为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
测试
【概述】场景+问题概述
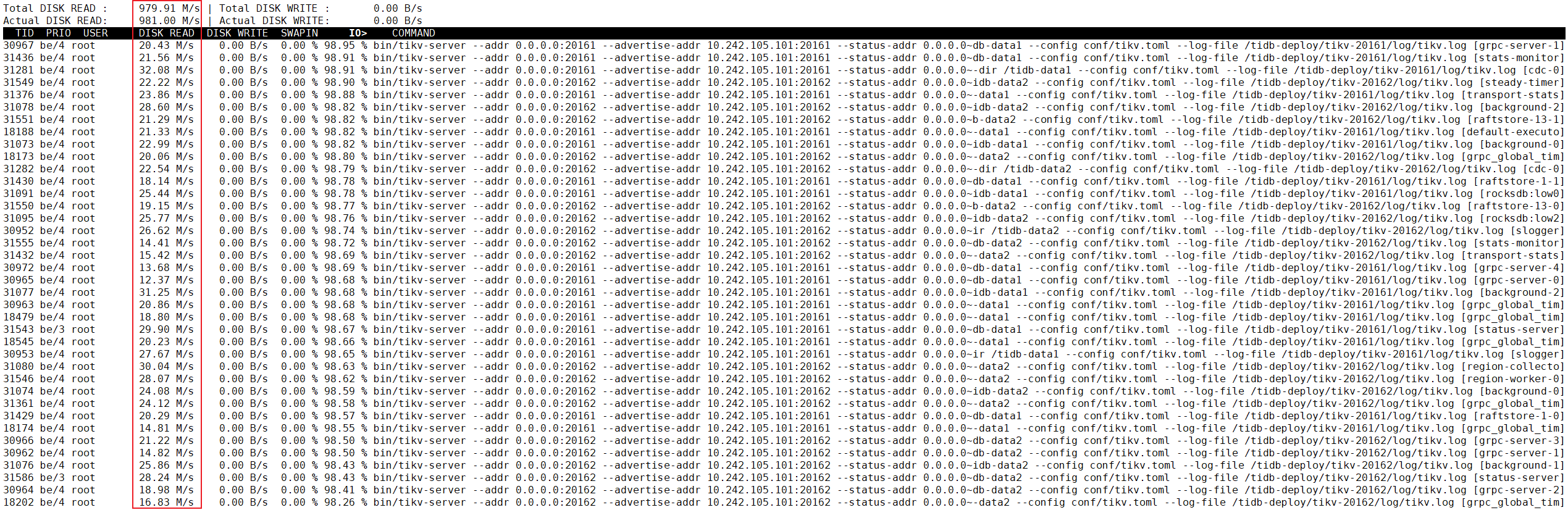
tikv服务进程有单独的数据盘。但是出现了系统盘疯狂Read的操作 很怪异
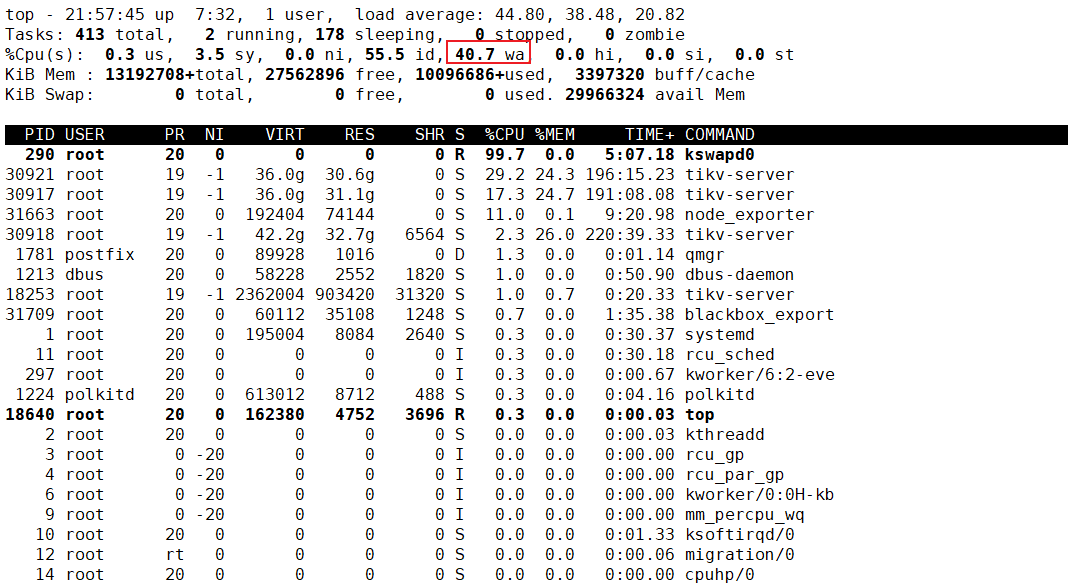
我没有swap 空间。kswapd0 完全占用了一个CPU,他在释放内存,不过当时内存确实用了98%。不过感觉这跟系统盘 Read IO严重没什么关系啊。
【背景】做过哪些操作
