【 TiDB 使用环境】生产环境
【 TiDB 版本】v5.4.3
【遇到的问题】
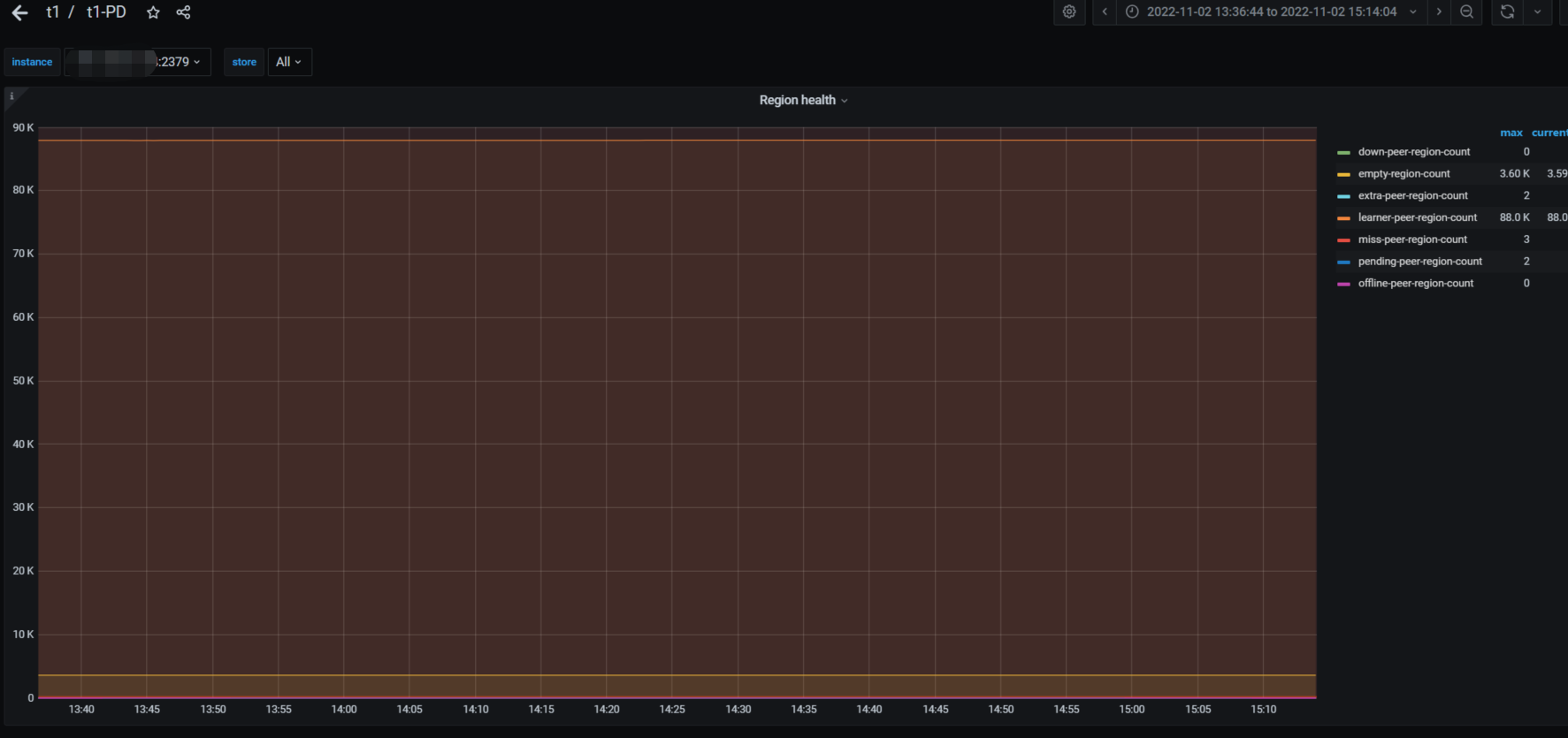
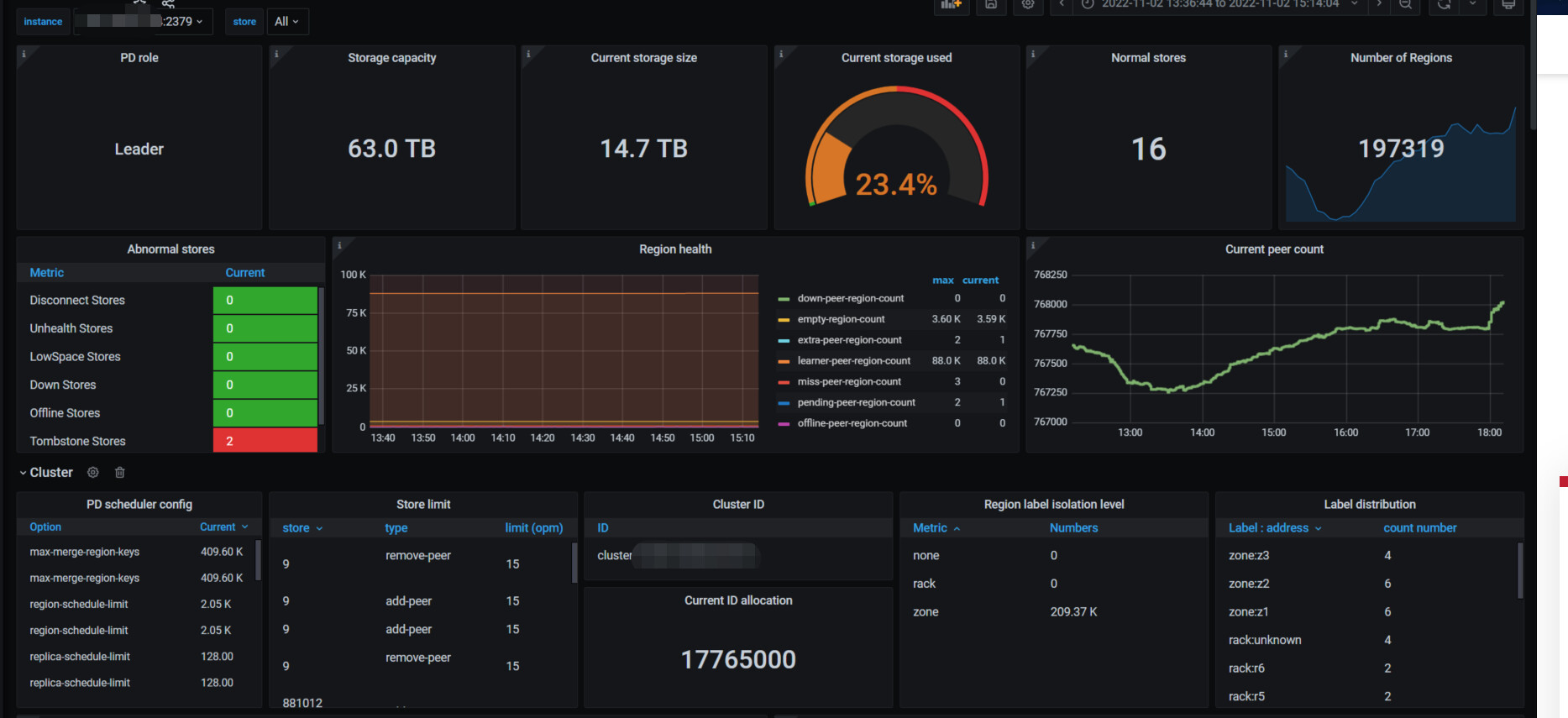
