啊 又没人气了吗。。![]()
大佬 能帮忙看看昨天我传的debug文件吗? 我看不懂。。
等大佬们来看
创建一张新表没有任何约束(没有主键或者唯一键),插入下看看效率如何呢?
试过只保留一个主键,是一样的结果。 而且就算没主键,也是会隐式产生一个主键的,理论上是一样的结果。
create_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ,
update_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE
把这两个去掉,然后导入下试试呢?看stack好像在获取default时间的时候慢了。
1 个赞
我去! 17s 了! 真乃神人啊! 请截个图 帮忙告知 以后我该怎么看 那个debug 的记录?
然后,为啥这两个会影响时间?求教!

从stack里面看是在获取时间时候慢了,但是为什么慢我看了下相关代码也没看出来。试试吧其它信息也上传下看看?比如dashboard里面的高级调试->持续分析哪里,把执行语句时候的分析结果下载下来看看?
你好 ,调试结果暂时还没出。 我又发现一些现象 跟你一起分享下:
先看原表的表结构:
CREATE TABLE `test_dws_performance_order15` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`order_no` bigint(20) unsigned DEFAULT NULL COMMENT '订单号',
`fs_order_no` varchar(64) DEFAULT NULL COMMENT '金服支付单号',
`item_id` bigint(20) unsigned DEFAULT NULL COMMENT 'item_id 随便取一个,针对单个的时候有用',
`item_ids` varchar(2000) DEFAULT NULL COMMENT 'item_id 多个用逗号隔开',
`item_names` varchar(2000) DEFAULT NULL COMMENT '商品名称 多个用逗号隔开',
`sku_id` bigint(20) unsigned DEFAULT NULL COMMENT 'sku_id',
`sku_ids` varchar(2000) DEFAULT NULL COMMENT 'skuID 多个用逗号隔开',
`sku_names` varchar(2000) DEFAULT NULL COMMENT 'sku名称 多个用逗号隔开',
`cate_id` bigint(20) DEFAULT NULL COMMENT '商品类目',
`cate_name` varchar(500) DEFAULT NULL COMMENT '商品类目名词(机构SLA、医生SLA、新生儿影像的类目为sla对应类目,其他的均为前端映射业务名称)',
`biz_type_id` bigint(20) DEFAULT NULL COMMENT '业务类型ID',
`biz_type_name` varchar(20) DEFAULT NULL COMMENT '业务类型名词',
`position_type_id` tinyint(4) DEFAULT NULL COMMENT '岗位类型 1:院内线 2 医生线',
`institution_id` bigint(20) DEFAULT NULL COMMENT '实际业务机构ID',
`weimaihao` bigint(20) DEFAULT NULL COMMENT '微脉号',
`user_name` varchar(100) DEFAULT NULL COMMENT '患者姓名',
`mobile` varchar(12) DEFAULT NULL COMMENT '手机号',
`doctor_id` bigint(20) DEFAULT NULL COMMENT '医生ID',
`doctor_name` varchar(50) DEFAULT NULL COMMENT '医生姓名',
`pay_time` datetime DEFAULT NULL COMMENT '金服支付时间-网络诊间用完成时间',
`order_amount` decimal(20,4) DEFAULT NULL COMMENT '订单金额',
`pay_amount` decimal(20,4) DEFAULT NULL COMMENT '实付金额',
`preference_amount` decimal(20,4) DEFAULT NULL COMMENT '优惠金额',
`drug_amount` decimal(20,4) DEFAULT NULL COMMENT '原药费',
`gradient_preference_amount` decimal(20,4) DEFAULT NULL COMMENT '梯度优惠金额',
`confirmed_amount` decimal(20,2) DEFAULT NULL COMMENT '确收金额-后续计算使用',
`base_amount` decimal(20,4) DEFAULT NULL COMMENT '积分计算基准金额',