做了个sysbench oltp_update_index 压测,然后tps个位数,就终止了
【现象】业务和数据库现象
strace -T -tt -e trace=file -p 30921 -ff 当时去看没抓到什么有用的信息
半小时之后自动恢复了,内存有所回落。
【业务影响】
无
【TiDB 版本】
【附件】
-
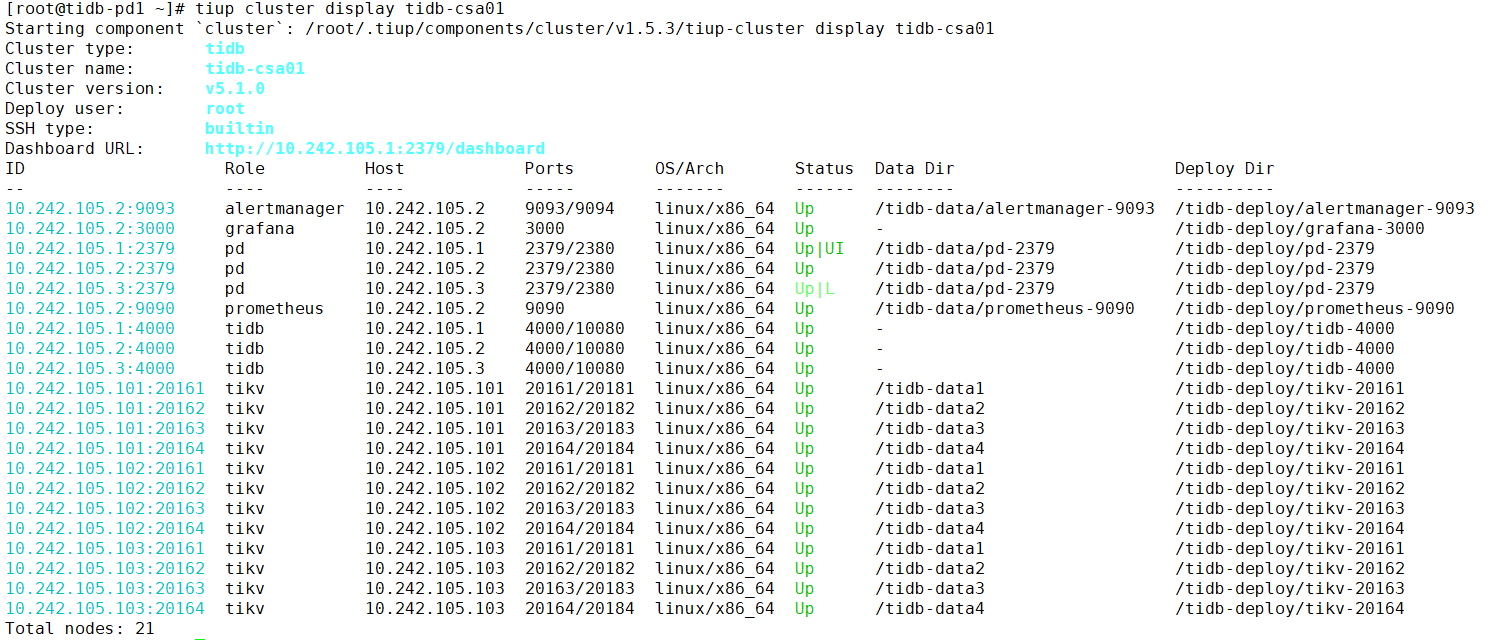
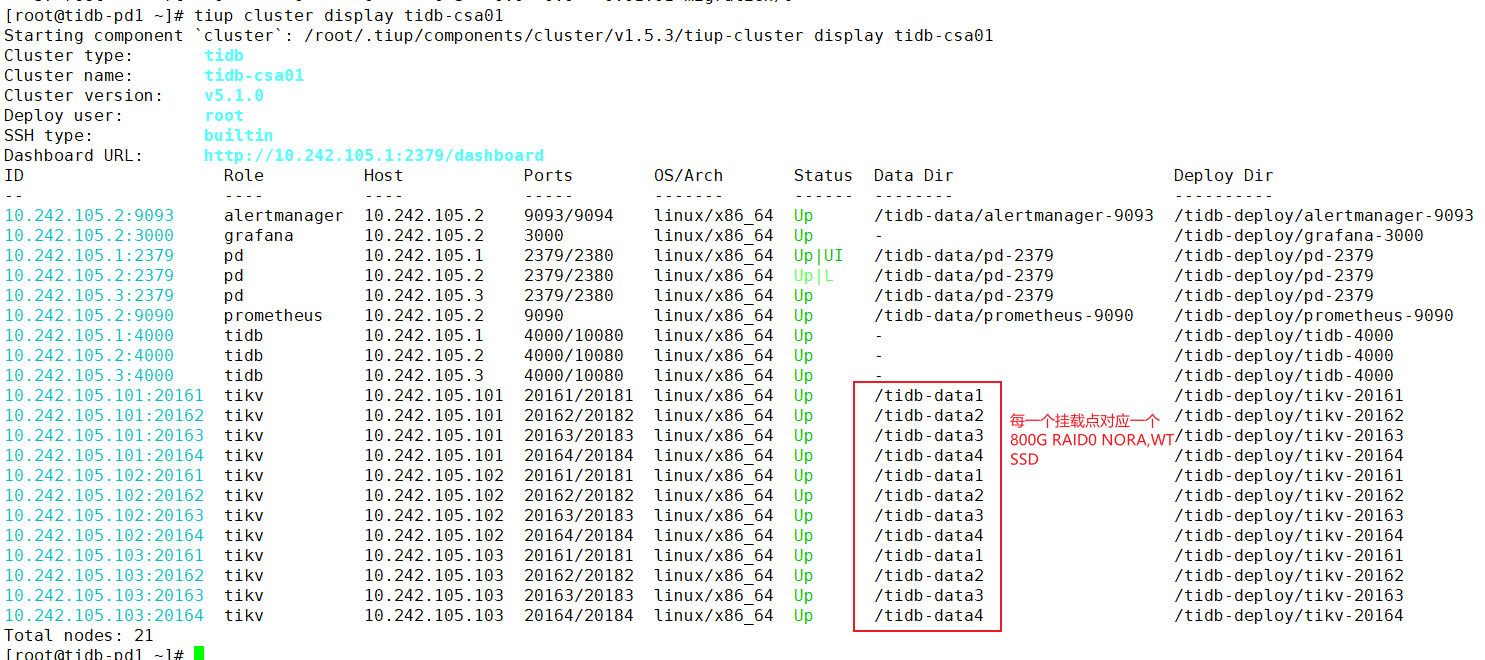
TiUP Cluster Display 信息
-
TiUP Cluster Edit Config 信息
-
TiDB- Overview 监控