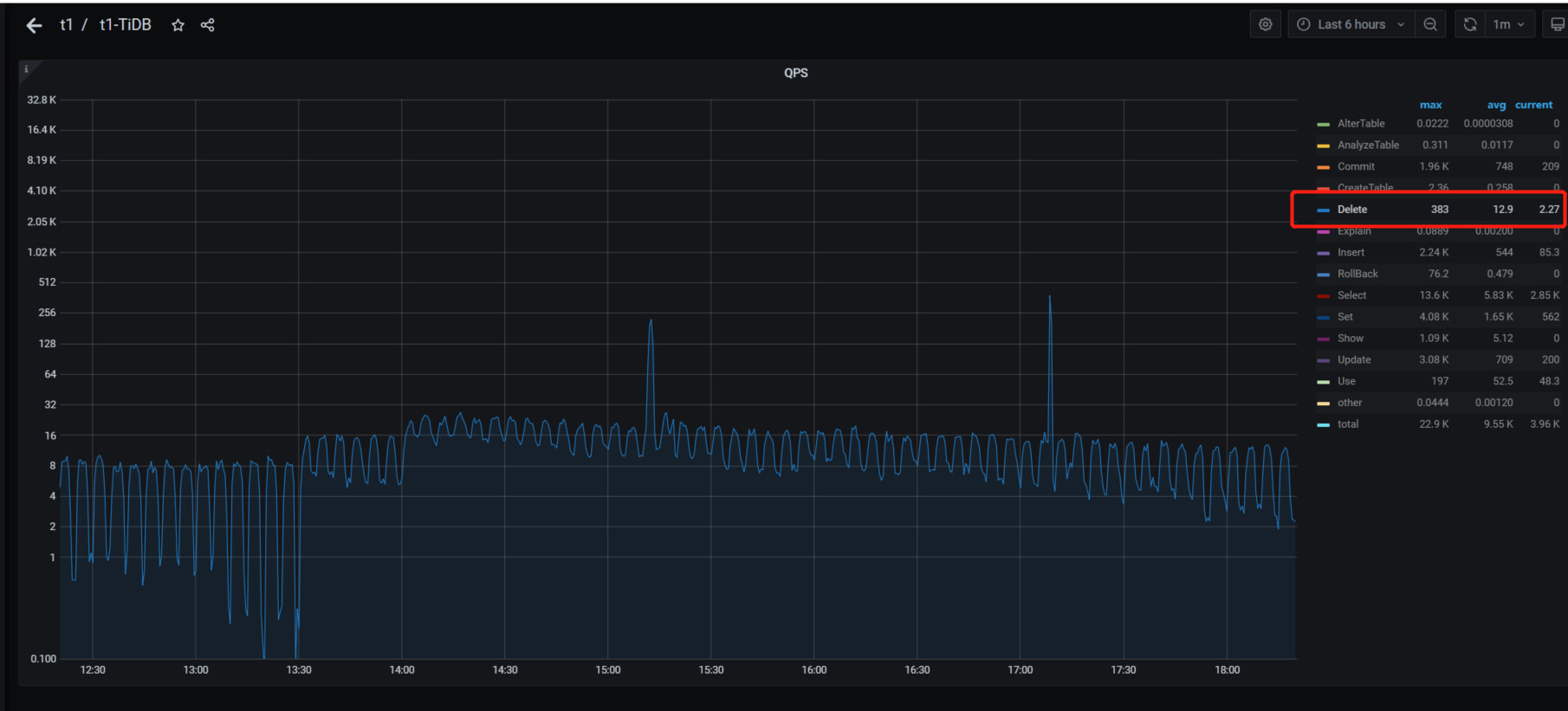
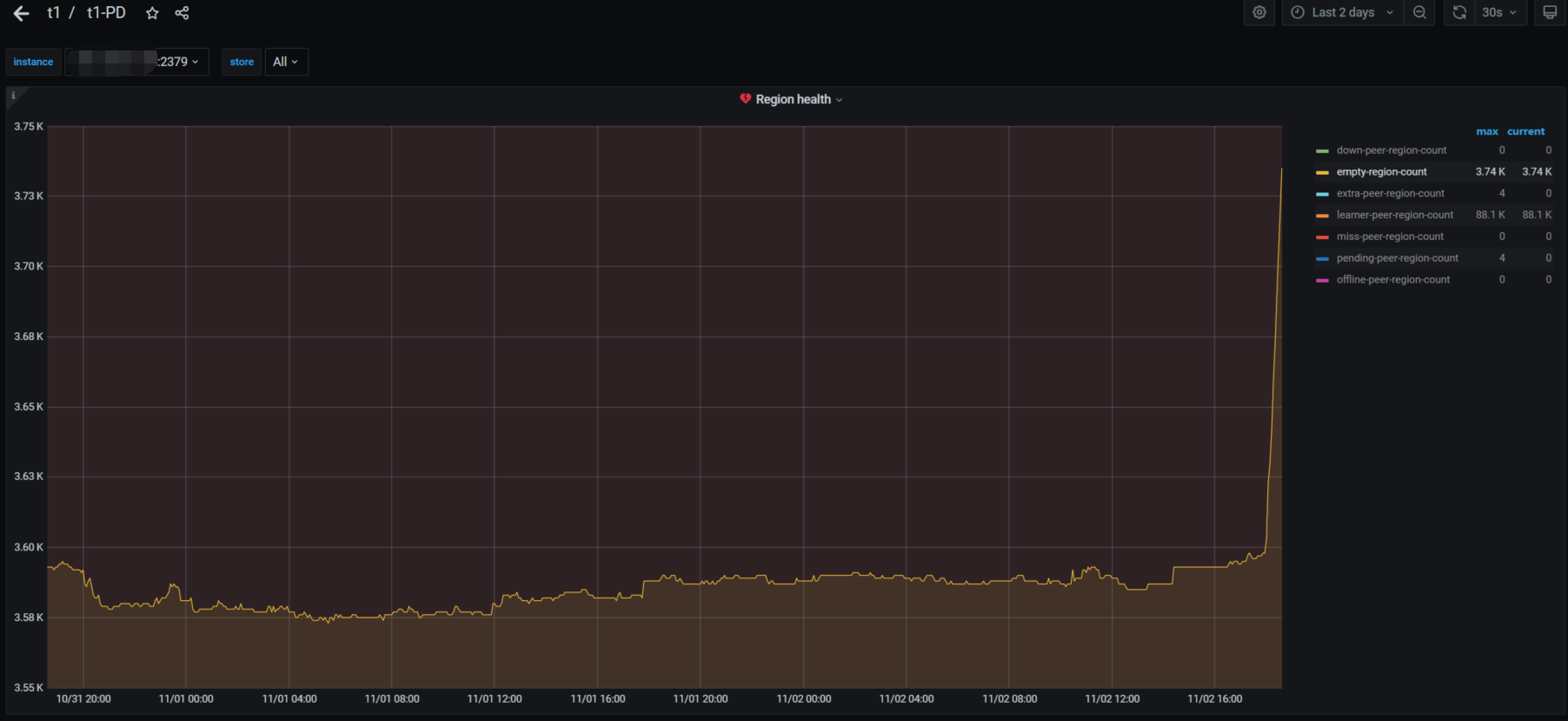
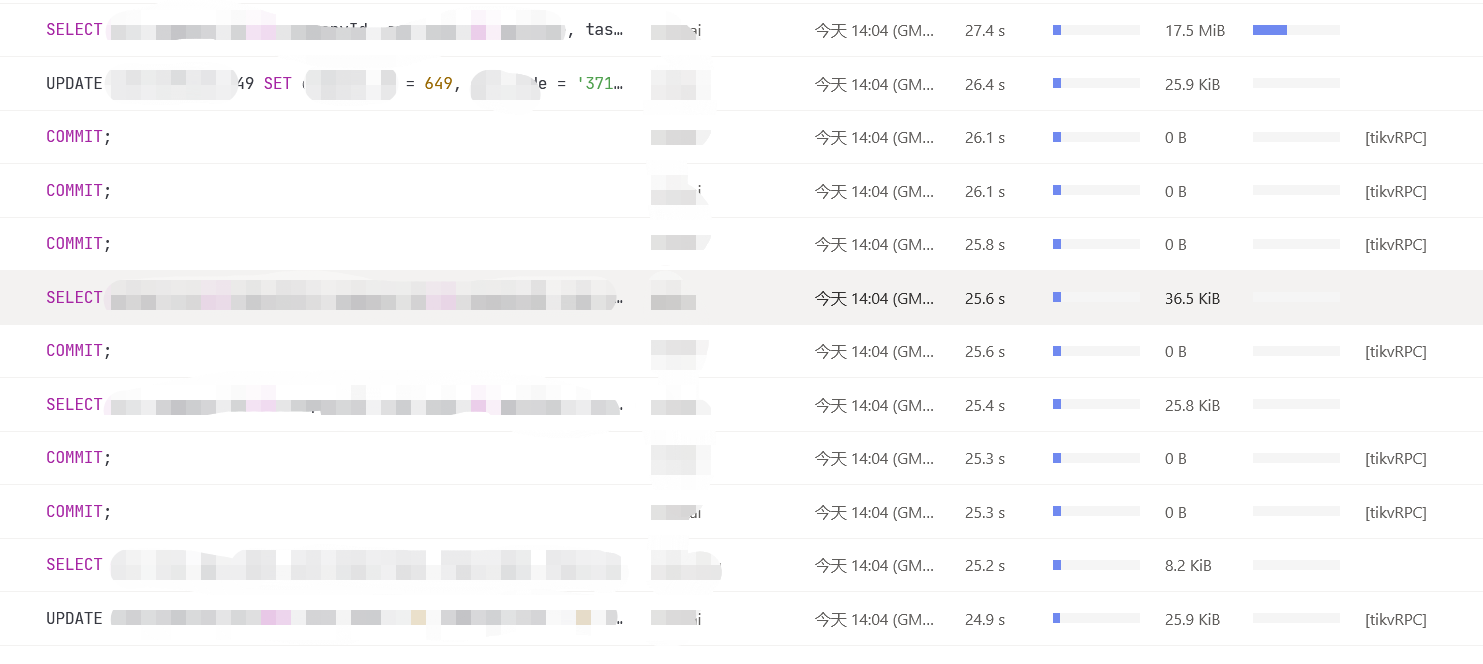