`performance_points` bigint(20) DEFAULT NULL COMMENT '积分(仅结算中心获取订单数据可以)',
`performance_coefficient` decimal(20,4) DEFAULT NULL COMMENT '业绩系数(仅结算中心获取订单数据存在)',
`bd_id` bigint(20) DEFAULT NULL COMMENT '业务获取的一线BDID 可能花名册中不存在,不跟花名册关联',
`bd_role_id` tinyint(4) DEFAULT NULL COMMENT 'BD类型 院内线:业务BD 医生线:医生BD/医生BDM 以业务系统存储的为准',
`bd_name` varchar(40) DEFAULT NULL COMMENT 'BD名称',
`exclude_reason_id` bigint(20) DEFAULT '0' COMMENT '排除原因(不参与计算的原因,默认为0参与计算)dim.dim_performance_order_exclude_info.exclude_type=1 对应的ID',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`) /*T![clustered_index] CLUSTERED */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin AUTO_INCREMENT=992110 COMMENT='绩效系统-业务订单模型'
然后我通过以下操作,分别进行了测试,结果如下:
15(表名后缀,每个版本加1): 326.689s 原表操作时间
15_2: 337.044s (比15)多了一列 doctor_user_id bigint(20)
15_3: 7.767s (比15_2)`confirmed_amount` 由原来的 decimal(20,2) 改成了 decimal(20,4)
15_4: 19.237s (比15_3)加了各种索引和唯一建约束
15_5: 6.952s `confirmed_amount` 由原来的 decimal(20,2) 改成了 decimal(20,4)
15_6: 7.139s 删除了时间列(create_time + update_time)
15_7: 5.949s 删除了时间列(create_time + update_time) + `confirmed_amount` 由原来的 decimal(20,2) 改成了 decimal(20,4)
15_8: 189.192s 删除了update_time 列
15_9: 202.397s 删除了create_time 列
注:表格中的每次tab表示该表对上表的修改
===================== 分割线 =======================
能看到如下结果:
- 单独删除两个时间列能加速操作(你已告知)
- 单独修改confirmed_amount 的decimal 格式能加速操作
- 加列、加索引和约束会减速操作
===================== 分割线 =======================
结论分析和疑问:
-
对于上述结论1,可能是因为时间列的不断获取时间导致? 但是最后的数据我看了下,第一条和最后一条的时间是一样的,虽然总sql操作时间远大于1秒,但是为啥头尾数据时间列的数值一样? 这似乎跟耗时原因的猜想不一致?
-
对于上述结论2,我仔细看了下操作的sql,其中有个问题:
select ....
order_amt `order_amount`,
recipe_drug_amount `drug_amount`,
IF(biz.id=9,recipe_drug_amount,order_amt)`confirmed_amount`, ...
以上sql中的 order_amount 和 drug_amount 两列都是decimal(20,4) ,而confirmed_amount 的格式是 decimal(20,2) ,所以耗时会不会因为 格式的转换和截断?(不知道之前我提交的debug信息里怎么查这个问题?)
- 对于结论3,似乎本来就是该这样,没啥好说的。
===================== 分割线 =======================
还请各位大神一起帮忙看看再分析分析?
是不是有warning? 要多给点运行时候的堆栈信息
参考:PolarDB-X、OceanBase、CockroachDB、TiDB二级索引写入性能测评 - 知乎
其它的需要看堆栈信息才行。
这个是因为在取current time的时候都是用的session 级别的当前时间的变量,语句执行时候set,整个语句中时间都是不变的,不管你执行多久,每次获取的时间都是同一个时间。
1 个赞
我执行了一次,记录了前两分钟的详细信息:
profile_2022-10-24_19-22-00.zip (4.8 MB)
profile_2022-10-24_19-22-00 (1).zip (4.8 MB)
话说,这个截图里,红框的为啥就是慢操作? 也没写耗时啥的,怎么判断这些都是慢的记录?