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
1 个赞
xfworld
(魔幻之翼)
2
发现kswapd0进程cpu占用一直居高不下,于是查询资料,总结如下:
这个东东就是SWAP 的交换区标记,
swap分区的作用是当物理内存不足时,会将一部分硬盘当做虚拟内存来使用。
kswapd0 占用过高是因为 物理内存不足,使用swap分区与内存换页操作交换数据,导致CPU占用过高。
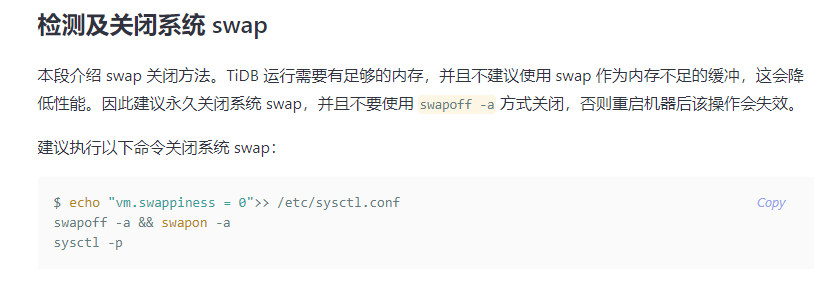
官方文档的配置信息中明确需要关闭 SWAP,以免造成性能问题:
建议关闭后,在进行测试