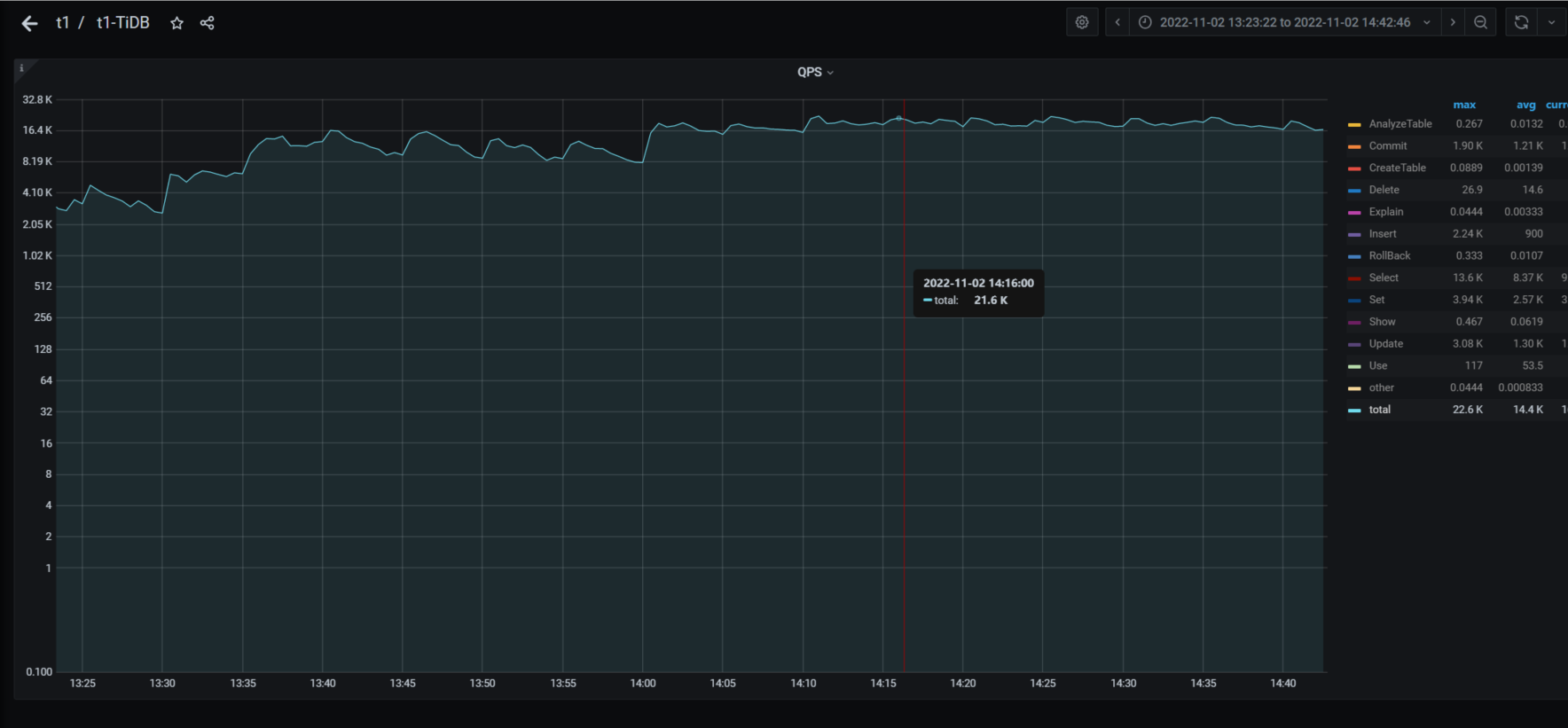
今天下午14点04分50多秒和14点13分出现两批慢查询,尤其是14点04分那次,但是实际上业务量并不高,qps不到3万,查看相关监控如下