因为正常情况下十几秒就完成了,你搜集数据时候一般是在异常情况下的逻辑。极大概率走在了缓慢的逻辑里面,所以猜测是那个问题。
看了下你的profile,在获取默认时间的逻辑里面,每次都有warning,是产生warning的时间拖慢了整体时间。
所以你要看看为何会产生warning,看下tidb的日志或者倒入一部分的数据看看是否有warning产生。
1 个赞
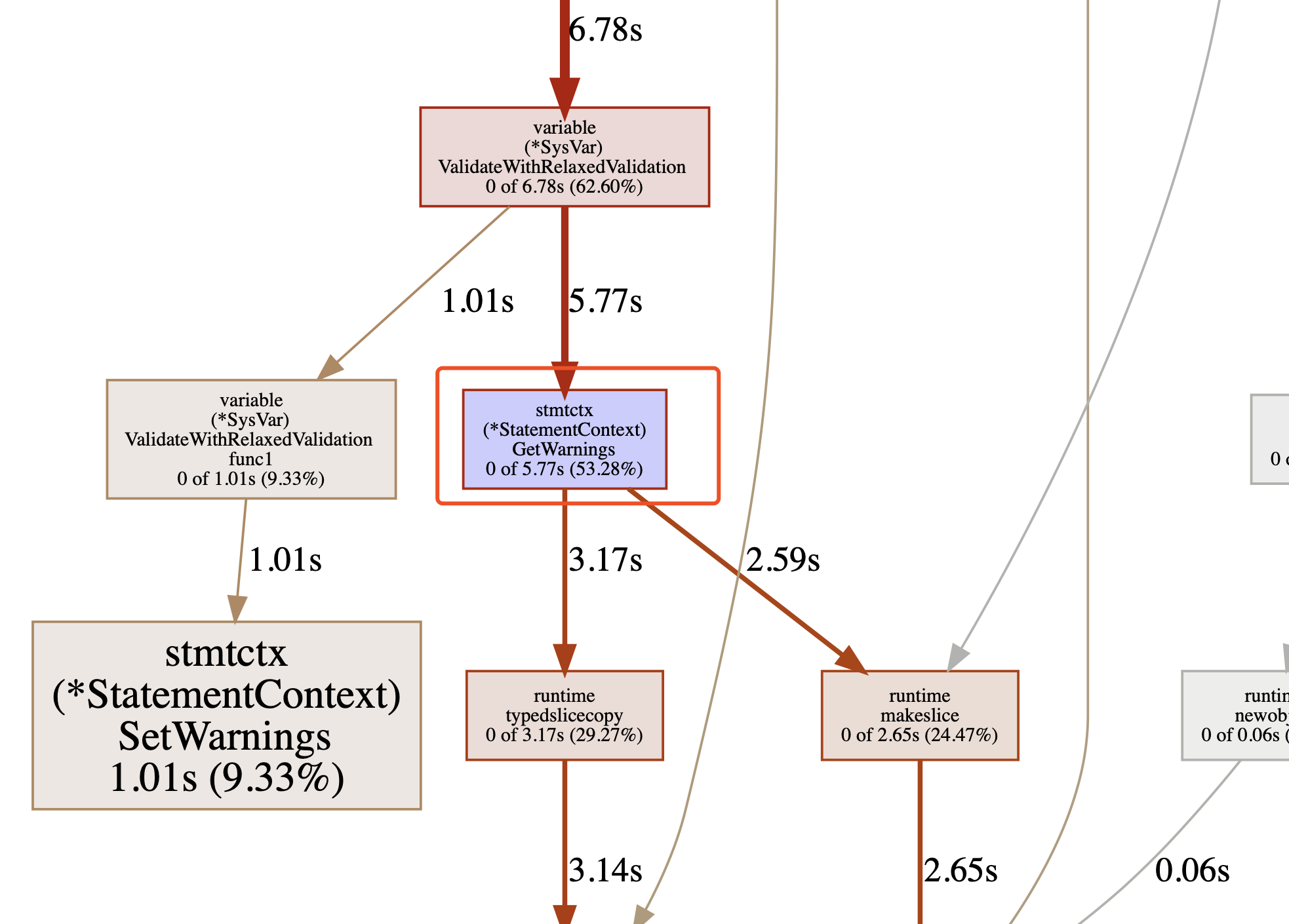
你这个问题的根本原因是decimal数据类型转换的问题(下图2),每次decimal数据类型转换就会在当前session的stmtctx记录当前语句执行的warning,不停的append。与此同时获取自动系统时间的逻辑(下图1代码),对于每行记录获取时间的逻辑里面都需要get warning然后set warning。因此自动获取时间的逻辑是被害者,主要warning的缔造者是decimal数据类型转换!
