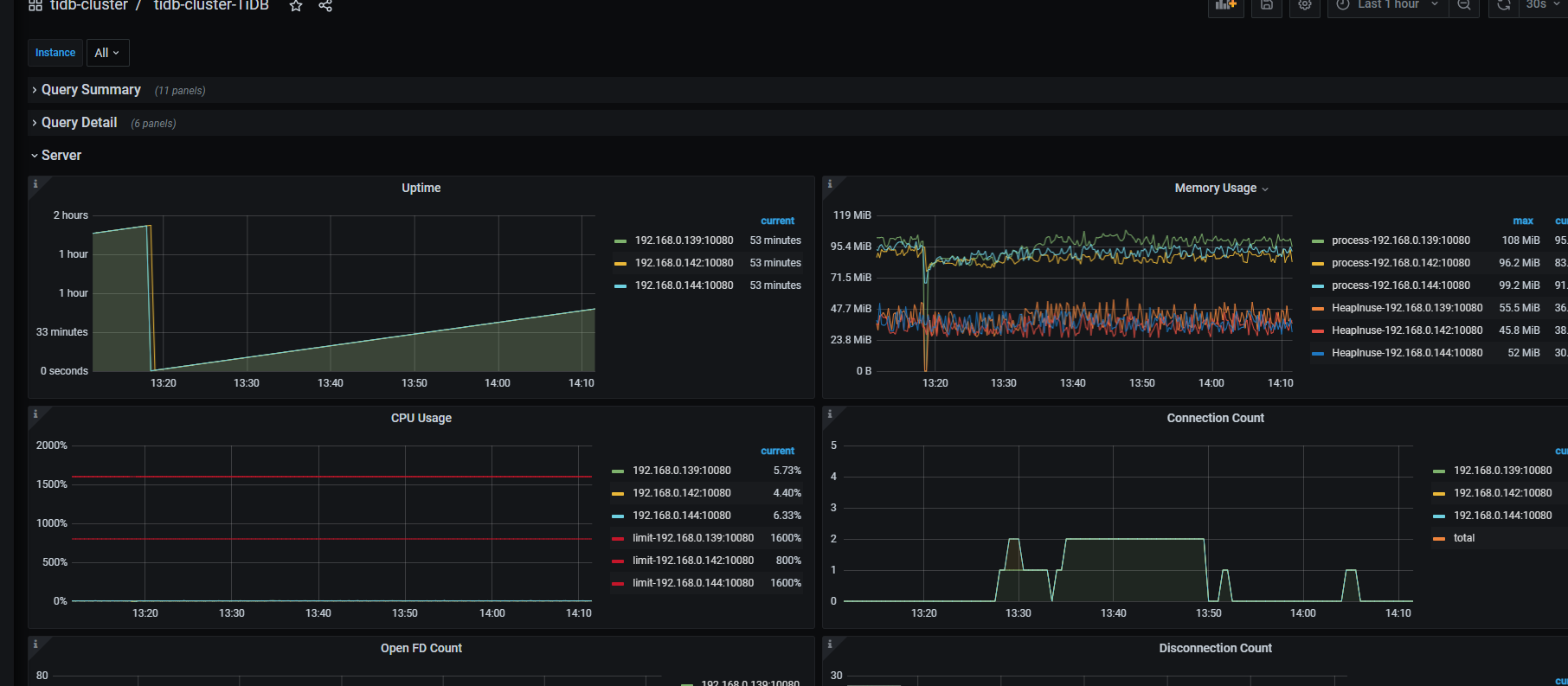
判断是否 OOM 看下监控的 uptime 或者服务器的 dmesg -T | grep tidb
dmesg -T | grep tidb 该命令在这集群的机器中没有找到日志信息
(目前集群是进行了扩容)
WalterWj
(王军 - PingCAP)
8
没有找到的话 我理解应该没有 OOM 吧,看看监控中 服务器内存使用率和各个组件的 uptime,确定有没有 oom 或者进程重启吧。
如果都没有 我理解不是 oom 了
裤衩儿飞上天
10
感觉你这个像是网络上有时间限制,超时后关掉了连接
你别用客户端登录,直接等服务器去执行看看
在客户端执行 也还是出现 lost connection…

目前用了haproxy 去转发tidb
WalterWj
(王军 - PingCAP)
14
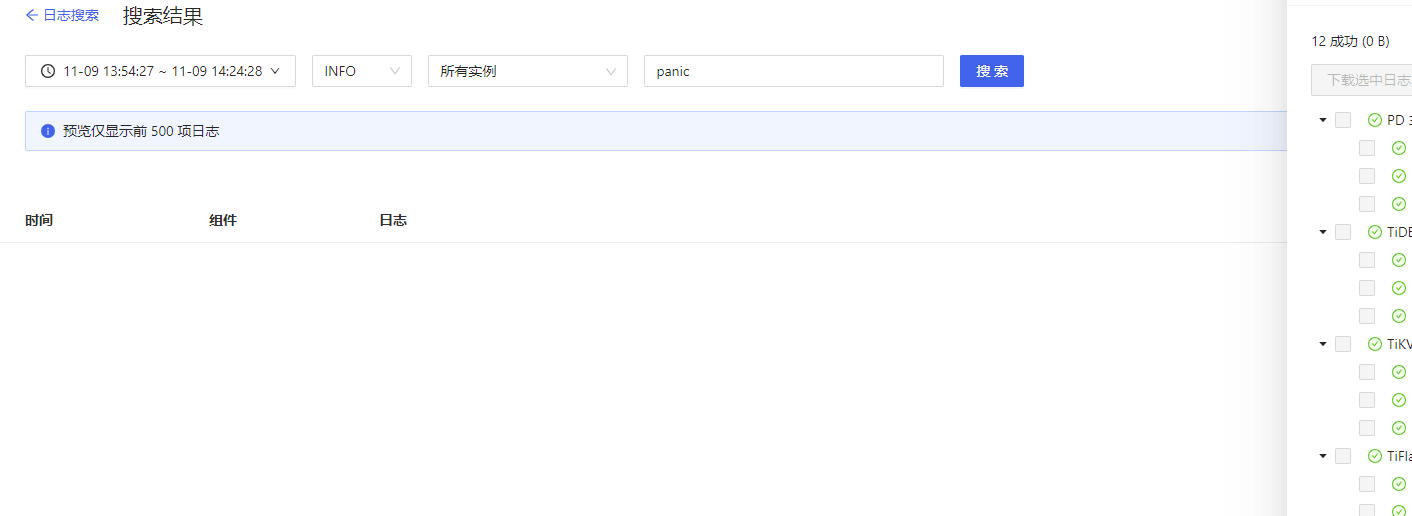
去 dashboard 中 日志搜索 看看有没有 panic 关键字
直连是可以的,haproxy这里面的优化连接 是否有相关的方案? 
执行
select count(*),imei from dx_hash_map group by imei