dashboard慢查询
qps监控
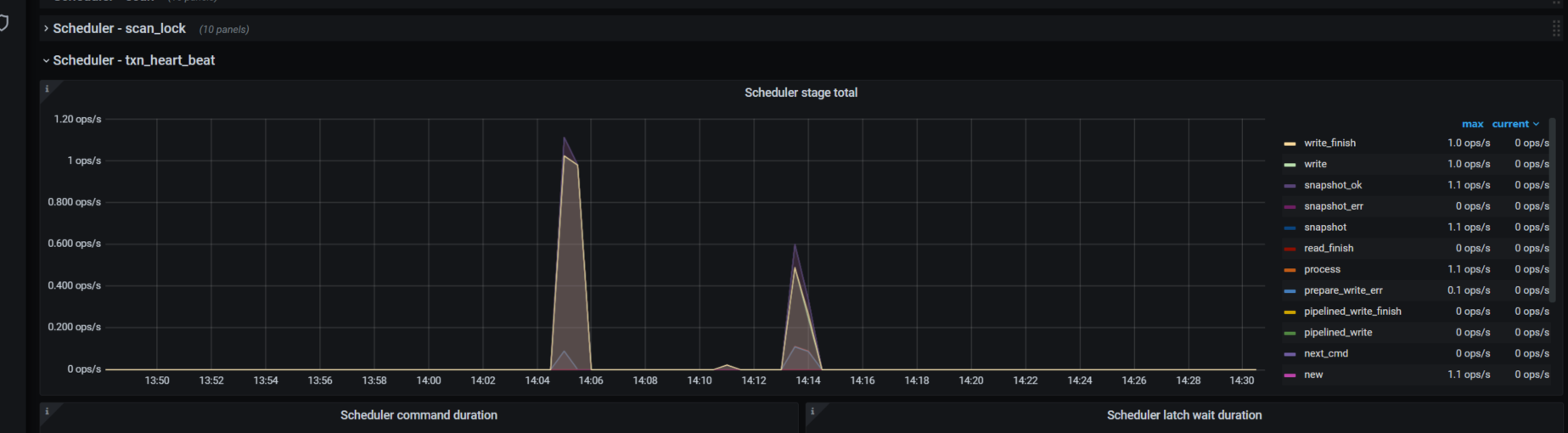
cpu,内存,io等监控都比较正常,但是如下几个监控有异常,官方文档没有查到这几个监控指标的含义,所以不太懂
tikv-details - scheduler-key_mvcc界面


scheduler-txn_heart_neat
【复现路径】做过哪些操作出现的问题
正常的业务
【问题现象及影响】
出现很多慢查询,集群卡住两次,怀疑是网络问题,但是想知道如何从监控确认是网络问题
【附件】
请提供各个组件的 version 信息,如 cdc/tikv,可通过执行 cdc version/tikv-server --version 获取。