但是为何自动获取当前时间逻辑里面每次校验都需要跑一次warning的get 和set,这个我不清楚,也许并不需要这个逻辑,你可以去github上提一个issue问一问。
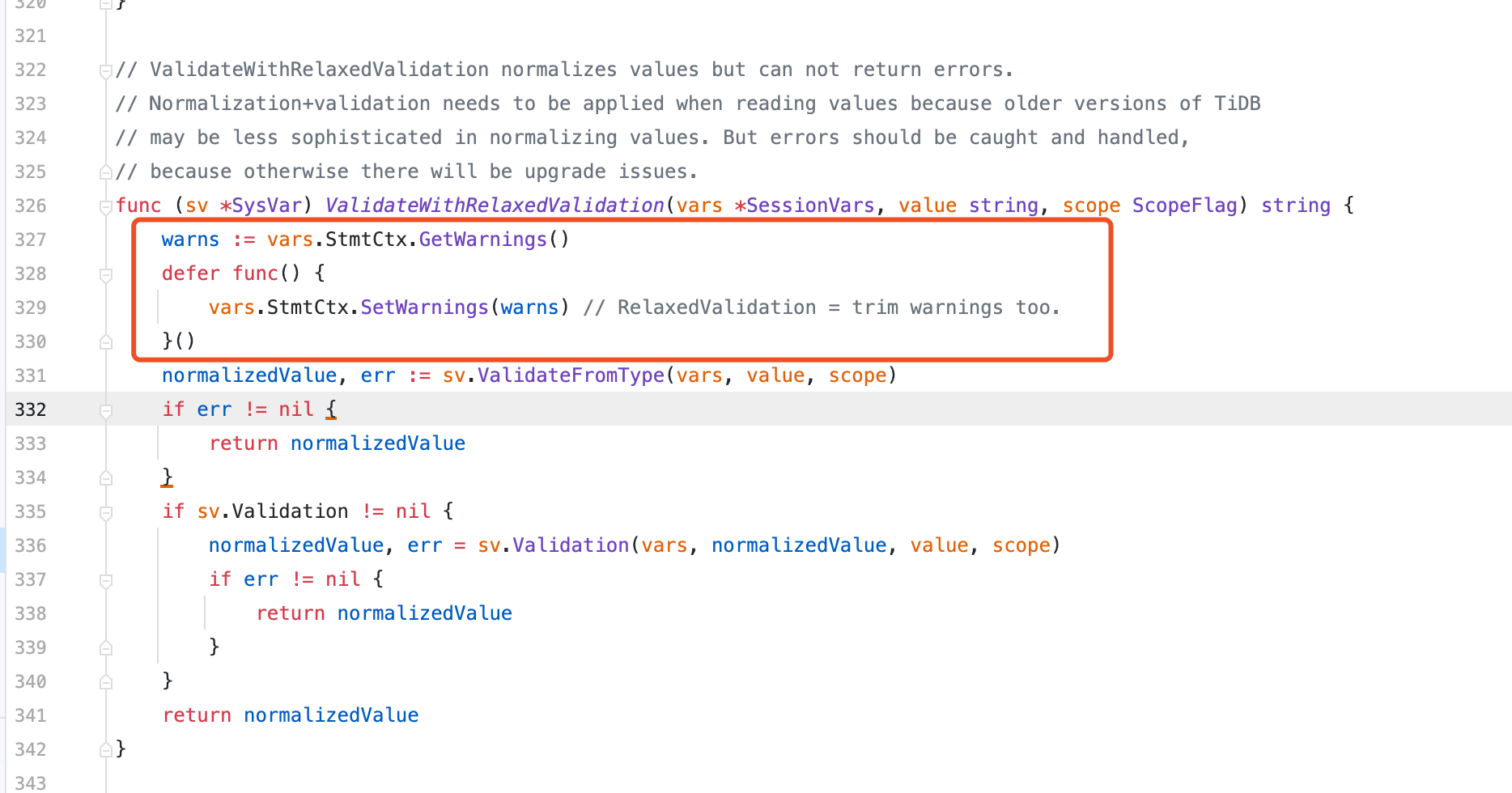

1 个赞
至于为何limit 1000不会很慢,以及去掉两个自动获取当前时间的字段也不会变慢。我想是因为在decimal转换过程中发生截断(或者其它不兼容问题)的记录行数并不是很多导致的。因此自己进一步分析到底哪些数据发生了精读丢失产生了warning。
膜拜!第一次提问题帖子,就遇到了认真负责的大神网友~ 谢谢你的热心解答!
我看您贴出来的执行计划,发现慢的部分主要在这一步:
└─HashJoin_27 root 229646.66 inner join, equal:[eq(dim.dim_performance_business.id, Column#185)] 183647 time:159.9ms, loops:181, build_hash_table:{total:10.2ms, fetch:10.2ms, build:14.1μs}, probe:{concurrency:5, total:21m48.1s, max:4m26.7s, probe:21m46.2s, fetch:1.87s} 41.9 KB 0 Bytes
我觉得问题应该出在:如下部分的动态关联上
JOIN dim.dim_performance_business biz ON biz.id = CASE
WHEN b.source = 8 THEN 8 – 协定方
WHEN b.source<>8 AND b.drug_type=1 THEN 10 – 西药
WHEN b.source<>8 AND b.drug_type=2 THEN 9 – 中药
WHEN b.source<>8 AND b.drug_type=3 THEN 11 END
谢谢回答,不过测试出来是以上讨论的内容,一个decimal字段 和 时间列。