- 两个监控的时间对不上。麻烦取一下 detail-tikv 的时间段,注意上面可以选择 tikv ,每个tikv都反馈下。

1 个赞
sorry,刚才时间选的是三个异常时间段中的一个。
完整时间的已经上传了,还是刚才的地址。
1 个赞
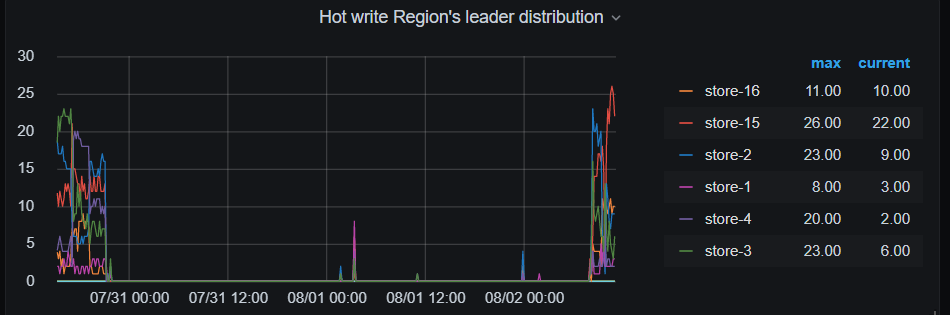
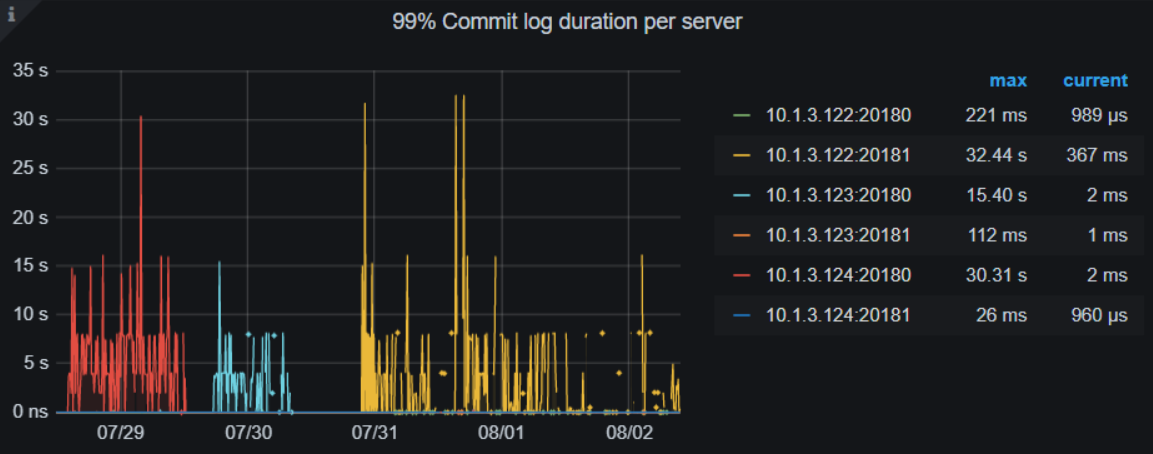
- 看了下磁盘write latency,没有和 commit log 能够完全匹配上的时间,有一些时候,latency 比较慢。
- 根据有热点写入 和 commit log 时间长,可以参考文档先调大参数 [raftstore] raft-max-inflight-msgs 试试
- tidb.log 中存在 async commit cannot proceed since the returned minCommitTS is zero, fallback to normal path, tikv.log 中存在 commit_ts is too large, fallback to normal 2PC。也需要继续查看,后面会反馈,先试试调整参数,多谢。
1 个赞
我们已经把matomo迁走了,无法复现这个现象了![]() 。毕竟线上环境,经常出问题挺麻烦的。
。毕竟线上环境,经常出问题挺麻烦的。
1 个赞
抱歉,再请教下,您的系统是云上的吗? 还是物理机?
1 个赞
物理机。
cpu:Intel® Xeon® Silver 4214R CPU @ 2.40GHz
内存:256G
硬盘:3T nvme * 2
1 个赞
好的,感谢。补充下,这种问题也可以调大参数 scheduler-pending-write-threshold、raft_client_queue_size 来尝试解决。
1 个赞
我把matomo存储后端迁到tidb on k8s 版本 v4.0.10。没有配置tiflash副本。至今一周多了,没有出现问题。
有问题的是tidbv5.1.0版本,是裸机部署,对于matomo的表开启了tiflash副本。
是不是版本的问题啊,或者tiflash的问题?
