【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.1.0
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
告警详情:TiCDC heap memory usage is over 10 GB
【资源配置】
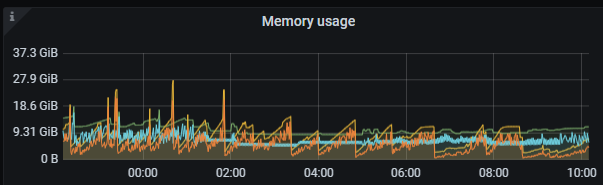
给cdc配置了256G的主机内存,实际使用10G,仍然会使用主机磁盘空间,如何调整使用更大的内存,而且cdc任务有延迟。源端没有发现大的事务,如何分析,是否是推送到kafka慢
total used free shared buff/cache available
Mem: 251 9 232 0 9 241
Swap: 31 0 31
【附件:截图/日志/监控】




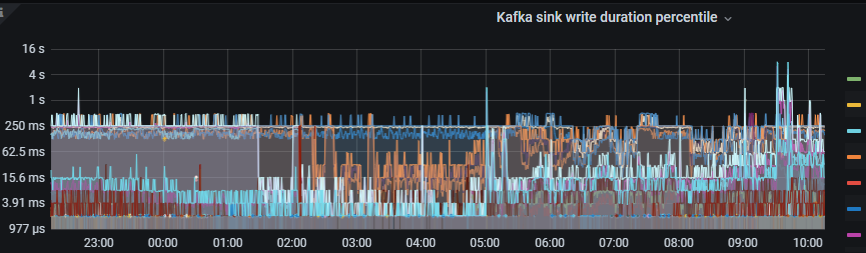
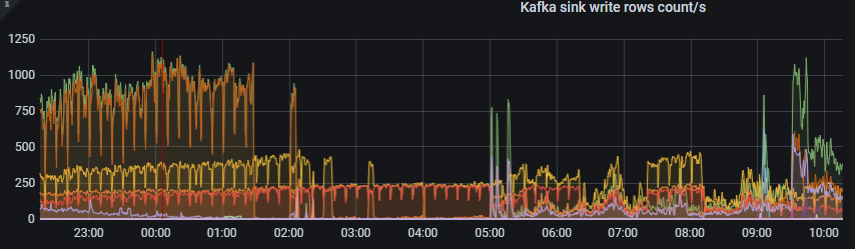
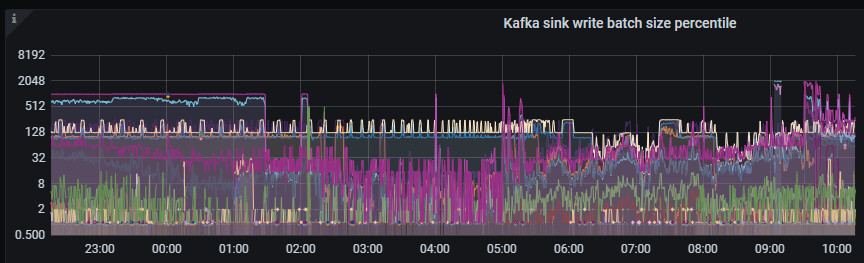

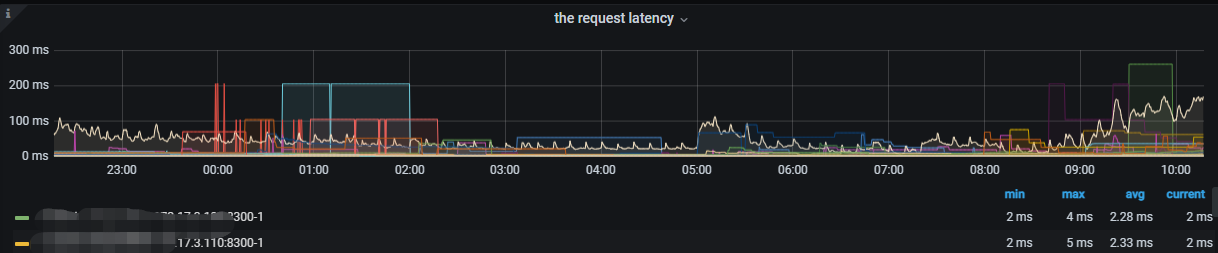
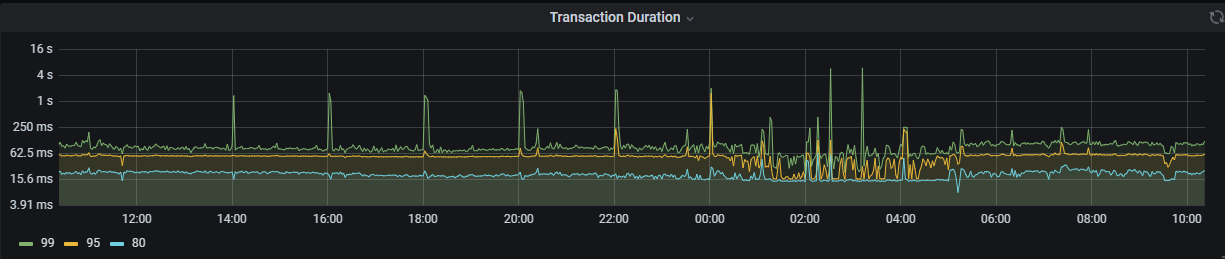
延迟的原因一般的排查思路
-
上游
a. 大事务提交导致延迟性处理
b. 资源瓶颈导致event 处理慢
c. 网络拥塞 -
CDC本身
参考 监控指标很容易查阅到了,这个不需要在描述了 -
下游
a. 接受延迟,下游拥塞导致的(已经堆满了,处理不及时)
b. 网络拥塞
c. 资源不足,导致处理慢
具体的要一项项的排查,会比较麻烦了,供你参考
1 个赞
TiCDC heap memory usage is over 10 GB, 在cdc单独部署的情况下,这个TiCDC heap memory 的使用是在tikv主机还是cdc主机,这个原理还是有些不明白
这个收集文件太多,文件太大,而且太慢,导致每次收集会中断,有没有其他的诊断方式