有极个别表是单副本的,所以紧急扩容了一台(pd应该会向该节点调度那些单副本的吧),防止生产访问出错,然后现在在做下线处理,目前已经下线3个小时了还没下线掉。。。
如果可以一台一台来操作那是可以接受的
有极个别表是单副本的,所以紧急扩容了一台(pd应该会向该节点调度那些单副本的吧),防止生产访问出错,然后现在在做下线处理,目前已经下线3个小时了还没下线掉。。。
如果可以一台一台来操作那是可以接受的
我们会在4.0.15、5.0.5、5.1.2版本修复此问题,请适时升级。
v4.0.12 后的版本,可以使用下面的命令,来查看 Region 副本补充的进度。
如果已经补好 Region 副本,会打印出 True。如果还没有补好,会打印出 False 以及具体各个表的进度。
<tiflash_deploy_dir>/bin/tiflash/flash_cluster_manager/flash_cluster_manager --config <tiflash_deploy_dir>/conf/tiflash.toml --check_online_update
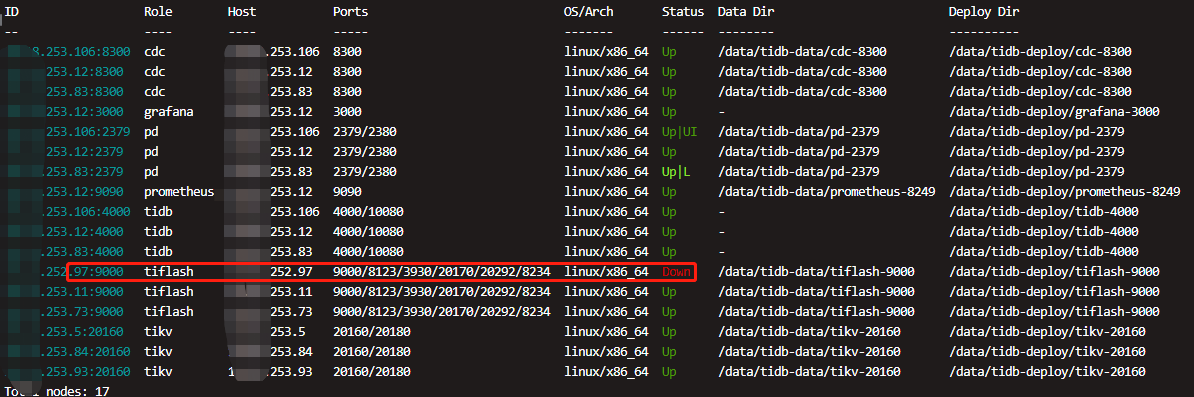
我上午进行了下线处理,然后 --force移除出去了,后来又扩容回来了,使用tiup看一切正常,我看着副本数一直在同步,后来突然出现一个问题,dashboard上出现两个一样的tiflash节点(就是这个扩容后又缩容的节点),使用tiup看该节点是down状态,去该机器看,就一个tiflash进程
使用 --force 移除出去之后,然后是以相同的 IP、端口重新扩容了 TiFlash 节点么?可以使用下面的命令,确认下 PD 上 store 的信息
tiup ctl:v4.0.13 pd -u <pd-ip>:<pd-port> store --jq='.stores[].store | select(.labels | length>0 and contains([{"key":"engine","value":"tiflash"}])) | { id, address, state_name}'
是的,在同一节点又扩回来了,因为之前起不来,只能先把他remove后,再扩回来
执行后报错:
exec: “jq”: executable file not found in $PATH
执行后报错:
exec: “jq”: executable file not found in $PATH
https://stedolan.github.io/jq/download/
需要下载一个 jq 的二进制,放到 tiup 中控机的 PATH 路径对应的目录中
是的,在同一节点又扩回来了
在之前的节点在 PD 中还没完全清理相应的 store 以及上面的 peer 之前,以相同的 IP、端口重新上线,估计触发了一些 bug。。
请问目前副本还是能够一直同步吗?对线上的查询有影响吗?
这个问题应该是bug导致pd的脏store数据又出现了。。。
之前是清理了的,并且监控和tiup看都是正常的,不过我又pd remove了下是正常了
大佬你看这个帖子, tiflash 表tombstone
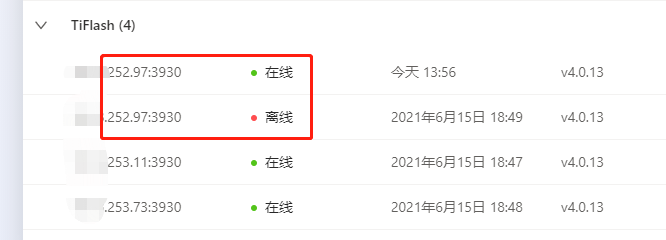
我感觉是衍生出来的问题,扩缩容tiflash后,grafana显示有两个僵尸store,我pd store查看是正常的6个,remove-tombstone 返回success,但grafana上还是显示tombstone,而且我有两个tiflash表,也显示tombstone,并且我吧这个表取消tiflash,再重新同步过来,都还是tombstone
没有使用多盘部署
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。