参考链接:
https://docs.pingcap.com/zh/tidb/stable/check-before-deployment#检测及关闭系统-swap
额。。。swap本身 我物理机就没配。我也不用swapoff 当初按系统的时候 swap就没分区。
Lucien
( Lucien)
4
是虚拟机么 ? 底层磁盘是什么类型的,采用的 RAID 多少/
不是虚拟机。是物理机。
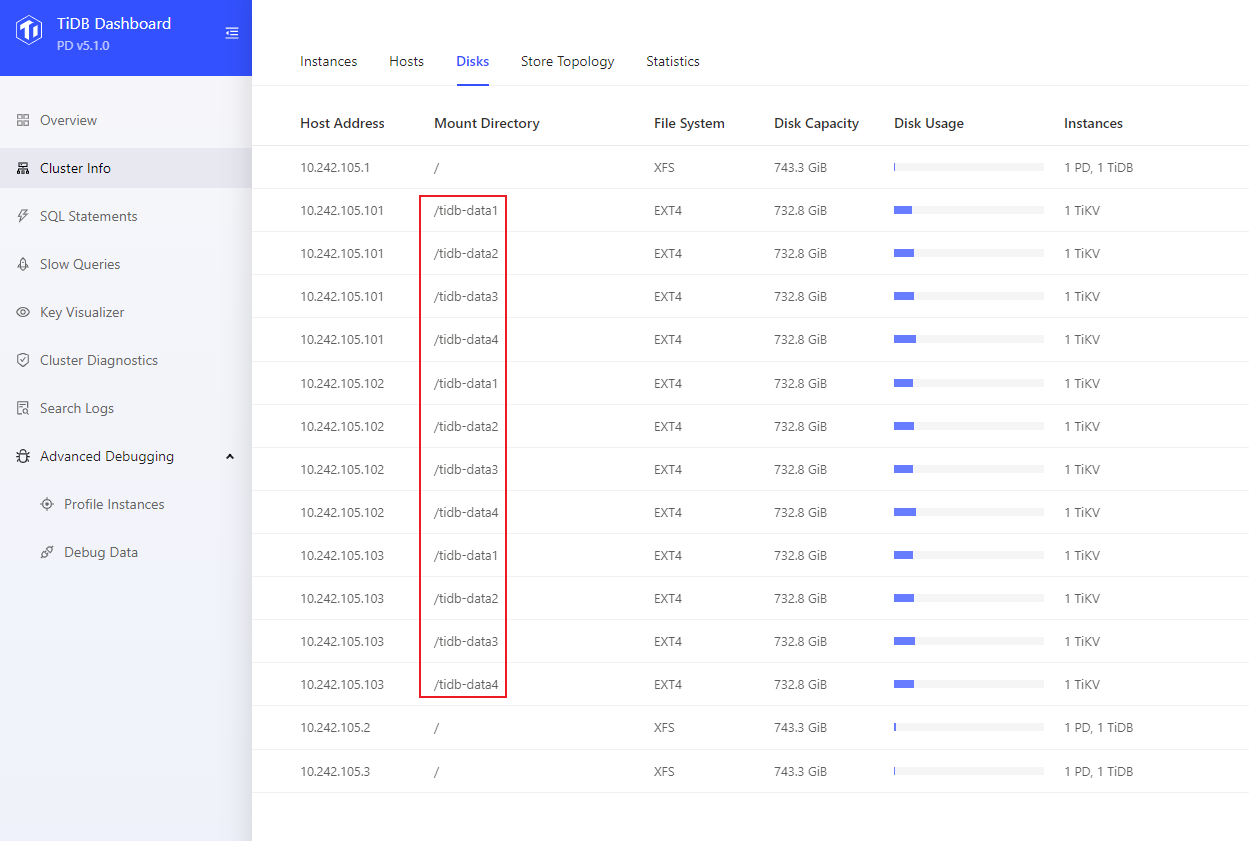
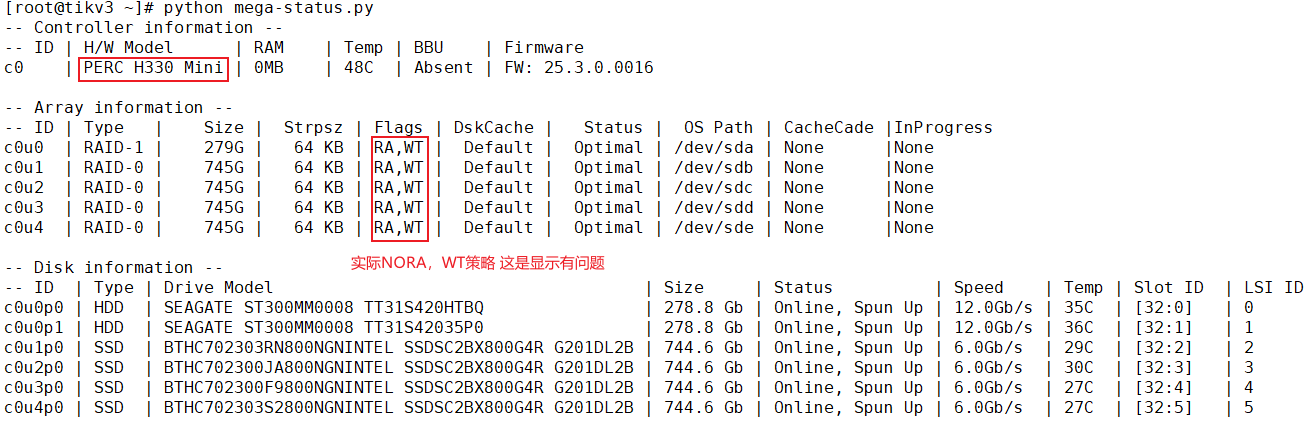
磁盘类型是ssd
raid0 NORA WT策略
Lucien
( Lucien)
6
Hi ~ @centosredhat 可不可以提供一下 Grafana 监控,使用 metrictools 的导出一下 TiKV-details 和 TiDB
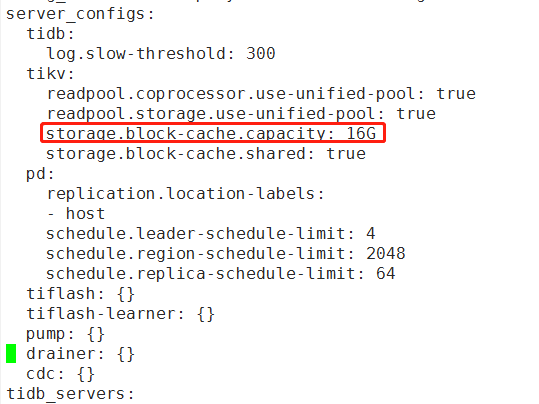
后来他自动恢复了。是我设置的问题
storage.block-cache.capacity: 16G
这个配置,未设置,设置了之后再没出现过问题。
1 个赞
system
(system)
关闭
8
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。