一般来说,用like查询大量数据时,就代表数据库设计不合理
假设集群只有两台kv(kv1,kv2) 并处于初始状态无任何数据,现在有两个客户端准备写入数据,client1写123,client2写456,最终kv1,kv2的存储状态是我图里画的吗(假设路由规则就是图中所画)
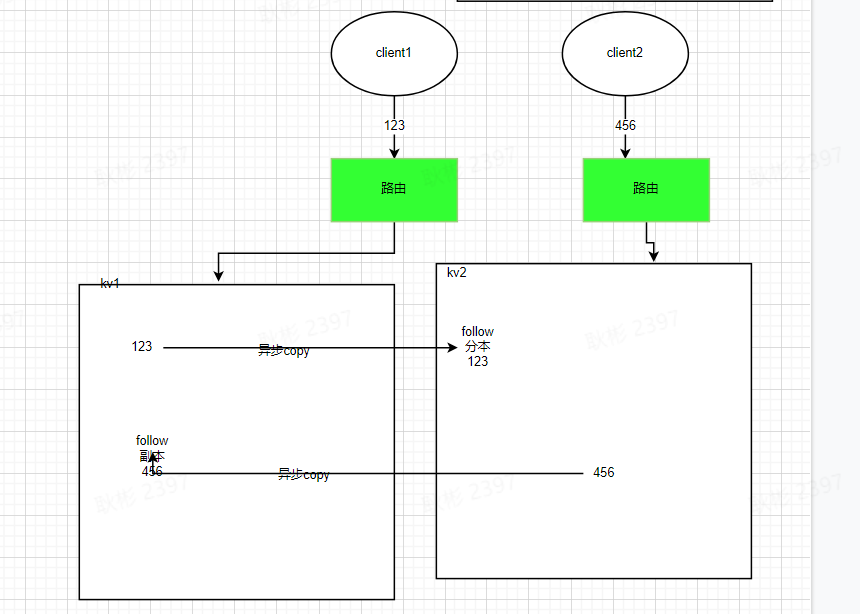
很抽象很抽象的说,是这样的。
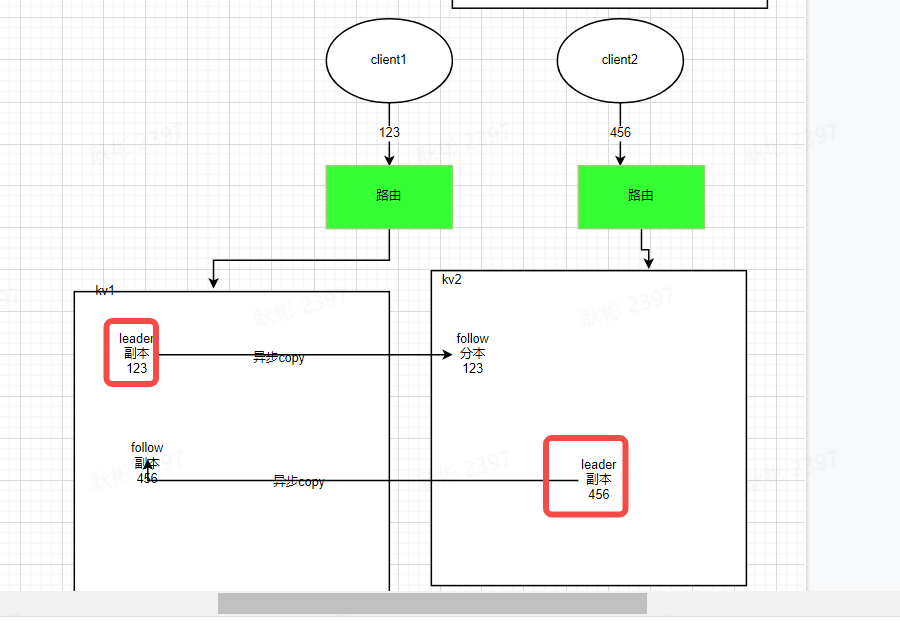
概念上是对的。
你担心的是并发写入吧,可以看看这个文章。
https://docs.pingcap.com/zh/tidb/stable/high-concurrency-best-practices#tidb-高并发写入场景最佳实践
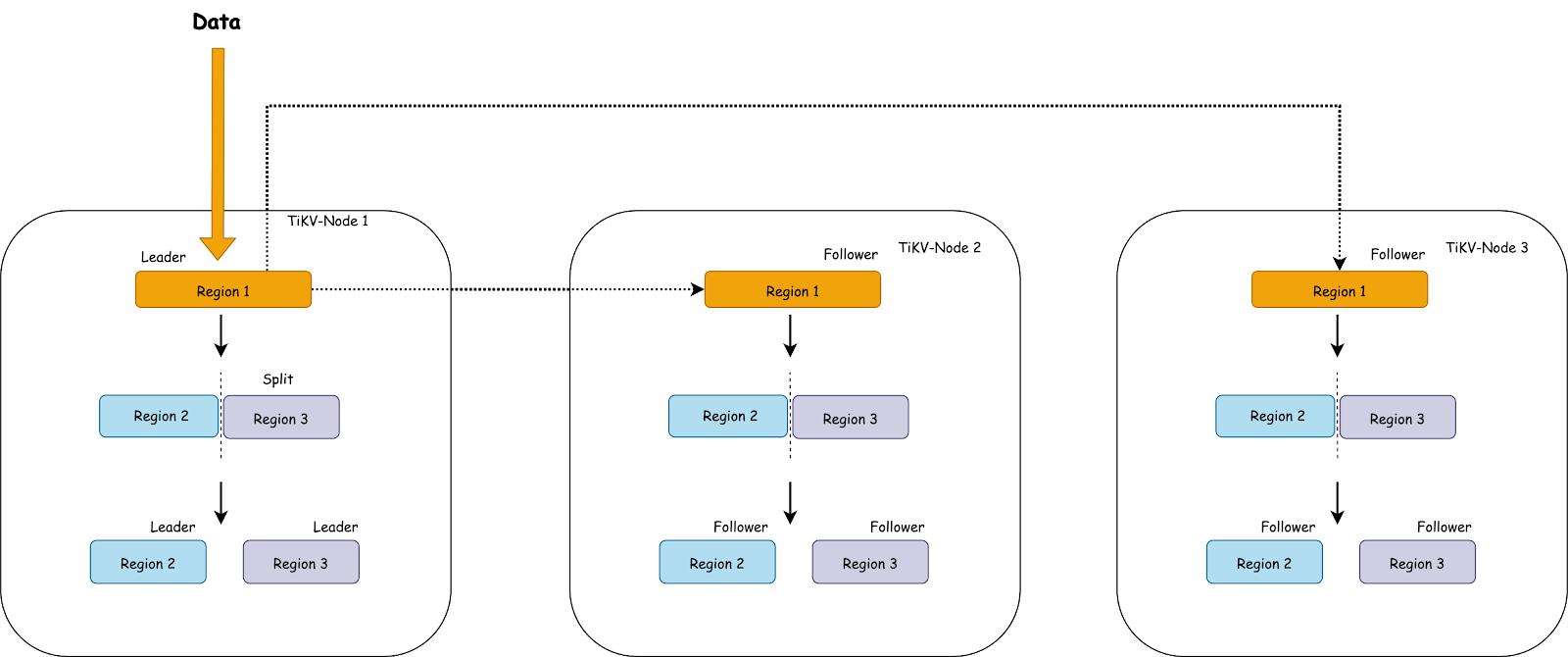
这里有相关的视频课程可以看一下
https://learn.pingcap.com/learner/player/120012;id=120012;classroomId=9;rcoId=630198;courseDetailId=120005;learnerAttemptId=1664510182640
想明确两个问题:1数据的写入会根据tidb节点的内部规则分发到不同的kv节点上。
2如果1正确,那每台都有leader副本,每台的leader副本加follow副本的完整数据是一摸一样的。
这两点结论对吗
是的,最小集群是3个tikv,3副本。假设完整数据有300,那正常情况下,每个tikv上有100的leader副本和200follower副本。每个tikv上的follow副本和其他两个节点加起来的leader副本数据一致。
好的,谢谢
我看有篇文章是写follower读的,https://docs.pingcap.com/zh/tidb/stable/follower-read,文章提到开启follower Read,follower副本才会承担负载,如果不开启(默认是不开启的吗),那么读只会到leader,是这样吗
是这样的