- 是上次出问题迁移走后,又迁移到了 tidb on k8s v4.0.10 ? 业务是相同的压力?
- 拓扑是怎么样的? 是使用的公有云,还是同样的物理机上部署的 tidb-operator?
cpu:Intel® Xeon® Silver 4214R CPU @ 2.40GHz
内存:256G
硬盘:3T nvme * 2
1.上次出问题就直接迁到了tidb on k8s,至今已经一周了,没出现问题。
2.不是公有云,是相同配置的物理机上部署的k8s集群,然后用的tidb-operator部署的tidb
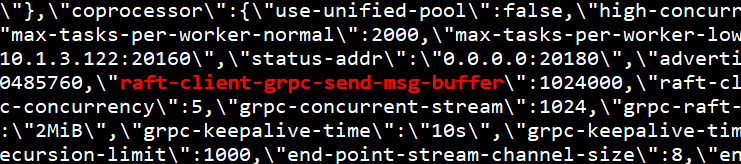
感谢,这个问题根据日志看是 batch 太大导致连接断掉了,因为 5.0 对 raft client 进行了重构,batch 效率更好,造成超出限制。5.1 版本可以修改参数 tikv.server.raft-client-grpc-send-msg-buffer,测试默认值已经很少有这种情况了,如果实在发生了,可以调整参数值为 1024000
[2021/07/30 21:03:37.275 +08:00] [ERROR] [raft_client.rs:412] ["connection aborted"] [addr=10.1.3.123:20160] [receiver_err="Some(RpcFailure(RpcStatus { code: 8-RESOURCE_EXHAUSTED, message: \"Sent message larger than max (12250505 vs. 1048
5760)\", details: [] }))"] [sink_error=Some(RemoteStopped)] [store_id=2]

不是,这个参数不在模板里,就是我发的那个
还是不行,这次我是用spark读取csv写入tidb,然后也是报这个scheduler is busy。
相同数据写入tidb v4.0.10正常,写入v5.1.0就报错
- 和之前的问题一样吗? 监控和日志是同样的问题?
- 请查看 tikv.log 日志,配置的参数是否生效,多谢。
麻烦检查下 tikv.log 日志,有这样的报错信息吗?如果没有,可能不是相同的问题
[2021/07/30 21:03:37.275 +08:00] [ERROR] [raft_client.rs:412] [“connection aborted”] [addr=10.1.3.123:20160] [receiver_err=“Some(RpcFailure(RpcStatus { code: 8-RESOURCE_EXHAUSTED, message: “Sent message larger than max (12250505 vs. 1048
5760)”, details: [] }))”] [sink_error=Some(RemoteStopped)] [store_id=2]
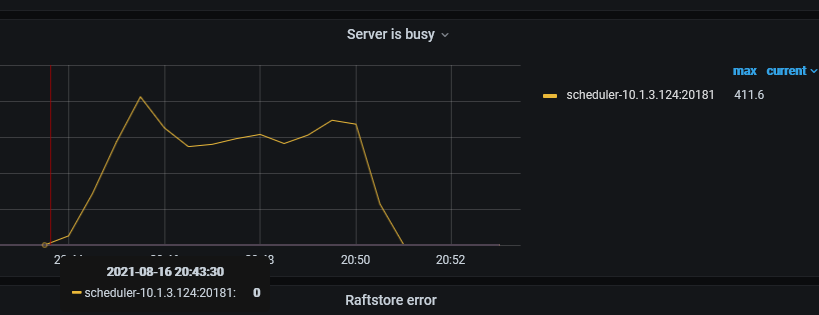
- 麻烦帮忙先确认几个问题,当前的集群和一开始反馈的问题是同一个业务? 之前是业务上有问题,现在还有吗?
- 第二次这个问题是,spark 读取 csv 文件 报错 scheduler is busy。如果不导入文件,业务无影响?
- 重复数据是什么问题? 和这个是一个集群吗? 所有的问题都只有一个集群对吗?